Просмотров: 49800
Дата последнего изменения: 17.01.2024
Сложность урока:
4 уровень - сложно, требуется сосредоточиться, внимание деталям и точному следованию инструкции.
5
Организация системы мониторинга
Несколько принципов организации системы мониторинга:
- Лучше использовать стандартные решения (Nagios, Zabbix и т.п.), а не самописные. Собственная система - это долго и дорого. Лучше потратить время на изучение какой-то стандартной системы и научиться писать к ней плагины, чем разрабатывать свою. Самописные системы тяжело развивать, особенно новым сотрудникам, не принимавшим участие в её создании. Такие системы сложно кастомизировать под возникающие новые ситуации.
- Система мониторинга не имеет смысла без организации дежурных смен (и/или мгновенных уведомлений администратору) для устранения проблем.
- Мониторить нужно по максимуму, в идеале: всё. Загрузку процессоров, дисков, памяти, а также какие-то специфичные метрики, которые вы определили для своего приложения. В том числе и нестандартные вещи: домены, сертификаты, баланс sms.
- Но мониторить нужно аккуратно. Тысячи уведомлений будут бесполезны, более того, в потоке некритичных уведомлений можно легко пропустить то единственное, от которого жизненно зависит работа проекта. Правило должно быть таким: пришло уведомление - значит серьёзная проблема или авария.
- Автоматизация типовых реакций. Например, кончается место, надо пойти очистить какую-то типовую папочку. Это можно автоматизировать и нужно стремиться автоматизировать такие некритичные рутинные операции. В Nagios, например, есть event handler, который по срабатыванию определённых уведомлений даёт команду на выполнение каких-то действий.
- Нужна распределённая система мониторинга, которая может мониторить и саму себя. Если сама система мониторинга отвалится, уведомлений нет, вы считаете что всё хорошо. А на самом деле проект - "лежит". Либо две системы мониторинга: одна мониторит одну часть проекта, вторая - другую, и каждая из них мониторит другую систему мониторинга.
Нужно научиться оценивать как проект работает. Есть много внешних инструментов мониторинга работы проекта в режиме реального времени. Они могут быть очень точными, они могут собирать много информации, но они все работают "снаружи" проекта и показывают симптомы, а не причины.
Полноценные данные с пониманием всех происходящих процессов может дать только само веб-приложение. Для этого нужно научиться мониторить процессы средствами ядра продукта и платформы, которая используется в приложении.
Мониторинг железа
Собственный сервер нуждается в постоянном контроле за его комплектующими. Можно разделить контроль по видам ресурсов: Критический и важный. Критический - это те, сбой которых гарантировано приведёт к отказу бизнес-приложения. Важные ресурсы - это те, наблюдение за которыми позволит предсказать возникновение проблем.
Критические ресурсы:
- CPU;
- Memory;
- Пропускная способность дисков и сами диски;
- Traffic к серверу.
Важные ресурсы:
- RAID status.
- S.M.A.R.T. - вероятность выхода дисков из строя.
- IOPS - анализ количества операция с дисками в секунду.
- Disk avio - среднее время ответа на запрос к нему. Если avio равно примерно 10 мс, то пора задуматься о замене дисков.
- Sockets - количество используемых сокетов на сервере.
- CPU temperature.
- CPU fan speed.
Чем мониторить?
- Рейды проверяются аппаратными или программными средствами.
- Жёсткие диски контролируются SMART-утилитами, которые не являются панацеей, но достаточно надёжное средство прогнозирования состояния диска.
- Для контроля остальных комплектующих есть аппаратные средства контроля от вендора сервера. Это, как правило, небольшая устанавливаемая на сервере плата позволяющая оценивать его состояние.
Мониторинг ПО
Мониторинг самой ОС выполняется по следующим параметрам:
- Место на дисках. Банально, но это реальная проблема отслеживания свободного места для высоконагруженного проекта, особенно при размещении в облаке. Проблема решается достаточно просто с помощью плагина от Nagios.
- Периодическая проверка файловой системы - fsck. Журналирование не всегда спасает.
- Периодическая проверка бекапов на читаемость.
- Нагрузка на диск. Рекомендуется использовать iostat. Полезные данные в колонке %util: показывает насколько устройство загружено. Если около 100%, то диск перегружен, либо выходит из строя. Кроме того можно посмотреть насколько хорошо файловая система работает с потоками. Можно ли одновременно работать с диском и с RAID. Если ОС стоит старая, то всё может работать в один поток, а вы не знаете.
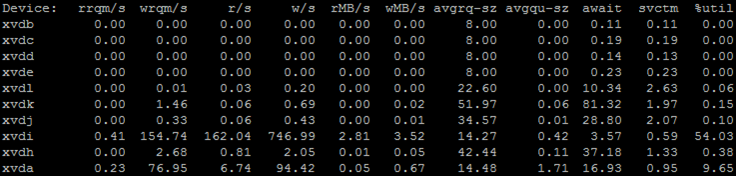
- Очередь выполнения: число процессов, которые хотят быть выполненными центральным процессором. Если их много, то что-то не так: или сервер слабый или софта много запускается или что-то не так в настройках. Контролируется с помощью того же Nagios.
- Размер и использование swap. Надо проверять объём самого swap'а, количество свободного места на нём. Swap - это защитный механизм ОС, если система "вываливается" в swap (то есть из оперативной памяти программы выгружаются на жёсткий диск), то это плохо, так система начнёт тормозить. Контролируется это с помощью того же Nagios. Решение: увеличить объём оперативной памяти.
- Процессы. Рекомендуется использовать vmstat. С её помощью можно отследить число процессов работающих, число непрерываемых процессов (процессы, которые "зависли" на диске либо в сети). Если процессор свободен, а процессы висят, то это означает, что не хватает дисковой мощности.

Полезна представляемая vmstat'ом информация о памяти, которая в Unix системах устроена не просто. В этих системах просто нет свободной памяти, она вся занимается под буфер и кеш. То есть не стоит опасаться малых значений в колонке free. Но должны беспокоить малые значения в колонках buff и cache - это означает, что система не умещается в памяти., нужны изменения в конфигурации.
Полезно контролировать колонку st: наличие в ней значений, отличных от 0 говорит о том, что другая виртуальная машина потребляет время вашего процессора. Ваша виртуальная машина в этом случае будет тормозить. К сожалению, виртуализация может иногда "красть" ваши процессорные ресурсы. Это актуально для облачного размещения.
При мониторинге серверного ПО обратите внимание на:
- для NGINX: RPS (Read Per Seconds) - самая важная характеристика: количество запросов к сайту в секунду.
- для PHP-FPM: RPS, количество активных процессов, количество сообщений об достижении лимита процессов.
- для Sphinx: количество поступающих запросов, отслеживание Fatal Error
В мониторинге MySQL надо тестировать:
- Число работающих потоков (Mysql threads running). Каждый поток занимает какой-то объём оперативной памяти, ресурсы процессора. Если их слишком много, то система начнёт тормозить. Нужно следить чтобы процессор был не перегружен.
- Число медленных запросов (Mysql slow queries). Если БД тормозит, этот параметр нужно проверять в первую очередь. Медленные запросы могут возникать по разным причинам, но если они появляются - это, скорее всего, плохо и надо предпринимать меры.
- Долгие процессы (Mysql long procs). Программисты могут создавать и запускать для своих целей долгие процессы, которые длятся сутки и более. Это бывает причиной перегрузки процессора, а тесты позволяют выловить такие процессы.
- Состояние репликации. Может перезагрузился сервер, система ушла в swap, репликация отстаёт. Стандартный тест Mysql replica позволяет отслеживать отставание и прекращение репликации.
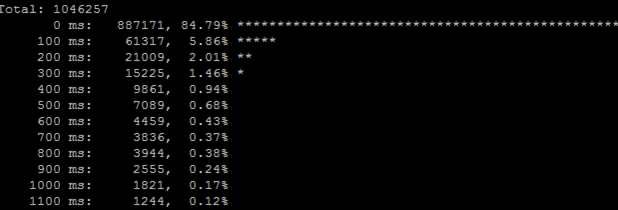
- Гистограмма времени обработки запросов по времени (на примере Percona) позволяет увидеть тормозит или нет сама БД. (В стандартном MySQL этой возможности нет.) Можно выполнить команду, которая строит гистограмму распределения хитов времени исполнения:
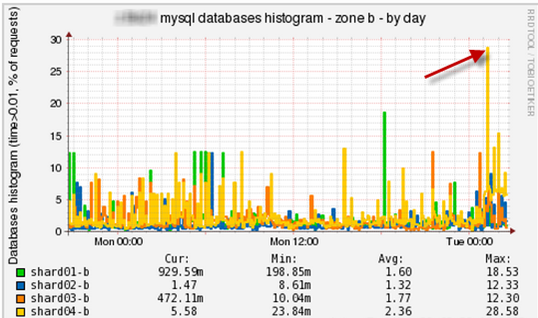
Если вы видите, что запросов больше 0,1 секунды много, то, значит, база тормозит. Для каждого проекта "правильный" график будет свой, в зависимости от задач проекта. В Munin можно создать свой плагин, который будет по базам данным выводить табличку запросов, например, запросов длительностью более 0,1 секунды:

При мониторинге сети очень удобна команда netstat. Она позволяет видеть что у вас в сети: кто висит на memcache, кто на php, кто на MySQL.
Можно также использовать утилиты:
- atop - позволяет сохранять снимки состояния системы с определённым интервалом. Завис сервер ночью. Вы можете с указанным интервалом отследить что присходило в системе (диск, процессор, память, процессы) и произвести "разбор полётов".
- ps - оценивает состояние процессов.
- pstree - команда позволяет увидеть дерево процессов, кто кого "родил".
- apachetop - консольная утилита, позволяющая построить гистограмму времени выполнения запросов (по путям) по логам Apache и NGINX. Без этой утилиты крайне сложно понять как нагрузка на проект распределяется по хитам. Позволяет также отследить ситуации, когда NGINX пропускает запросы статики на Apache.
- innotop - утилита для мониторинга MySQL. Позволяет сократить время для анализа работы БД.
Мониторинг веб-приложения
Для каждого бизнес-скрипта, который обязательно должен выполниться (и, если не выполниться, то сообщить об ошибке) нужно вести лог работы скрипта. Nagios при этом должен следить за обновлением этого лога с заданным интервалом. Если файл не обновился, значит скрипт не отработал.
Кроме лога работы можно вести лог ошибок. В Unix есть поток ошибок, который направляется в другой файл. Этот лог должен быть, в идеале, пустой. Однако в нём могут появляться самые непрогнозируемые данные: например, сторонняя программа убила процесс вашего приложения.
Примечание: При работе с логами обязательно нужно выполнять
logrotate, иначе, если скриптов много, очень скоро ваш диск переполнится.
Необходимо так же мониторить:
- Число ошибок в хитах за 15 минут - меньше L (например, меньше 5).
- Макс. время хита (тэга) - меньше M сек (например, 10).
- Макс. использование памяти хитом - меньше N МБ. Возможны ошибки в приложении, когда скрипт начинает требовать много памяти (500 Мб и более). Если не контролировать расход памяти, система может уйти в swap.
Делается это с помощью Pinba. Если число ошибок превышает указанные значения в этих параметрах, то необходимо уведомлять администратора по SMS.
Для данных тестов полезно написать плагин для Munin, который будет формировать графики по этим параметрам. Например, среднее время выполнения скрипта:
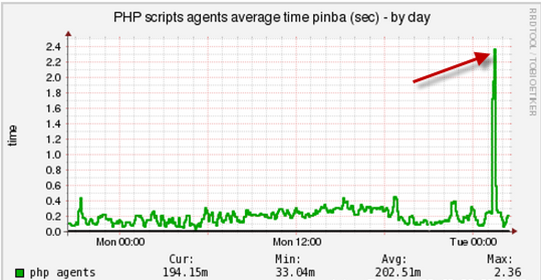
Или, расход скриптами памяти:
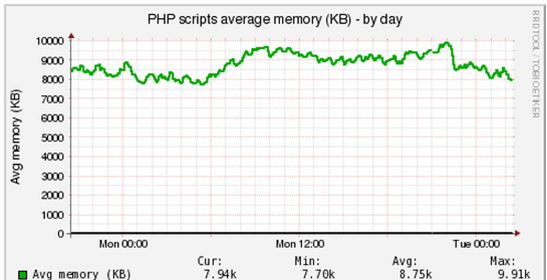
Гистограммы распределения времени хитов, памяти, кодам ответа по времени строятся из логов (awk-скрипт) или Pinba. Смысл этих графиков - визуальное представление состояния вашего приложения: тормозит оно или нет. Например, число запросов с продолжительностью с шагом в 100 ms: