Отладка сложных веб-приложений
Многие проекты обходятся командами var_dump и echo. Однако, по мере усложнения проектов, разработчики скорее всего установят на локальных серверах что-то типа XDebug или Zend Debugger, что разумно и действительно упрощает отладку веб-приложения, если научиться этими штуками грамотно пользоваться.
Очень часто оказывается полезным XDebug в режиме сбора трейса. Иногда без трейса отловить ошибку или узкое место в производительности просто невозможно.
Тем не менее, есть одно весомое "Но" - эти инструменты создают серьезную нагрузку на веб-проект и включать их на боевых серверах - опасно. Инструменты помогут вам «вылизать» код на локальных серверах, но «выжить на бою», к сожалению, не помогут.
Логирование
Очень полезно, если нагрузка позволяет, включить на боевых серверах лог-файлы nginx, apache, php-fpm, вести свои лог-файлы бизнес-операций (создание особенных заказов, экспорт из 1С-Битрикс в SAP и т.п.).
Если у вас веб-кластер или просто много серверов с PHP - попробуйте собирать логи с этих машин на одну машину, где их централизованно мониторить. Используйте для этого, например, syslog-ng. Имея лог ошибок PHP со всех серверов кластера на одной машине, вам не придется бегать при аварии искать их по машинам.
xhprof
Существует отличный и полезный "боевой" профилировщик xhprof. Он практически не создает на нагрузку на PHP (проценты).
Он позволяет увидеть профиль выполнения хита:
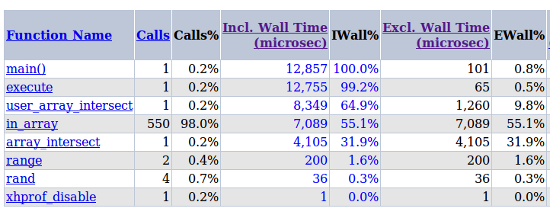
А также критический путь, что же тормозило-то на бою:

Причем он хорошо сочетается с встроенным инструментом отладки платформы Bitrix Framework (если у вас веб-решение на этой платформе): xhprof можно запускать на бою в пиках нагрузки, а Монитор производительности - когда нагрузка не зашкаливает или на серверах разработки/тестирования.
Динамическая трассировка
Если у вас веб-кластер, нередко удобно автоматизировать процесс динамической профилировки. Суть проста: профилировщик постоянно включен, после исполнения страницы мы проверяем время хита и если оно больше, к примеру, 2 секунд, сохраняем трейс в файл. Да, это добавляет лишних 50-100 мс, поэтому можно включать систему при необходимости либо включать по каждому, например, десятому хиту.
Файл
auto_prepend_file.php:
//Включаем профайлер по переменной или куке, хотя можно включать сразу
if (isset($_GET['profile']) && $_GET['profile']=='Y') {
setcookie("my_profile", "Y");
}
if (isset($_GET['profile']) && $_GET['profile']=='N') {
setcookie("my_profile", "",time() - 3600);
}
if ( !( isset($_GET['profile']) && $_GET['profile']=='N') && ( $_COOKIE['my_profile']=='Y' || ( isset($_GET['profile']) && $_GET['profile']=='Y') ) && extension_loaded('xhprof') ) {
xhprof_enable();
}
Файл
dbconn.php:
//Время выполнения хита получаем из пинбы, но можно в принципе напрямую из PHP (http://php.net/manual/ru/function.microtime.php)
//Forcing storing trace, if req.time > N secs
$profile_force_store = false;
$ar_pinba = pinba_get_info();
if ($ar_pinba['req_time']>2) $profile_force_store=true;
...
if ($profile_force_store || ( !(isset($_GET['profile']) && $_GET['profile']=='N') &&
( $_COOKIE['my_profile']=='Y' || ( isset($_GET['profile']) && $_GET['profile']=='Y' )) && extension_loaded('xhprof') ) {
$xhprof_data = xhprof_disable();
$XHPROF_ROOT = realpath(dirname(__FILE__)."/perf_stat");
include_once $XHPROF_ROOT . "/xhprof_lib/utils/xhprof_lib.php";
include_once $XHPROF_ROOT . "/xhprof_lib/utils/xhprof_runs.php";
// save raw data for this profiler run using default
// implementation of iXHProfRuns.
$xhprof_runs = new XHProfRuns_Default();
// save the run under a namespace "xhprof_foo"
$run_id = $xhprof_runs->save_run($xhprof_data, "xhprof_${_SERVER["HTTP_HOST"]}_".str_replace('/','_',$_SERVER["REQUEST_URI"]));
Таким образом, если хит оказался дольше 2 секунд, мы его сохраняем во временную папку на сервере. Затем, на машине мониторинга можно обойти сервера и забрать с них трейсы для централизованного анализа (пример для виртуальных хостов в амазоне):
#!/bin/bash
HOSTS=`as-describe-auto-scaling-groups mygroup | grep -i 'INSTANCE' | awk '{ print $2}' | xargs ec2-describe-instances | grep 'INSTANCE' | awk '{print $4}'`
for HOST in $HOSTS ; do
scp -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -p -i /home/trace_loader/.ssh/id_rsa "trace_loader@${HOST}:/tmp/*xhprof*" /my_profiles
done
Теперь у вас есть собранные в одном месте трейсы запросов более 2 секунд. Напишите веб-интерфейс для их просмотра в отсортированном по дате порядке, что займет минут 30. Часть бизнес-процесса готова - каждый трейс является фактически ТЗ на оптимизацию веб-приложения, можно подключать к ним специалистов из разработки.
strace
Иногда профилировщик и лог-файлы не позволяют определить причину проблемы. И на серверах разработки при отладке (XDebug) воспроизвести эту же проблему не получается. Остается одно - понять, что происходит в момент наступления события на боевом сервере. Тут часто неоценимую помощь оказывает трассировщик системных вызовов, например strace. Только не нужно впадать в ступор при виде системных вызовов Linux. Немного усилий и вы поймете идею и сможете отлавливать на боевых серверах самые трудноуловимые ошибки и узкие места.
Примечание: Не стоит смущаться системных вызовов unix, они просты и прямолинейны. Многие объекты в системе представляются в виде файлов и сокетов. По любому вызову можно быстро получить встроенную информацию:
man 2 open
man 2 sendto
man 2 nanosleep
Если у вас нет этих мануалов, их можно поставить так (на CentOS6):
&yum install man-pages
Посмотреть последнюю документацию по системным вызовам можно также в Интернете или из консоли:
man syscalls
Потратив немного времени на понимание как работает PHP на уровне операционной системы, вы получите в руки секретное оружие, позволяющее быстро найти и устранить практически любое узкое место высоконагруженного веб-проекта.
Нужно правильно «прицепить» трассировщик к процессам PHP. Процессов часто запущено много, в разных пулах, они постоянно гасятся и поднимаются (нередко для защиты от утечек памяти задают время жизни процесса например в 100 хитов):
ps aux | grep php
root 24166 0.0 0.0 391512 4128 ? Ss 11:47 0:00 php-fpm: master process (/etc/php-fpm.conf)
nobody 24167 0.0 0.6 409076 48168 ? S 11:47 0:00 php-fpm: pool www1
nobody 24168 0.0 0.4 401736 30780 ? S 11:47 0:00 php-fpm: pool www1
nobody 24169 0.0 0.5 403276 39816 ? S 11:47 0:00 php-fpm: pool www1
nobody 24170 0.0 1.0 420504 83376 ? S 11:47 0:01 php-fpm: pool www1
nobody 24171 0.0 0.6 408396 49884 ? S 11:47 0:00 php-fpm: pool www1
nobody 24172 0.0 0.5 404476 40348 ? S 11:47 0:00 php-fpm: pool www2
nobody 24173 0.0 0.4 404124 35992 ? S 11:47 0:00 php-fpm: pool www2
nobody 24174 0.0 0.5 404852 42400 ? S 11:47 0:00 php-fpm: pool www2
nobody 24175 0.0 0.4 402400 35576 ? S 11:47 0:00 php-fpm: pool www2
nobody 24176 0.0 0.4 403576 35804 ? S 11:47 0:00 php-fpm: pool www2
nobody 24177 0.0 0.7 410676 55488 ? S 11:47 0:00 php-fpm: pool www3
nobody 24178 0.0 0.6 409912 53432 ? S 11:47 0:00 php-fpm: pool www3
nobody 24179 0.1 1.3 435216 106892 ? S 11:47 0:02 php-fpm: pool www3
nobody 24180 0.0 0.7 413492 59956 ? S 11:47 0:00 php-fpm: pool www3
nobody 24181 0.0 0.4 402760 35852 ? S 11:47 0:00 php-fpm: pool www3
nobody 24182 0.0 0.4 401464 37040 ? S 11:47 0:00 php-fpm: pool www4
nobody 24183 0.0 0.5 404476 40268 ? S 11:47 0:00 php-fpm: pool www4
nobody 24184 0.0 0.9 409564 72888 ? S 11:47 0:01 php-fpm: pool www4
nobody 24185 0.0 0.5 404048 40504 ? S 11:47 0:00 php-fpm: pool www4
nobody 24186 0.0 0.5 403004 40296 ? S 11:47 0:00 php-fpm: pool www4
Чтобы не гоняться за меняющимися ID процессов PHP, можно поставить им временно короткое время жизни:
pm.max_children = 5
pm.start_servers = 5
pm.min_spare_servers = 5
pm.max_spare_servers = 5
pm.max_requests = 100
Затем запустить strace так:
strace -p 24166 -f -s 128 -tt -o trace.log
То есть trace запускается как рутовый процесс и при появлении новых потомков он автоматически начнет отслеживать их тоже.
Теперь желательно в лог файлы PHP начать писать PID процесса, чтобы можно было быстро сопоставить долгий хит из лога с конкретным процессом трейса:
access.log = /opt/php/var/log/www.access.log
access.format = "%R # %{HTTP_HOST}e # %{HTTP_USER_AGENT}e # %t # %m # %r # %Q%q # %s # %f # %{mili}d # %{kilo}M # %{user}C+%{system}C # %p"
Дождёмся когда появится жертва, например долгий хит:
[24-May-2012 11:43:49] WARNING: [pool www1] child 22722, script '/var/www/html/myfile.php' (request: "POST /var/www/html/myfile.php") executing too slow (38.064443 sec), logging
- # mysite.ru # Mozilla/5.0 (Windows NT 6.1; WOW64; rv:12.0) Gecko/20100101 Firefox/12.0 # 24/May/2012:11:43:11 +0400 # POST # /var/www/html/myfile.php # # 200 # /var/www/html/myfile.php # 61131.784 # 6656 # 0.03+0.03 # 22722
Трактуем системные вызовы
Системные вызовы - это низкоуровневые «элементарные» операции, которыми программа общается с операционной системой. На них зиждется все IT-мироздание с разными языками программирования и технологиями. Системных вызовов не очень много (аналогично небольшому числу команд процессора и бесчисленному количеству языков и диалектов выше по стеку).
Команды PHP веб-проекта выполняются строго друг за другом в рамках одного процесса. Поэтому в трейсе нужно отфильтровать процесс подозрительного хита - 22722 из примера выше:
cat trace.log | grep '22722' | less
Время хита известно из лога, осталось посмотреть что творилось при построении страницы и почему висело так долго (трейс немного отредактирован). Видны запросы к БД и ответы:
24167 12:47:50.252654 write(6, "u\0\0\0\3select name, name, password ...", 121) = 121
24167 12:47:50.252915 read(6, "pupkin, 123456"..., 16384) = 458
Обращения к файлам:
24167 12:47:50.255299 open("/var/www/html/myfile.php", O_RDONLY) = 7
Взаимодействие с memcached:
24167 12:47:50.262654 sendto(9, "add mykey 0 55 1\r\n1\r\n", 65, MSG_DONTWAIT, NULL, 0) = 65
24167 12:47:50.263151 recvfrom(9, "STORED\r\n", 8192, MSG_DONTWAIT, NULL, NULL) = 8
...
24167 12:47:50.282681 sendto(9, "delete mykey 0\r\n", 60, MSG_DONTWAIT, NULL, 0) = 60
24167 12:47:50.283998 recvfrom(9, "DELETED\r\n", 8192, MSG_DONTWAIT, NULL, NULL) = 9
И вот видим, например, почему хит завис:
22722 11:43:11.487757 sendto(10, "delete mykey 0\r\n", 55, MSG_DONTWAIT, NULL, 0) = 55
22722 11:43:11.487899 poll([{fd=10, events=POLLIN|POLLERR|POLLHUP}], 1, 1000) = 1 ([{fd=10, revents=POLLIN}])
22722 11:43:11.488420 recvfrom(10, "DELETED\r\n", 8192, MSG_DONTWAIT, NULL, NULL) = 9
22722 11:43:11.488569 sendto(10, "delete mykey2 0\r\n", 60, MSG_DONTWAIT, NULL, 0) = 60
22722 11:43:11.488714 poll([{fd=10, events=POLLIN|POLLERR|POLLHUP}], 1, 1000) = 1 ([{fd=10, revents=POLLIN}])
22722 11:43:11.489215 recvfrom(10, "DELETED\r\n", 8192, MSG_DONTWAIT, NULL, NULL) = 9
22722 11:43:11.489351 close(10) = 0
22722 11:43:11.489552 gettimeofday({1337845391, 489591}, NULL) = 0
22722 11:43:11.489695 gettimeofday({1337845391, 489727}, NULL) = 0
22722 11:43:11.489855 nanosleep({0, 100000}, NULL) = 0
22722 11:43:11.490155 nanosleep({0, 200000}, NULL) = 0
22722 11:43:11.490540 nanosleep({0, 400000}, NULL) = 0
22722 11:43:11.491121 nanosleep({0, 800000}, NULL) = 0
22722 11:43:11.492103 nanosleep({0, 1600000}, NULL) = 0
22722 11:43:11.493887 nanosleep({0, 3200000}, NULL) = 0
22722 11:43:11.497269 nanosleep({0, 6400000}, NULL) = 0
22722 11:43:11.503852 nanosleep({0, 12800000}, NULL) = 0
22722 11:43:11.516836 nanosleep({0, 25600000}, NULL) = 0
22722 11:43:11.542620 nanosleep({0, 51200000}, NULL) = 0
22722 11:43:11.594019 nanosleep({0, 102400000}, NULL) = 0
22722 11:43:11.696619 nanosleep({0, 204800000}, NULL) = 0
22722 11:43:11.901622 nanosleep({0, 409600000}, NULL) = 0
22722 11:43:12.311430 nanosleep({0, 819200000},
22722 11:43:13.130867 <... nanosleep resumed> NULL) = 0
22722 11:43:13.131025 nanosleep({1, 638400000},
22722 11:43:14.769688 <... nanosleep resumed> NULL) = 0
22722 11:43:14.770104 nanosleep({1, 638400000},
22722 11:43:16.408860 <... nanosleep resumed> NULL) = 0
22722 11:43:16.409048 nanosleep({1, 638400000},
22722 11:43:18.047808 <... nanosleep resumed> NULL) = 0
22722 11:43:18.048103 nanosleep({1, 638400000},
22722 11:43:19.686947 <... nanosleep resumed> NULL) = 0
22722 11:43:19.687085 nanosleep({1, 638400000},
22724 11:43:20.227224 <... lstat resumed> 0x7fff00adb080) = -1 ENOENT (No such file or directory)
22722 11:43:21.325824 <... nanosleep resumed> NULL) = 0
22722 11:43:21.326219 nanosleep({1, 638400000},
22722 11:43:22.964830 <... nanosleep resumed> NULL) = 0
22722 11:43:22.965126 nanosleep({1, 638400000},
22722 11:43:24.603692 <... nanosleep resumed> NULL) = 0
22722 11:43:24.604117 nanosleep({1, 638400000},
22722 11:43:26.250371 <... nanosleep resumed> NULL) = 0
22722 11:43:26.250580 nanosleep({1, 638400000},
22722 11:43:27.889372 <... nanosleep resumed> NULL) = 0
22722 11:43:27.889614 nanosleep({1, 638400000},
22722 11:43:29.534127 <... nanosleep resumed> NULL) = 0
22722 11:43:29.534313 nanosleep({1, 638400000},
22722 11:43:31.173004 <... nanosleep resumed> NULL) = 0
22722 11:43:31.173273 nanosleep({1, 638400000},
22722 11:43:32.812113 <... nanosleep resumed> NULL) = 0
22722 11:43:32.812531 nanosleep({1, 638400000},
22722 11:43:34.451236 <... nanosleep resumed> NULL) = 0
22722 11:43:34.451554 nanosleep({1, 638400000},
22722 11:43:36.090229 <... nanosleep resumed> NULL) = 0
22722 11:43:36.090317 nanosleep({1, 638400000},
22724 11:43:36.522722 fstat(12,
22723 11:43:36.622833 <... gettimeofday resumed> {1337845416, 622722}, NULL) = 0
22722 11:43:37.729696 <... nanosleep resumed> NULL) = 0
22722 11:43:37.730033 nanosleep({1, 638400000},
22724 11:43:39.322722 gettimeofday(
22722 11:43:39.368671 <... nanosleep resumed> NULL) = 0
22722 11:43:39.368930 nanosleep({1, 638400000},
22722 11:43:41.007574 <... nanosleep resumed> NULL) = 0
22722 11:43:41.007998 nanosleep({1, 638400000},
22722 11:43:42.646895 <... nanosleep resumed> NULL) = 0
22722 11:43:42.647140 nanosleep({1, 638400000},
22720 11:43:43.022722 fstat(12,
22720 11:43:43.622722 munmap(0x7fa1e736a000, 646) = 0
22722 11:43:44.285702 <... nanosleep resumed> NULL) = 0
22722 11:43:44.285973 nanosleep({1, 638400000},
22722 11:43:45.926593 <... nanosleep resumed> NULL) = 0
22722 11:43:45.926793 nanosleep({1, 638400000},
22722 11:43:47.566124 <... nanosleep resumed> NULL) = 0
22722 11:43:47.566344 nanosleep({1, 638400000},
22722 11:43:49.205103 <... nanosleep resumed> NULL) = 0
22722 11:43:49.205311 nanosleep({1, 638400000},
22719 11:43:49.440580 ptrace(PTRACE_ATTACH, 22722, 0, 0
Сначала шли обращения к memcached: запись/чтение сокета 10, затем сокет был успешно закрыт (22722 11:43:11.489351 close(10) = 0), затем в коде был вызов nanosleep в цикле и условие выхода из цикла не срабатывало по причине предварительно закрытого сокета. В результате причину удалось быстро определить и поправить код.
