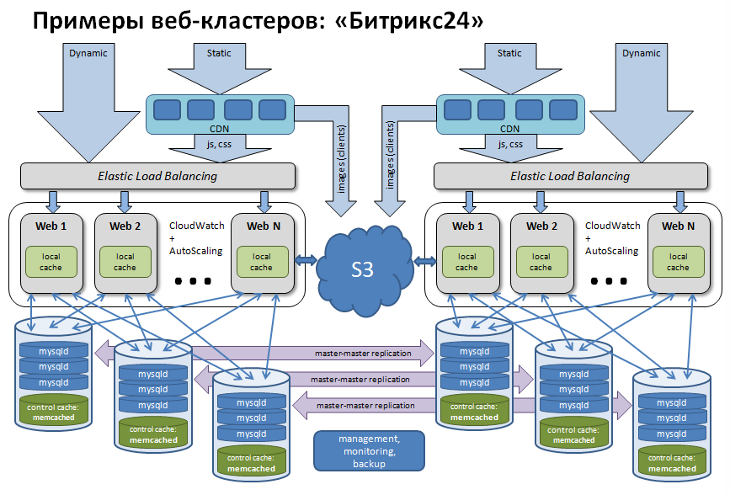
Архитектура облака Битрикса
Рассмотрим архитектуру сервиса Битрикс24 как пример реализации объемного проекта на базе Bitrix Framework.
В процессе разработки самой идеи сервиса было сформулировано несколько бизнес-задач:
- Первый тариф на Битрикс24 должен быть бесплатным, то есть себестоимость такого бесплатного аккаунта должна быть очень низкой.
- Сервис - это бизнес-приложение, и, значит, нагрузка на него будет очень неравномерной: больше днем, меньше ночью. В идеале оно должно масштабироваться (в обе стороны) и в каждый момент времени использовать ровно столько ресурсов, сколько нужно.
- При этом для любого бизнес-приложения крайне важна надежность: постоянная доступность данных и их сохранность.
- Сервис должен работать сразу на нескольких рынках: Россия, США, Германия.
Исходя из этих бизнес-требований сформировались два больших фронта работ:
- формирование масштабируемой отказоустойчивой платформы разработки,
- выбор технологической платформы для инфраструктуры проекта.
Платформа разработки Bitrix Framework
 | Традиционное устройство веб-приложений очень плохо масштабируется и резервируется. В лучшем случае возможно разнести по разным серверам само приложение, кэш и базу. Можно как-то масштабировать веб (но при этом необходимо решить вопрос синхронизации данных на веб-серверах). Кэш и база масштабируются уже хуже. А о распределенном гео-кластере (для резервирования на уровне датацентров) речь вообще не идет. |
Платформа "1С-Битрикс" включает в состав модуль Веб-кластер, который обладает следующими возможностями:
- Вертикальный шардинг (вынесение отдельных модулей на отдельные серверы MySQL),
- Репликация MySQL и балансирование нагрузки между серверами на уровне ядра платформы,
- Распределенный кеш данных (memcached),
- Непрерывность сессий между веб-серверами (хранение сессий в базе данных),
- Кластеризация веб-сервера,
- Поддержка облачных файловых хранилищ, которая решает проблему синхронизации статического контента,
- Поддержка master-master репликации в MySQL, позволяющая строить географически распределенные веб-кластеры.
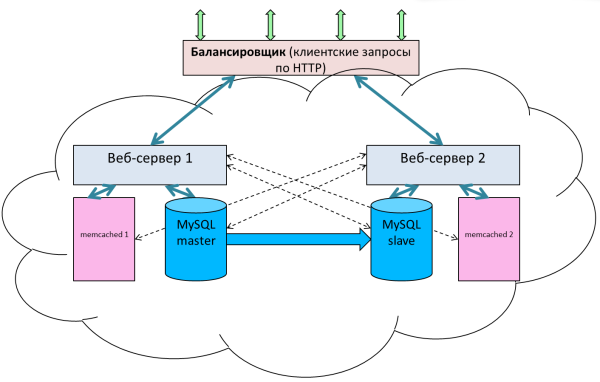
Модуль Облачные хранилища решает проблему синхронизации статического контента.
То есть штатные инструменты платформы Bitrix Framework позволяют без дополнительных усилий получить базовый функционал сервиса. То есть вопрос программной платформы был решён.
Платформа для разворачивания инфраструктуры
Собственное или арендуемое оборудование требует достаточно серьезных вложений в инфраструктуру на старте проекта. Масштабировать физические сервера достаточно сложно (долго и дорого). Администрировать (особенно в разных ДЦ) - неудобно. Кроме этого необходимо создание всех сопутствующих сервисов "с нуля".
На этапе старта невозможно максимально полно оценить те объемы регистраций, приток новых клиентов. Не хотелось покупать лишнее оборудование и переплачивать за него. Хотелось платить только за реальное потребление. Хотелось прийти к схеме, которая балансировалась не с пиками нагрузки в течение месяца, а в течение дня. Пик идёт днём: мы добавили нужное число машин, ночью отключили. В результате платим только за реальное потребление.
Поэтому было выбрано "облачное" размещение.
Сайты компании 1С-Битрикс работают в Amazon AWS достаточно давно. Это "облако" удобно тем, что есть множество уже готовых сервисов, которые можно просто брать и использовать в своем проекте, а не изобретать собственные велосипеды: облачное хранилище S3, Elastic Load Balancing, CloudWatch, AutoScaling и многое другое.
В очень упрощенном виде вся архитектура "Битрикс24" выглядит примерно так:

Каждый портал, заведённый в Битрикс24 имеет собственную базу внутри MySQL. На одном сервере может быть размещено до 30000 баз данных. Битрикс24, по сути, очень похож на shared hosting, когда на одном сервере размещено достаточно много баз данных клиентов, создающих разную нагрузку. В этих условиях очень важно обеспечить высокое качество работы для всех клиентов, которые там размещаются.
В такой архитектуре главный минус - избыточность приложения, это дорого по ресурсам.
Плюсы такой архитектуры
- Безопасное решение: каждый портал максимально изолирован друг от друга.
- Гибкое решение в плане обновления продукта: возможна выборочная установка обновлений в нужные "пакеты" порталов, можно вносить те или иные изменения в схемы данных по отдельным порталам, а не по всему проекту в целом.
Опытным путём выяснилось, что удобнее использовать 4 инстанса на одном сервере. И на каждый инстанс выделять по два отдельных диска, без Raid, один диск для данных, второй - для логирования. В итоге получается 8 дисков: 4 с данными, 4 диска под binlog'и. Такая конфигурация значительно лучше утилизирует ресурсы сервера, более эффективная нагрузка на каждый диск.
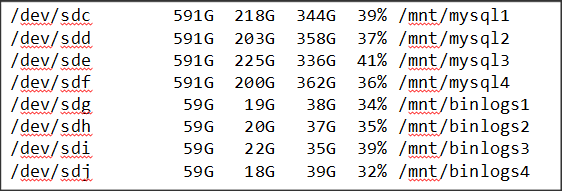
Вынос binlog'ов на отдельный диск вызван тем, что использование отдельного диска не затрагивает производительность дисков с данными. Это позволяет достаточно часто производить записи в лог, то есть логировать большее число параметров и действий.
Сам MySQL в плане производительности и эффективности работает с 30000 базами на 4-х инстансах лучше, чем на одном "большом" инстансе.
Автоматическое масштабирование
Приложение (веб) масштабируется в проекте не вертикально (увеличение мощности сервера), а горизонтально (добавление новых машин).
Для этого используется связка Elastic Load Balancing + CloudWatch + Auto Scaling. Все клиентские запросы (HTTP и HTTPS) поступают на один или несколько балансировщиков Amazon (Elastic Load Balancing). Рост и снижение нагрузки отслеживается через CloudWatch. AutoScaling добавляет и удаляет машины.
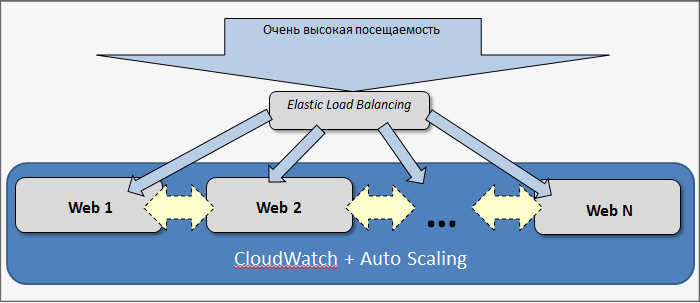
Есть две интересные метрики:
- состояние нод EC2 (% CPU Utilization). (Средняя нагрузка на сервера, которые участвуют в балансировке.)
- состояние балансировщика (время ответа от сервера latency в секундах).
В качестве основной характеристики используются данные о загрузке машин (EC2), так как latency может варьироваться не только из-за реальной нагрузки, но и по каким-то иным причинам: сетевые задержки, ошибки в приложении и другим. В таком случае возможны «ложные» срабатывания, и тогда крайне неэффективно будут добавляться новые машины.
В процессе разработки сервиса проводились долгие эксперименты с разными пороговыми значениями. В результате выбраны следующие: автоматически стартуют новые машины, если EC2 превышает 60% в течение 5 минут, и автоматически останавливаются и выводятся из эксплуатации, если средняя нагрузка менее 30%. Если верхний порог ставить больше (например, 70-80%), то начинается общая деградация системы - пользователям работать некомфортно (долго загружаются страницы). Нижний порог меньше — система балансировки становится не очень эффективной, машины долго могут работать вхолостую.

Специфика веб-нод
При проектировании возникло несколько задач, которые необходимо было решить:
- На веб-нодах не должно быть пользовательского контента, все ноды должны быть абсолютно идентичны.
- Read only. Никакие пользовательские данные не пишутся и не сохраняются на веб-нодах, так как в любой момент времени любая машина может быть выключена или стартует новая из «чистого» образа.
- При этом необходимо обеспечить изоляцию пользователей друг от друга.
Решилось это следующим образом: выбрана конфигурация без Apache. Есть только PHP-FPM + NGINX. У каждого клиента создаётся свой домен.И создан новый модуль для PHP который:
- проверяет корректность домена, завершает хит с ошибкой, если имя некорректно
- устанавливает соединение с нужной базой в зависимости от домена
- обеспечивает безопасность и изоляцию пользователей друг от друга
- служит для шардинга данных разных пользователей по разным базам
Статический контент пользователей
В описанной выше схеме веб-ноды по сути становятся «расходным материалом». Они могут в любой момент стартовать и в любой момент гаситься. А это значит, что никакого пользовательского контента на них быть не должно, он должен храниться либо в базе данных, либо в облачном хранилище. А на серверах должны в лучшем случае использоваться только временные файлы и директории.
Именно поэтому при создании каждого нового портала в Битрикс24 для него создается персональный аккаунт в Амазоне для хранения данных в S3. Тем самым данные каждого портала полностью изолированы друг от друга.
При этом само хранилище S3 очень надежно:
- Данные в S3 реплицируются в несколько точек. При этом – в территориально распределенные точки (разные датацентры).
- Каждое из устройств хранилища мониторится и быстро заменяется в случае тех или иных сбоев.
- Обычно данные реплицируются в три и более устройств – для обеспечения отказоустойчивости даже в случае выхода из строя двух из них.
- Когда вы загружаете новые файлы в хранилище, ответ об успешной загрузке вы получите только тогда, когда файл будет полностью сохранен в нескольких разных точках.
Амазон, например, говорит о том, что их архитектура S3 устроена таким образом, что они готовы обеспечить доступность на уровне двух девяток после запятой. А вероятность потери данных – одна миллиардная процента. Информации о потерянных данных в облаке Амазона пока ещё никто не обнародовал.
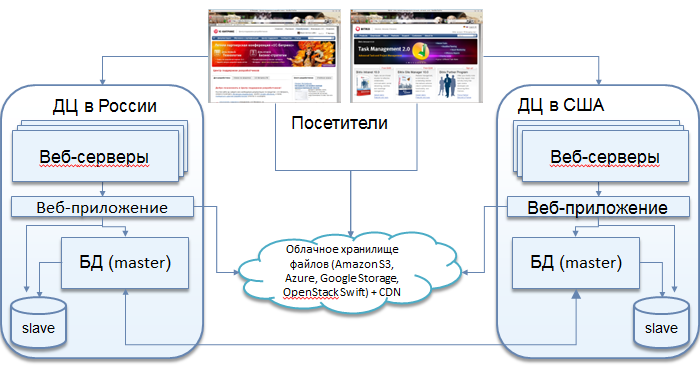
Два дата-центра и master-master репликация
Сервис Битрикс24 сейчас размещается в шести дата-центрах: по два в России, в Европе и в Америке. Этим решаются сразу три задачи: во-первых, распределяется нагрузка, во-вторых, резервируются все сервисы - в случае выхода из строя одного из ДЦ, траффик просто переключается на другой, в-третьих выполняются требования европейского и российского законодательства.
База в каждом ДЦ является мастером относительно слейва во втором ДЦ и одновременно слейвом - относительно мастера.
Важные настройки в MySQL для реализации этого механизма: auto_increment_increment и auto_increment_offset. Они задают смещения значений для полей auto_increment для того, чтобы избежать дублирования записей. Грубо говоря, в одном мастере - только четные ID, в другом - только нечетные.
Каждый портал (все зарегистрированные в нем сотрудники), заведенный в Битрикс24 в каждый конкретный момент времени работает только с одним ДЦ и одной базой. Переключение на другой ДЦ осуществляется только в случае какого-либо сбоя.
Базы в разных дата-центрах синхронны, но при этом независимы друг от друга: потеря связности между ДЦ может составлять часы, данные синхронизируются после восстановления.
Надежность
Одним из важнейших приоритетов при проектировании сервиса "Битрикс24" была постоянная доступность сервиса и его отказоустойчивость.
В случае аварии на одной или нескольких веб-нодах Load Balancing определяет вышедшие из строя машины и, исходя из заданных параметров группы балансировки (минимально необходимое количество запущенных машин), автоматически восстанавливается нужное количество инстансов.
Если теряется связность между дата-центрами, то каждый дата-центр продолжает обслуживать свой сегмент клиентов. После восстановления связи, данные в базах автоматически синхронизируются.
Если же выходит из строя полностью дата-центр, или же, например, происходит сбой на базе, то весь трафик автоматически переключается на работающий дата-центр.
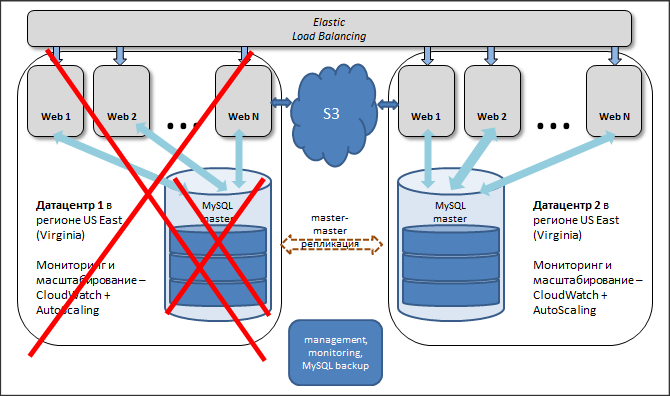
Если это вызывает повышенную нагрузку на машины, то CloudWatch определяет возросшую утилизацию CPU и добавляет нужное количество машин уже в одном дата-центре в соответствие с правилами для AutoScaling.
При этом приостанавливается мастер-мастер репликация. После проведения нужных работ (восстановительных - в случае аварии, или плановых - например, точно по такой же схеме был осуществлен переход со стандартного MySQL на Percona Server (см. далее) - при этом без какого-либо downtime'а для пользователей сервиса) база включается в работу и восстанавливается репликация.
Если все прошло штатно, трафик снова распределяется на оба дата-центра. Если при этом средняя нагрузка стала ниже порогового значения, то лишние машины, которые поднимались для обслуживания возросшей нагрузки, автоматически отключаются.
Базы данных
Для хранения данных в базе рассматривалось несколько разных вариантов.
Первым кандидатом на использование в проекте был Amazon Relational Database Service (Amazon RDS) - облачная база данных. Есть поддержка MS SQL, Oracle и, главное, MySQL.
Сервис хороший, но оказался неподходящим для конкретного проекта.
| Причины: |
|---|
- Система недостаточно гибкая и прозрачная. Например, отсутствие полноценного root-доступа к базе. А это значит, что какие-то специфичные настройки (для конкретного проекта), возможно, не получится сделать.
- Есть риск долгого даунтайма в случае какой-либо аварии. И практика показывает, что риск этот вполне реален. Да, чаще страдают те базы, которые расположены только в одной зоне, и для обеспечения отказоустойчивости можно использовать так называемые Multi-AZ DB Instances, но это оказалось не эффективно для проекта.
- При использовании Multi-AZ DB Instances для базы постоянно пишется standby бэкап в другую Availability Zone (AZ), и в случае аварии в первой зоне происходит автоматическое переключение на другую. Но в этом случае один инстанс с базой стоит ровно в два раза дороже. При этом пользователь эффективно использует ресурсы только одной машины (в отличие от схемы с мастер-мастер репликацией).
|
Рассмотрев еще несколько вариантов, было решено начать со стандартного MySQL. На этапе проектирования и закрытого бета-тестирования сервиса попутно рассматривались различные форки. Самими интересными, на наш взгляд, оказались Percona Server и MariaDB.
В итоге, в качестве основного сервера баз данных, для проекта была выбрана Percona Server.
Ключевые особенности, которые оказались важны для проекта:
- Percona Server оптимизирован для работы с медленными дисками. И это очень актуально для "облака" - диски там почти всегда традиционно медленнее (к сожалению), чем обычные диски в "железном" сервере. Проблему неплохо решает организация софтверного рейда (мы используем RAID-10), но и оптимизация со стороны серверного ПО - только в плюс.
- Рестарт базы (при большом объеме данных) - дорогая долгая операция. В Percona Server есть ряд особенностей, которые позволяют делать рестарт гораздо быстрее - Fast Shut-Down, Buffer Pool Pre-Load. Последняя позволяет сохранять состояние буфер-пула при рестарте и за счет этого получать "прогретую" базу сразу после старта (а не тратить на это долгие часы).
- Множество счетчиков и расширенных отчетов (по пользователям, по таблицам, расширенный вывод SHOW ENGINE INNODB STATUS и т.п.), что очень помогает находить, например, самых "грузящих" систему клиентов.
- XtraDB Storage Engine - обратно совместим со стандартным InnoDB, при этом гораздо лучше оптимизирован для высоконагруженных проектов.
Еще одним важным моментом было то, переход со стандартного MySQL на Percona Server вообще не потребовал изменения какого-либо кода или логики приложения.
В качестве системы хранения данных в MySQL была выбрана "улучшенная версия" InnoDB - XtraDB:
- На долгих запросах в MyISAM лочится вся таблица. В InnoDB - только те строки, с которыми работаем. Соответственно, в InnoDB долгие запросы в меньшей степени влияют на другие запросы и не отражаются на работе пользователей.
- На больших объемах данных и при высокой нагрузке таблицы MyISAM "ломаются". Это - известный факт. В нашем сервисе это недопустимо.