Просмотров: 40723
Дата последнего изменения: 23.09.2021
Сложность урока:
3 уровень - средняя сложность. Необходимо внимание и немного подумать.
4
5
База данных, узкие места
Можно организовать распределение нагрузки на чтение между slave'ми. Но, так как все веб-сервера читают данные со всех серверов MySQL, то остаются высокие требования к связанности сети, пропускной способности, величине задержки между пакетами. В идеале все сервера должны находиться в одном дата-центре. Однако, если случится авария на уровне целого дата-центра, возникнет проблема. Такое возможно, более того, такое происходило.
Другая проблема - невозможность масштабирования между разными серверами, так как мы потеряем в скорости.
Третья проблема может возникнуть, если выйдет из строя master. В этом случае требуется заранее либо автоматизировать процедуру его восстановления, написать какие-то скрипты, которые будут превращать один из slave в master, либо оставить это администратору на ручной разбор ситуации. Правда, если авария произошла когда администратор недоступен, то проект может простаивать достаточно долго.
Необходимо резервировать сам дата-центр. По-хорошему, проект должен быть распределён географически по миру или, как минимум, по двум дата-центрам, чтобы можно было обезопасить проект даже от таких аварий.
Что можно сделать? Гео-кластер, хотя бы в упрощённом варианте. Правда, тут возникают повышенные требования к проектированию приложения.
Гео-кластер
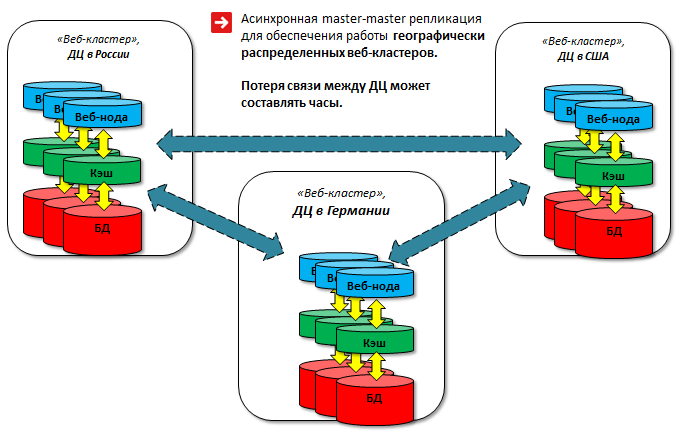
Предлагаемая схема - весьма условная master-master репликация, так как не происходит одновременной записи в две базы. Однако в большинстве случаев задача резервирования решается полностью. Эта схема позволяет держать несколько master'ов, хотя и с рядом ограничений.
Создаются группы серверов в административном интерфейсе:
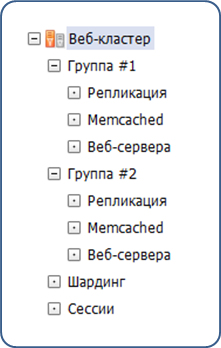
У каждой группы свой MySQL master (указан в dbconn.php). Мастеры MySQL объединены в кольцо (в минимальном варианте – 2 сервера).
Каждая группа клиентов работает с определённым сервером. Например, посетители из Европы должны попадать в европейский дата-центр и писать в master, который, находится там. Посетители из России должны попадать в российский дата-центр, и так далее. В случае аварии трафик переключается на другой дата-центр, и все посетители продолжают работать с "горячими" данными без каких-то отставаний и потерь.
Реализуется такая схема следующим образом: в самом MySQL есть возможность задать смещение для полей: auto_increment_increment и auto_increment_offset. Это обеспечивает поступление данных "стык в стык" и они не будут дублироваться. Базы в разных дата-центрах синхронны, при этом независимы друг от друга: потеря связности между дата-центрами может составлять часы, данные синхронизируются после восстановления. Таблицы БД должны иметь подобные ключи, чтобы данные не дублировались и не попадали одинаковые в разные дата-центры.
Пользователь и все сотрудники одной и той же компании работают в одном датацентре за счет управления балансировщиком. Этим исключаются сбои в подобной схеме работы master-master репликации. Сессии хранятся в базе, и объём этих данных достаточно большой. В результате были ошибки в получении данных из query кеша. Эти данные, так как пользователи направляются на определённые сервера, можно не реплицировать из-за большого трафика и возможных блокировок:
SET sql_log_bin = 0
или
replicate-wild-ignore-table = %.b_sec_session%
В результате достигнут один из приоритетов - постоянная доступность сервиса, его отказоустойчивость. Все ноды заменяемы и не зависят друг от друга, в случае аварии стартуем новые. Два дата-центра синхронизированы друг с другом и равноценно обслуживают клиентов. В случае аварии на уровне дата-центра или плановых работ с базой трафик прозрачно для клиентов переключается на рабочий дата-центр.
