Просмотров: 49376
Дата последнего изменения: 14.02.2023
Сложность урока:
2 уровень - несложные понятия и действия, но не расслабляйтесь.
3
4
5
Общие принципы и требования
Рассмотрим общие принципы, которыми вы должны руководствоваться при организации резервного копирования для крупного проекта:
- для разных сценариев сбоев должны быть созданы разные резервные копии (бекапы);
- необходимо делать резервные копии файлов и базы данных;
- резервное копирование должно выполняться постоянно;
- нужно делать бекапы конфигурации и настроек сервера и программного обеспечения;
- полезно проводить учения по восстановлению системы;
- нужно уметь восстанавливаться быстро;
- восстановление системы можно частично автоматизировать.
Бекап должен отвечать следующим требованиям:
- изолированность;
- целостность;
- версионность;
- безопасность.
Если вы будете следовать данным принципам и иметь отлаженные процессы работы с резервными копиями, то вы всегда сможете быстро восстановить работоспособность проекта или отдельных его элементов, даже в случае критических сбоев, в том числе с потерей данных.
Бекап файлов
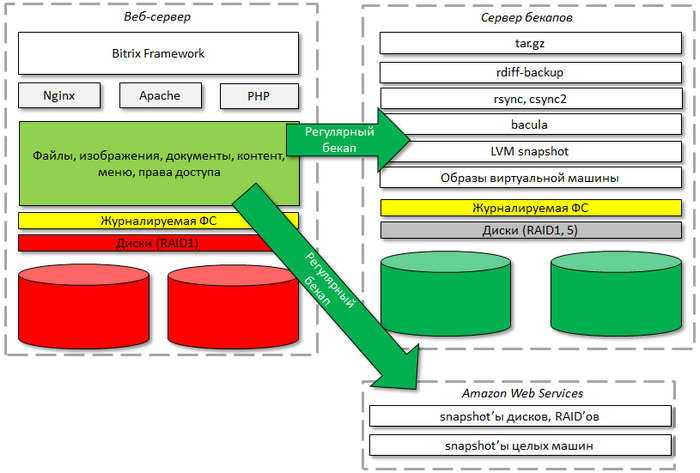
Бекап файлов должен храниться на отдельном сервере. Если проект небольшой, то обычно бекап файлов делается с помощью программы tar (плюс утилита gz или bz2). Альтернативой могут быть rsync, csync2, rdiff-backup.
Если на проекте очень много файлов, то для создания бекапа файлов следует использовать LVM snapshot, облачный механизм snapshot'ов для Amazon (см. пример), snapshot в хранилище типа NetApp и т.п. При этом обратите внимание, что для создания snapshot'ов подходят только те файловые системы, которые поддерживают возможность "замораживания" (fsfreeze).
Кроме того, иногда бывает полезным вынести редко меняющиеся файлы в облако (например, Amazon S3, Google Cloud Storage) и время от времени делать бекап самого облака.
Если на сервере хранится большое количество бекапов, то для удобной работы с ними целесообразно иногда пользоваться пакетом bacula.
Внимание! Не забывайте периодически тестировать восстанавливаемость бекапов файлов.
Бекап базы данных
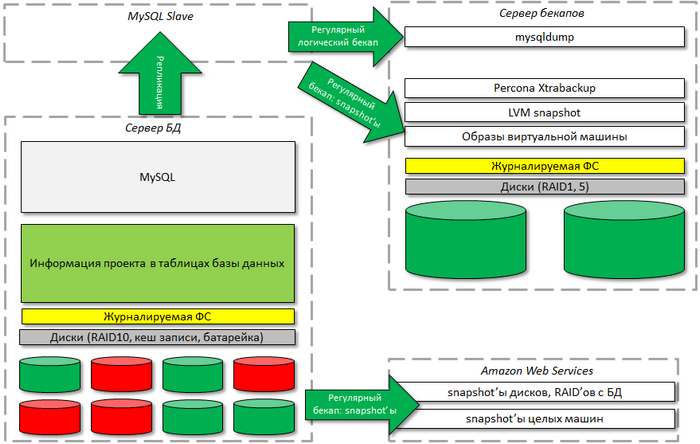
Репликация – это не бекап, но может выполнить некоторые его функции, например, при использовании pt-slave-delay.
Логические (mysqldump) и бинарные (Percona Xtrabackup или MySQL Enterprise Backup) бекапы используются для восстановления отдельных баз или таблиц, поврежденных в случае некорректных операций в системе или ошибок пользователей.
Логический бекап MySQL должен быть всегда и его лучше делать со slave-сервера, чтобы не нагружать сервер с «боевой» базой данных. При этом необходимо отслеживать синхронность его данных (mixed mode replication, --sync-binlog, pt-table-checksum). Используя опцию --single-transaction, можно сделать целостный бекап без блокировки таблиц, причем иногда прямо с «боевой» базы данных. Кроме того, рекомендуется сохранять позицию бинарного лога в бекапе (опция --master-data=2). Сами бинарные логи полезно хранить на отдельном диске, поскольку они очень важны при восстановлении.
Бинарный бекап можно делать и с «боевого», и со slave-сервера (делается он не очень быстро, но гораздо быстрее логического). Кроме того, он позволяет сохранять инкременты, т.е. его можно делать чаще одного раза в сутки. Восстановление из бинарного бекапа достаточно долгое, зачастую удобно пользоваться инкрементальными snapshot'ами дисков базы данных. Но все-таки такой бекап позволяет довольно быстро поднять новый slave-сервер (значительно быстрее, чем из логического бекапа).
Кроме того, можно удобно и быстро сделать копию базы данных, используя механизм snapshot'ов (LVM snapshot'ы, snapshot'ы в Amazon и NetApp). Общая схема действий такова: блокируются все таблицы базы, сбрасываются изменения и делается freeze файловой системы, затем снимается snapshot, «размораживается» файловая система и снимается блокировка с таблиц. Снимать snapshot'ы с базы данных можно достаточно часто: хоть каждые полчаса и даже чаще. Но обязательно необходимо проверять, что база восстанавливается из такого snapshot'а. Время восстановления обычно быстрее, чем для логического бекапа, может составлять от нескольких минут до часов (в зависимости от ситуации). Кроме того, используя, например, сервис Amazon, можно делать snapshot'ы всего сервера целиком и разворачиваться очень быстро в случае сбоя.
Полезные советы
- Для файлов желательно делать раз в сутки обычный бекап и несколько раз в сутки снимать snapshot'ы.
- Для базы данных полезно делать раз в сутки логический бекап, несколько раз в сутки делать snapshot'ы или бинарный (можно инкрементальный) бекап с помощью Xtrabackup.
- Необходимо иметь как минимум один slave-сервер базы данных.
- Периодически проверяйте, что файлы и база данных восстанавливаются из бекапов.
- Бекапы храните на отдельном сервере.
- Обсудите с клиентом длительность хранения бекапов и snapshot'ов (разумный срок - неделя).
