Просмотров: 47642
Дата последнего изменения: 11.11.2024
Сложность урока:
3 уровень - средняя сложность. Необходимо внимание и немного подумать.
4
5
NoSQL и его возможности
В последнее время все больше говорят про NoSQL. Технологии этого семейства начинают активно использовать известные авторитетные компании, в том числе в высоконагруженных проектах с немалыми объемами данных. Чтобы понять, применима ли эта технология к создаваемому вами проекту, надо разобраться в ваших потребностях и понять, сможет ли она их удовлетворить.
NoSQL (англ. not only SQL, не только SQL) - термин, обозначающий ряд подходов, направленных на реализацию хранилищ баз данных, имеющих существенные отличия от моделей, используемых в традиционных реляционных СУБД с доступом к данным средствами языка SQL. Применяется к базам данных, в которых делается попытка решить проблемы масштабируемости и доступности за счёт атомарности и согласованности данных.
В двух словах NoSQL - это необходимость выбора в рамках проекта двух из трех принципов работы с БД: согласованность данных (Consistency), доступность (Availability), устойчивость к разделению (Partition tolerance).
Причина такой необходимости - новые бизнес-задачи, которые возникли в последнее время:
- База должна быть всегда доступна для записи и чтения, и кейсы типа: сервер перезагружается, сеть упала - становятся критичными для бизнеса.
- Интенсивный рост объемов данных и ужесточение требований к их доступности, в том числе из-за бурного развития всемирной сети (в одной базе данные просто перестали помещаться).
- Клиентов становится много в разных точках мира, и нужно сохранить заказы как можно быстрее.
- Бурный рост веб-сервисов, появление мобильных устройств.
В техническом плане эти требования означают, что база должна:
- быть доступна всегда, нельзя потерять заказ клиента или его корзину, даже если пропала синхронизация между нодами базы данных.
- быть доступна везде (Европе и США), и, конечно, синхронизировать данные между копиями.
- неограниченно масштабироваться при увеличении объема данных.
- масштабироваться под нагрузку: на запись, на чтение.
При этом классические кластера БД не могут обеспечить эти возможности. Вот описания проблем, свойственных популярным БД:
- Oracle RAC - дорого и сложно, тяжеловесно, и непонятно, как раскидывать по разным материкам.
- MySQL cluster - быстрый мастер-мастер, но много подводных камней и ограничений вроде хранения данных только в памяти. Всё же достаточно удобен для некоторых кейсов.
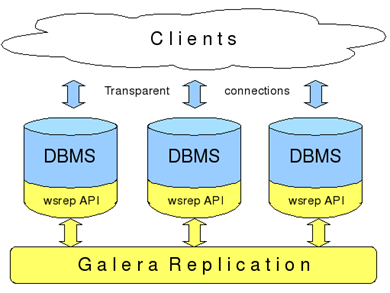
- galera cluster for mysql - честный мастер-мастер, пиши куда хочешь (но должен знать, куда именно). Нет "устойчивости к разделению", может зависнуть при отсутствии кворума. Трудно восстанавливается при падении и тормозит при геораспределенном использовании, т.к. синхронно передает данные на все копии. Нет шардинга данных между мастерами.
Так вот, прошло не так много времени, как в начале нынешнего столетия появились NoSQL-продукты и стало возможным:
- писать на любой элемент кластера;
- размещать элементы кластера на разных материках и читать с локальных;
- выключать любую ноду кластера без угрозы для системы в целом
- добавлять ноды кластера по потребности, что позволяет масштабировать как запись, так и чтение.
Пример того, как программисты реализуют требования бизнеса используя NoSQL. В строке с информацией о книге хранятся комментарии пользователей к ней. Что невозможно в рамках традиционной БД:
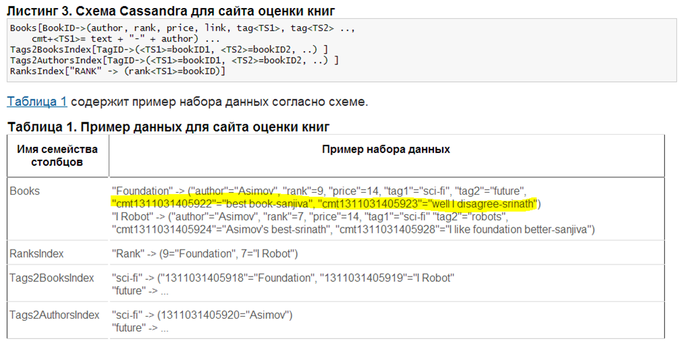
Ограничения NoSQL
Но и у NoSQL есть свои ограничения.
- NoSQL позволяет писать на любую ноду кластера, но по умолчанию читать приходится устаревшую неконсистентную информацию, так как информация распространяется с ограниченной скоростью. NoSQL-продукты предоставляют опцию чтения только что записанной информации, но за это придется платить увеличением времени ожидания.
- NoSQL позволяет разместить ноды кластера на разных материках, но так как информации нужно время, чтобы она разошлась по континентам, то приложение должно уметь это обработать.
- NoSQL позволяет выключать любую ноду кластера, но устойчивость к разделению кластера реализована за счет технологий, похожих на версионность. Следовательно, периодически нужно будет запускать поиск рассогласований типа Anti-entropy using Merkle trees.
- NoSQL позволяет добавлять ноды кластера по необходимости, но конфигурировать остальные ноды все-таки придется, и иногда это совсем не просто сделать.
Это общие для продуктов NoSQL ограничения. Но есть нюансы и в использовании конкретных реализаций. Рассмотрим их на примере Amazon DynamoDB (очень похожий на Apache Cassandra.)
Ограничения Amazon DynamoDB:
- Мало типов данных: число, строка, бинарные данные. Нет DATETIME (их можно эмулировать таймстампом).
- Ограничения по индексам. Индексы нужно указать сразу, их должно быть не более 5 на таблицу. Причем добавлять их в существующую таблицу нельзя, нужно ее удалять, пересоздавать и перезаливать туда данные.
- Можно хранить любой объем данных, но размер одной "строки таблицы" с именами и значениями "колонок" не должен превышать 64КБ. Правда число "колонок" не ограничивается.
И на одной ноде кластера (c одним значением основного индекса hash key) при наличии дополнительных индексов нельзя хранить больше 10ГБ. (Термин "колонока" - условный. В NoSQL нередко понятия схемы данных просто нет, поэтому в каждой "строке таблицы" могут быть разные "колонки" или "атрибуты".)
- Запросы. Можно выбрать данные только по одному индексу. Есть еще основной (hash key) индекс, но диапазонные выборки делать по нему нельзя - только константные. Отсортировать можно только по одному индексу.
Нельзя использовать сложные WHERE, GROUP BY, не говоря уже о подзапросах: NoSQL-движки их просто эмулируют и могут выполнять очень медленно.
Можно выполнять более сложные выборки, но методом полного сканирования таблицы (table scan) и затем поэлементной фильтрации результатов на серверной стороне, что и долго и дорого.
- Транзакции: гарантируется лишь атомарное обновление отдельных сущностей. (Есть, правда, приятные возможности с чтениями/инкрементами за одну операцию). Так что транзакции придется эмулировать: данные разнесены по 20 серверам/дата-центрам всего земного шара.
- Атрибуты. Нередко в NoSQL, в том числе в DynamoDB можно использовать что-то типа:
user=john blog_post_$ts1=12 blog_post_$ts2=33 blog_post_$ts3=69
где $ts1-3 - таймстампы публикаций пользователя в блог. Это позволяет получить список публикаций за один запрос. Но работа программиста увеличивается.
Варианты подходов NoSQL
CA - согласованность данных (Consistency) и доступность (Availability)
Система, во всех узлах которой данные согласованы и обеспечена доступность, жертвует устойчивостью к распаду на секции. Если у вас интернет-магазин, сервера находятся в разных дата-центрах, и в какой-то момент один из серверов "упал", то система становится неработоспособной в целом.
Такие системы возможны на основе технологического программного обеспечения, поддерживающего транзакционность в смысле ACID. Примерами таких систем могут быть решения на основе кластерных систем управления базами данных или распределённая служба каталогов LDAP.
CP - согласованность данных (Consistency) и устойчивость к разделению (Partition tolerance)
Распределённая система, в каждый момент обеспечивающая целостный результат и способная функционировать в условиях распада, в ущерб доступности может не выдавать отклик. Данные пишутся на одну машину, дублируются на другую. Если одна "упала", то можно работать со второй. Устойчивость к распаду на секции требует обеспечения дублирования изменений во всех узлах системы, в этой связи отмечается практическая целесообразность использования в таких системах распределённых пессимистических блокировок для сохранения целостности
AP - доступность (Availability), устойчивость к разделению (Partition tolerance)
Распределённая система, отказывающаяся от целостности результата. Большинство NoSQL-систем принципиально не гарантируют целостности данных. �Задачей при построении AP-систем становится обеспечение некоторого практически целесообразного уровня целостности данных, в этом смысле про AP-системы говорят как о "целостных в конечном итоге" (eventually consistent) или как о "слабо целостных" (weak consistent). Наиболее распространённые системы.
Выводы
Прежде чем выбирать для проекта NoSQL хранилище, оцените все возможные призы и риски:
- NoSQL - это часто не что иное, как набор memcached-подобных серверов с надстроенной довольно простой логикой и, соответственно, сохранение данных и простые выборки будут действительно быстрыми. В случае более сложных запросов задачу придется решать на стороне приложения.
- Помните, что по теореме Брюера при реализации придётся выбирать не более двух из трёх свойств: согласованность данных, их доступность и устойчивость к разделению.
- Внимательно изучить документацию по используемому продукту, особенно ограничения, к которым нужно будет аккуратно подготовиться.
- NoSQL создает ложное впечатление, что можно не знать принципы работы SQL. На самом деле, нужно хорошо понимать классическую реляционную теорию, чтобы предвидеть развитие модели данных приложения в NoSQL, угадать варианты денормализации, чтобы приложение не пришлось потом несколько раз переписывать.
С помощью NoSQL вы получите очень надежное, высокодоступное, поддерживающее гибкие схемы репликации современное решение. Однако платить придется жесточайшей денормализацией и усложнением логики работы приложения (в т.ч. эмулировать транзакции, жонглировать тяжелыми данными внутри приложения и тому подобное).
