Просмотров: 34939
Дата последнего изменения: 23.09.2021
Сложность урока:
4 уровень - сложно, требуется сосредоточиться, внимание деталям и точному следованию инструкции.
5
Инструменты для анализа
Для анализа собранных данных нужен инструмент. Можно написать своё, а можно использовать готовые решения для создания моделей: Rapidminer, SAS, SPSS и другие. Свои инструменты можно создать на готовых библиотеках: Spark MLlib (scala/java/python) если много данных или scikit-learn.org (python) если мало данных.
Rapidminer - очень удобный инструмент. Модель в нём собирается из "кубиков", есть несколько сот операторов для обучения и статистики. Инструмент позволяет изменять диапазоны параметров, может строить графики. Типовые трудозатраты создания модели в нём - 1-2 часа.
Примерные сроки программирования если выбрано создание собственного инструмента, при достаточном опыте, - небольшие. Модель вообще не должна быть большой. Создание модели в коде из 5 строк - это 10 минут.
Обучение модели - минуты, десятки минут. Очень редко (использование опорных векторов, нейронные модели) и при необходимости - часы, дни, особенно при использовании DeepLearning.
Оценка качества модели - десятки минут с использованием метрик AUC (area under curve), Recall/Precision, Cross-validation. Методика оценки проста: делается бинарный классификатор и доказывается что он работает точнее обычного гадания Да/Нет. Если работает на 10-15% лучше, то модель годна, можно опробовать её "в бою". Данного результата достаточно в 80% случаев.
Если данных много, то обработка происходит долго. Для ускорения можно использовать векторизацию текста, LSH (locality sensetive hashing), word2vec.
Визуализация
Первое что нужно сделать - научиться визуализировать полученные данные: строить графики, гистограммы и так далее. Визуализация позволяет понять как у вас распределены данные и что у вас с ними происходит.
Как правило инструменты для этого есть у всех. Это Munin, Cacti, InfluxDB. Если размерностей много, то можно их сжать (PCA, SVD). Перед началом использования сложных инструментов всегда надо попробовать решить задачу простыми средствами.
Простейшие и первейшие это гистограммы: время загрузки страницы, вызов метода API, время жизни ключей в redis.
Кластерный анализ
Если рассыпать много шариков по полу, то где-то они будут в одиночестве, а где-то соберутся в кучи. Это в двухмерной плоскости. Если плоскость трёхмерная, то получатся "облачка". Вот эти "облачка" и кучи и есть кластеры.
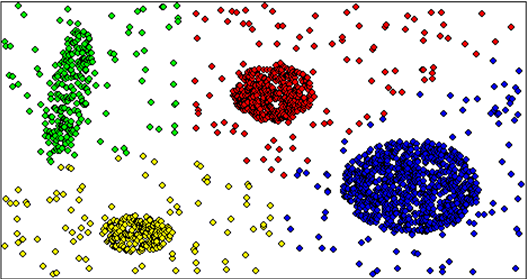
Кластерный анализ нужен когда есть несколько (больше чем три) векторов измерений. Например:
- частота процессора - загрузка за 5 минут, 10 минут, 15 минут;
- load everage - загрузка за 5 минут, 10 минут, 15 минут;
- нагрузка на диск за 5 минут, 10 минут, 15 минут;
- и так далее.
Эти данные кластеризуются, то есть ищутся "облачка" и получается типизация нагрузки на серверы.
Виды кластерного анализа:
- Иерархическая
- K-means
- C-means
- Spectral
- Density-based (DBSCAN)
- Вероятностные
- Для "больших данных"
Для нашей задачи вполне достаточно использовать K-means.
Кейсы кластерного анализа:
- Основные типы нагрузки на сервер (высокая нагрузка базы, большая нагрузка на CPU, низкая нагрузка на сеть).
- Типы клиентов API (позволяет адаптироваться к самым востребованным клиентам API).
- Виды нагрузки на БД из веб-приложения.
- Виды DDOS.
- Нагрузка, создаваемая страницами веб-приложения.
Кластерный анализ – оценки на программирование:
- Анализ в Rapidminer (0.1-2 часа)
- Анализ в Spark Mllib (1-2 дня, много данных)
- Анализ в scikit-learn – аналогично (мало данных)
На выходе нужно получить список кластерных групп, лучше с визуализацией.
Метрики качества кластеризации достаточно просты: кластера должны быть явно видны. Есть строгие математические понятия: плотность и прочие, но в нашем случае достаточно простой визуализации с явным выделением кластеров.
Классификация
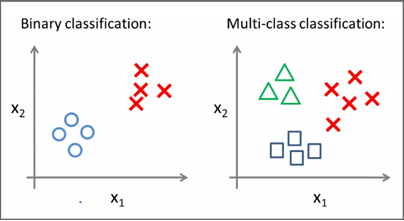
Классификация и кластеризация - разные вещи. Кластеризация - автоматическая группировка данных в многомерном пространстве. Классификация - обучение компьютера распределять сущности по классам.
Два вида классификации:
| 
|
Собраны метрики с серверов (например, 50 плоскостей), раскидываем точки в 50-имерном пространстве. С помощью машинного обучения строим гиперплоскость (плоскость в 50-имерном пространстве). Далее системе говорится, что если вектор попадет в какое-то место этой плоскости, то сервер упадёт через час. И это сбывается в 70% случаев.
В рамках задачи безопасной и эффективной эксплуатации можно предложить такие кейсы:
- Когда начнут появляться 500-е ответы клиенту.
- Когда страницы будут выдавать ошибки соединения с БД.
- Увеличится время ответа API: да/нет
- Сервер будет перегружен: да/нет
- БД начнет «тормозить»: да/нет
- Apache забьется запросами: да/нет
- Начинается DDOS: да/нет
- Кэширование не везде включено: да/нет
- Сжатие не включено: да/нет
В чём разница между человеческим реагированием и машинным? Машина предотвращает эти ошибки, человек реагирует на уже совершённые ошибки. Есть специалисты, которые могут отслеживать работу и квалифицировано предотвращать проблему. Но такие люди редки и дороги. Машинное обучение - замена таким дорогим специалистам.
Советы и секреты
Не усложняйте себе работу. Начинать всегда лучше с самой простой модели, например, Naive Bayes - простейшего байесовского классификатора, который работает хорошо в 80% случаев. В случае неудовлетворительной работы этой модели можно попробовать Метод опорных векторов (support vector machine), которая обучается медленнее, но работает точнее.
Если и в этом случае не получился приемлемый результат, то можно попробовать поменять ядро и, в самом крайнем случае, попробовать нейронные сети, но это не очень-то приветствуется в силу сложности, трудозатратности и других трудностей.
Как оценивать качество работы?
- Для бинарного классификатора лучше всего - ROC-кривая (area under ROC curve, площадь под ROC-кривой), которая должна быть больше 0.5: 0.6, 0.75, 0.8 - это уже отличный результат. Так же можно оценить с помощью параметров Recall (полнота) и Precision (Точность).
- Для мультиклассового классификатора удобна Confusion matrix.
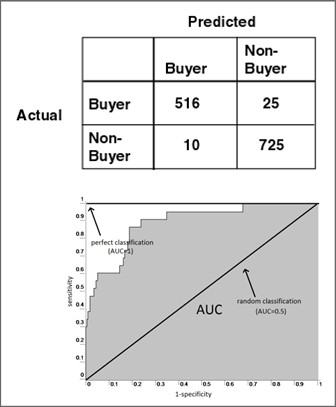
Всё в целом выглядит просто: есть данные, есть оттренированная модель, которая научилась решать вашу задачу (когда зависнет сервер), определили качество модели, можно выходить "в бой".
Модель нужно ставить на самое критичное место в вашей эксплуатации.
Данные нужно периодически обновлять: раз в неделю, раз в месяц - частота зависит от ваших задач. После смены данных нужно тестировать модель заново.
