Просмотров: 37375
Дата последнего изменения: 17.01.2024
Сложность урока:
3 уровень - средняя сложность. Необходимо внимание и немного подумать.
4
5
Мониторинг сайта
Можно выделить следующие типы мониторинга самого сайта:
Мониторинг доступности - отслеживание того, работает ли он или нет. Наиболее оптимальным для простого мониторинга является десятиминутный интервал: большинство пользователей попытаются вернуться на сайт в течение 1-2 часов, а за это время можно как обнаружить проблемы, так и эффективно их устранить без особого вреда для бизнеса компании.
Мониторинг проблем - отслеживание нескольких параметров сайта с частотой не менее раза в минуту и из нескольких географических точек (чтобы максимально покрыть минутный интервал проверками и установить возможные проблемы, связанные с географией пользователей).
Среди возможных критериев проверки можно выделить проблемы с:
- DNS-сервером (когда в определенные интервалы времени адрес сайта не может быть определен, хотя сам сайт физически доступен);
- большим временем ответа (при обновлении кэша, например, или при выполнении «тяжелых» задач на стороне сервера);
- плановым выполнением задач (в результате которых сайт будет не доступен только в определенные моменты времени);
- большим времени ожидания статических файлов (например, из-за сетевой инфраструктуры или проблем с физическим носителем);
- подключением к базе данных;
- и т.д.
Этот метод особенно хорош, когда требуется отловить какую-то «плавающую» ошибку, а несколько независимых сервисов либо точек проверки позволяют добиться частоты проверки вплоть до раза в 10 секунд - а это более чем достаточно, чтобы обнаружить все, что необходимо.
Мониторинг может быть не долговременным (до обнаружения и исправления проблем) либо периодическим (в целях профилактики проблем).
Мониторинг работоспособности - сюда может относиться любой сложный функционал, который может быть затронут какими-либо изменениями на сайте, например, кабинет интернет-банка. В этом случае необходимо настраивать цепочки проверок либо задавать сложные условия для проведения проверок того или иного функционала сайта.
Мониторинг распределенных систем
При построении отказоустойчивой распределенной инфраструктуры кроме обеспечения нескольких уровней надежности обычно закладывают и несколько уровней мониторинга системы. Среди них можно выделить:
-
Встроенный мониторинг, выдающий данные о физических параметрах серверов (операции с диском, с памятью, загруженность процессора, сети, системы и т.д.).
В качестве решения часто используется Munin с большим набором плагинов, которые позволяют контролировать каждую проблемную точку. Плагины, по сути, — это консольные скрипты, которые проверяют определенный параметр системы с заданной периодичностью. Теоретически, уже на этом уровне можно использовать триггерный механизм, чтобы проводить "разгружающие" действия с сервером. Но на практике для принятия решений используется следующий уровень мониторинга, встроенный мониторинг используется только для сбора статистики и анализа параметров системы "изнутри".
-
Внутренний мониторинг подразумевает профилактику состояния всей инфраструктуры или ее части на уровне самой инфраструктуры. Это означает, что наряду с рабочими серверами (приложений, базы данных) в системе должны быть сервера, отслеживающие ее состояние и передающие эту информации (в критических случаях) по адресу (например, рассылающие уведомления по смс, или производящие запуск новых серверов приложений, или записывающие информации о рабочих серверах приложений на балансировщик).
Наиболее часто используемое решение здесь — это Nagios с большим количеством проверок (несколько сотен или тысяч обычно). Дополнительно к нему подключают еще Pinba в случае PHP-приложений для более точного анализа проблем.
-
Обычно двух предыдущих уровней мониторинга бывает достаточно для обнаружения и решения всех проблем с инфраструктурой, но часто (в случае использования "облаков") присутствует еще промежуточный мониторинг, когда идет как мониторинг состояния всех серверов инфраструктуры, так анализ всех запросов, проходящих через выделенные в "облаке" мощности.
Промежуточный мониторинг используют как дополнительный уровень контроля качества работы сервиса (например, легко отслеживать количество 500 ошибок, даже если сервера приложений работают в штатном режиме) и принимать решение о переключении мощностей между гео-кластерам (например, такое возможно у Amazon).
-
Внешний мониторинг используется для анализа ситуации со стороны пользователей. Даже если система работает исправно, связность между серверами не нарушена, сервера отвечают быстро и стабильно, пользователи могут ощущать проблемы с использованием сервиса, и это будет зависеть от общего состояния Сети.
На этом уровне возможны дополнительные триггеры для принятия решения о переключения пользователей на другие гео-кластеры (например, европейских пользователей вести на европейский датацентр, а американских — на американский) для улучшения качества сервиса. Также этот уровень мониторинга может использоваться для дополнительной проверки результатов внутреннего и промежуточного мониторинга.
Встроенный мониторинг
Munin выдает большое количество информации о состоянии требуемого сервера. К наиболее часто проверяемым моментам относят:
- Проверка PHP (время выполнения, использование памяти, число хитов на 1 процесс и т.д.);
- Проверка NGINX (коды ответов, использование памяти, число процессов);
- Проверка MySQL (число запросов, использование памяти, время выполнение запросов);
- Проверка диска;
- Проверка почтового демона;
- Проверка сети;
- Проверка системы.
Внутренний мониторинг
Nagios как решение для мониторинга безусловно хорош. Но нужно быть готовым к тому, что кроме него придется использовать еще собственные скрипты и (или) Pinba (или аналогичное решения дл вашего языка программирования). Pinba оперирует UDP-пакетами и собирает информацию о времени выполнения скриптов, объеме памяти и кодах ошибок. В принципе, этого достаточно для создания полной картины происходящего и обеспечения требуемого уровня надежности сервиса в автоматическом режиме.
На уровне внутреннего мониторинга уже можно принимать решения о выделении дополнительных мощностей (если это возможно автоматически — то достаточно просто отслеживать средний уровень загрузки процессора на серверах приложений или базы данных, если это производится в ручном режиме — то можно высылать письма или jabber-сообщения) или их отключении. Также в случае возникновения аномального количества ошибок (обычно это происходит при отказе оборудования либо ошибки в новой версии веб-сервиса, и что является причиной, всегда можно установить за счет дополнительных проверок) можно слать уже экстренные уведомления по смс или звонить по телефону.
Также очень удобно настроить автоматическое добавление (или удаление) тестов при увеличении точек проверки (например, серверов ли пользовательских сайтов) с заданными шаблонами: например, проверка главной страницы, распределение времени выполнения PHP, распределение использования памяти для PHP, число nginx и PHP ошибок.
Промежуточный мониторинг
Мониторинг на уровне облачной инфраструктуры предлагает не такое большое количество провайдеров, и он является, скорее, информационным: реальные решения принимаются либо на основе внутренних данных, либо внешнего состояния системы. На промежуточном уровне можно только собирать статистику или подтверждать внутреннее состояние инфраструктуры.
Для Amazon CloudWatch здесь доступны следующие возможности проверки:
- Полный трафик (по инстансам и совокупный);
- Число ответов с балансировщика;
- Состояние инстансов (в том числе и инфраструктурных, которые производят внутренний мониторинг);
- И ряд других, которые можно комбинировать со внутренними, но лучше максимум логики оставить все же на уровне внутреннего мониторинга.
Также можно добавлять свои собственные метрики.
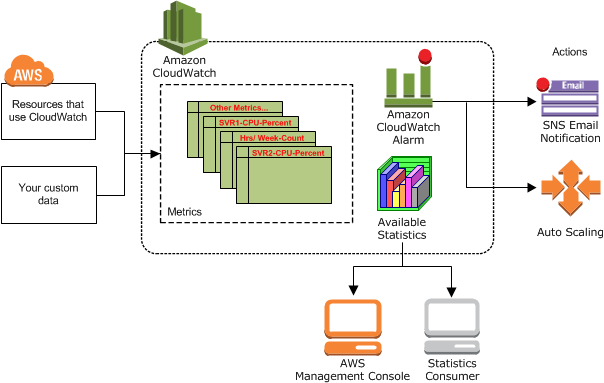
Уже по результатам мониторинга промежуточного (на уровне балансировщиков) можно принимать обоснованное решение о выделении или закрытии машин (инстансов) в кластере.
Внешний мониторинг
Здесь выбор решений очень большой. Если требуется отслеживать состояние серверов по всему миру, то лучшее решение — это Pingdom. Для российских реалий подойдет PingAdmin, Monitorus или WEBO Pulsar. Особенно удобно настроить проверку из нескольких географических точек и дергать удаленный скрипт уведомления, если сервис не доступен в течение 1-2 минут. Если при этом есть какие-либо проблемы внутри, то можно сразу переключаться на план "Б" (выключать неработающие сервера, отсылать уведомления и т.д.).
К дополнительным плюсам внешнего мониторинга можно отнести проверку реального времени ответа на стороне сервера (или реальных сетевых задержек). По этому параметру также можно настроить уведомления. Как дополнительная возможность в случае использования CDN: можно отслеживать полное время загрузки страниц сервиса и отключать или включать CDN для разных регионов.
Мониторинг нетипичных параметров и характеристик
Не стоит забывать и принимать во внимание некоторые нетипичные, но важные параметры, которые тоже необходимо отслеживать:
- Наличие бэкапов;
- Срок делегирования доменов;
- Срок действия SSL сертификатов;
- Баланс у провайдера СМС-уведомлений.