Настройка базы данных
Особенности работы с Базой данных заключается в том, что всегда приходится искать компромисс между быстротой и надёжностью. Либо будет быстро, но не надёжно, либо надёжно, но медленно, либо остановиться надо на каком-то среднем варианте.
Узкие места в работе с БД: CPU, RAM, Диск, то есть всё. Если чего-то не хватает, то их надо добавлять. В "облаке" используются медленные диски, однако так же как и на обычном сервере можно использовать программный RAID, что позволяет снимать все узкие места.
На платформе Amazon'а проводился эксперимент. Использовался одиночный диск, RAID10 из 4-х дисков и из 8-и дисков. При многопоточной загрузке больших файлов тесты sysbench показали что производительность RAID гораздо выше чем одиночного диска. На иллюстрации показана работа с одиночным файлом 16 Гб в режиме random read/write. При увеличении количества потоков единичный диск почти сразу достигает «потолка», производительность RAID растет.

Диагностировать проблемы можно стандартными инструментами: команды top (загрузка процессора и памяти), free (свободная память) и iostat –x 2 (что происходит с дисками, как они утилизированы, есть ли очередь из запросов и какое время обработки запросов).

Если памяти достаточно, то для временных таблиц MySQL лучше использовать именно память, создавая tmpfs, а для хранилища всех данных использовать RAID.
Использовать ли стандартный MySQL?
Можно использовать различные подсистемы хранения данных в СУБД MySQL, например Percona Server, который:
- Оптимизирован для работы с медленными дисками.
- Допускает быстрый рестарт базы (
Fast Shut-Down, Buffer Pool Pre-Load).
- Обладает богатым инструментарием внутренней диагностики (счетчики и расширенные отчеты).
- Использует XtraDB Storage Engine, лучше чем InnoDB и при этом совместим с ним.
- Использует XtraBackup, который используется для быстрого бинарного бекапа.
Другие подсистемы (MariaDB и другие) имеют свои преимущества. Выбирайте подходящую вам (или более знакомую вам) подсистему.
Сбалансированность БД, так же как и в случае с веб-сервом, должна быть максимальной. Оставить параметры по умолчанию - одна из частых ошибок. Другая ошибка - выбор значений параметров "на глазок", когда администратор не достаточно квалифицирован.
MySQL использует глобальные буферы и буферы для одного коннекта:
- Размер глобальных буферов: key_buffer_size + tmp_table_size + innodb_buffer_pool_size + innodb_additional_mem_pool_size + innodb_log_buffer_size + query_cache_size.
- Размер буфера для одного коннекта: read_buffer_size + read_rnd_buffer_size + sort_buffer_size + thread_stack + join_buffer_size.
Максимально возможное использование памяти: глобальные буферы + буферы подключений * максимальное число коннектов. Для подсчёта вручную можно взять нужные цифры из конфигов MySQL, либо воспользоваться утилитой mysqltuner.
Основная ошибка при настройке: конфигурация настроена на потребление памяти больше, чем есть в распоряжении виртуальной машины (сервера). Это означает, что при возросшей нагрузке, когда вырастет число соединений, запросы от БД будут просто "убиты" операционной системой по превышению. Именно поэтому значения нужно подбирать исходя из ваших потребностей и возможностей виртуальной машины (сервера).
InnoDB или MyISAM ?
На малых и средних невысоконагруженных проектах над выбором типа можно не задумываться. MyISAM достаточно быстрая, в ряде случаев быстрее чем InnoDB, при этом работать с ней проще. Но если проект нагружен, большой или требователен к надёжности, то нужно использовать InnoDB:
- При update и insert не будут происходить блокировка всех таблиц, а только тех записей, с которыми идёт работа в данный момент.
- В InnoDB гораздо больше инструментов для безопасности, надёжности и сохранения данных, транзакций.
- При должной настройке работает быстрее.
Как хранить базы и таблицы в InnoDB
Как хранить базы и таблицы: в одном едином файле ib_data или в разных файлах. По умолчанию всё храниться в едином файле. Если проект такой, что объём данных у него постоянно меняется (таблички создаются/удаляются, базы создаются/удаляются), то эти операции при хранении в одном файле выполняться будут быстро, но при этом команда DROP DATABASE не будет реально освобождать место. В итоге база дорастает до лимитов диска и нужно заново делать импорт/экспорт базы, чтобы сбросить этот файл, либо увеличивать диск, либо куда-то переносить данные.
Если все таблички хранятся в разных файлах (параметр innodb_file_per_table равен 1), то работать с ними, с точки зрения администрирования проще, DROP DATABASE реально удаляет данные, но в MySQL, к сожалению, это дорогая и тяжелая операция в силу ряда внутренних причин. Узким местом в этом случае станет процессор.
Поэтому надо оценить часто ли на проекте будут создаваться/удаляться базы данных, делаться реорганизация таблиц, выполнение ALTER TABLE и других подобных вещей, если нет, то смело используйте единый файл.
Скорость работы БД
Временные таблички хранить в памяти, а размер временных таблиц, если память позволяет лучше делать больше. До этого лимита временные таблицы не будут создаваться на диске, а будут в памяти.
# временные таблицы – в памяти
tmpdir = /dev/shm
# размер временных таблиц в памяти
max-heap-table-size = 64M
tmp-table-size = 64M
Используйте параметр skip-name-resolve, который позволяет отправлять чуть меньше DNS запросов.
Многие, видя, что в Bitrix Framework join'ов много, увеличивают параметр join-buffer-size, считая что он будет эффективно использоваться. Увеличение этого параметр не всегда полезно, так как это количество памяти, которые сразу же будет выделяться на запрос, не смотря на то, используются ли в нём индексы. Соответственно, увеличивая этот буфер можно просто съесть всю память в системе без какого либо увеличения эффективности.
Аналогично с параметром query-cache-size. Полезный инструмент, когда выполняется один и тот же запрос на не изменяющемся наборе данных, то результат выполнения попадает в кеш и очень быстро отдаётся из кеша при аналогичном запросе. При превышении кешем размера более чем, по эмпирическим данным, 500 мегабайт, этот кеш работает только хуже. Так как в этом случае возникают уже внутренние блокировки в самом MySQL. Это покажет SHOW PROCESS LIST, который выведет список запросов в состоянии waiting for query cache log.
При грамотно настроенном сервере и грамотно спроектированном приложении query-cache-size можно не использовать, либо использовать с небольшими значениями: 64 или 128 Мб. Если данных столько, что они вытесняют всю память из query cache, то есть смысл перемотреть логику приложения и структуры данных уже в самих таблицах.
Основная сущность в InnoDB - это buffer pool, где хранятся все структуры данных с которыми мы работаем. Всегда нужно стараться установить такое значение параметра, чтобы все данные с которыми мы работаем (или хотя бы "горячие данные") помещались в buffer pool. При этом не забывать про сбалансированность по памяти, не допускать того, что бы произошёл уход в swap.
Если buffer pool получается у нас достаточно большим, то эффективнее с точки зрения производительности использовать такой параметр как innodb_buffer_pool_instances. Это запуск нескольких buffer pool'а в MySQL. В этом случае БД работает с ними эффективнее процентов на 5-10%.
# желательно – по объему таблиц
innodb-buffer-pool-size = 4000M
# если buffer pool > 1Gb
innodb_buffer_pool_instances = 4
innodb_log_file_size = 512M
innodb_log_buffer_size = 32M
# на быстрых дисках; можно экспериментировать
innodb_read_io_threads = 16
innodb_write_io_threads = 16
innodb_io_capacity = 800
Основные параметры, на которые надо обращать внимание при работе с базой. Нужно уметь пользоваться командой SHOW ENGINE INNODB STATUS. Это позволяет видеть, что у нас происходит с InnoDB и buffer pool, обращая особое внимание на секцию BUFFER POOL AND MEMORY, где Buffer pool hit rate должен стремиться к 1, то есть все запросы должны обрабатываться из buffer pool, а не браться с диска.
Так же значение имеет секция TRANSACTIONS, где отображаются транзакции, которые выполняются долго, или висят, или откатываются, всё это показывает что с ними что-то не так.
Нужно уметь пользоваться командой SHOW STATUS \G, которая показывает что происходит с query cache, с временными таблицами.
Нужно уметь пользоваться командой SHOW PROCESSLIST, которая показывает текущие запросы.
Нужно включать логирование медленных запросов, что бы не думать и не гадать что у нас происходит в системе, какая страница тормозит и на чём именно она тормозит. Его легко найти (команда slow.log) и легко изучать (EXPLAIN). Однако из EXPLAIN'а не всегда понятно что же медленного происходит в базе.
Профилирование в БД
Если долгих запросов нет, но всё равно не понятно как работает БД: быстро, не быстро. Тут прежде всего надо определить критерии оценки.
После нахождения медленного запроса включается mysql> SET PROFILING=1;, выполняется запрос. Сохраняете профиль этого запроса и вы смотрите таймингами, что у вас в этом запросе происходило и что тормозило: передача по сети, оптимизация, проблемы на уровне SQL.
mysql> SHOW PROFILES;
+----------+------------+---------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------+
| 1 | 0.09104400 | SELECT COUNT(*) FROM mysql.user |
+----------+------------+---------------------------------+
1 row in set (0.00 sec)
В тестовом запросе самым долгим было Opening tables, дольше всего открывали таблицу с диска.
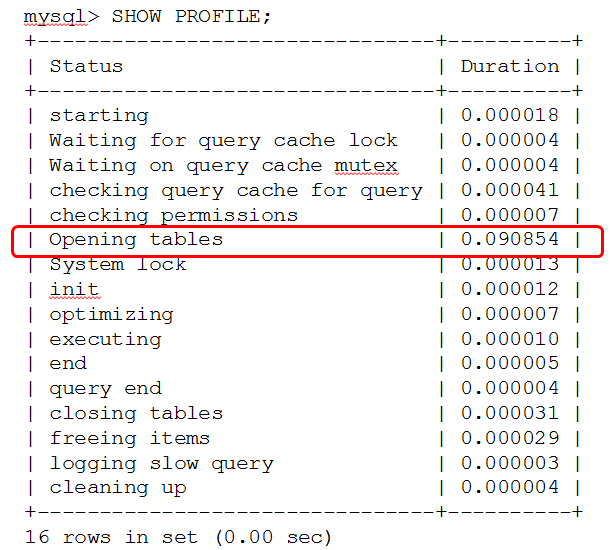
Профилирование - очень полезный инструмент, позволяющий понять что в базе может тормозить.
Если с базой всё хорошо (долгих одиночных запросов нет), то можно использовать mysql> SELECT * FROM INFORMATION_SCHEMA.QUERY_RESPONSE_TIME; (в стандартном MySQL такого нет, есть в расширениях, например в Percona Server). Это гистограмма времени запросов, которые выполняются с шагом в 1 порядок начиная с 0.000001 сек. Определите для себя критерии оценки. Например: соотношение быстрых и медленных запросов. Надо при этом определить что такое "быстрый" и что такое "медленный" запрос. Пусть быстрый будет тот, что выполняется быстрее, чем 0,01 секунды, а медленный - всё остальное. Если это соотношение - 2-3 %, то система функционирует нормально.
На больших проектах, где идёт большая работа с базой, где много обращений, такой инструмент очень удобен и показателен:
mysql> SELECT * FROM INFORMATION_SCHEMA.QUERY_RESPONSE_TIME;
+----------------+-------+----------------+
| time | count | total |
+----------------+-------+----------------+
| 0.000001 | 0 | 0.000000 |
| 0.000010 | 2011 | 0.007438 |
| 0.000100 | 12706 | 0.513395 |
| 0.001000 | 4624 | 1.636106 |
| 0.010000 | 2994 | 12.395174 |
| 0.100000 | 200 | 6.225339 |
| 1.000000 | 33 | 5.480764 |
| 10.000000 | 1 | 2.374067 |
| 100.000000 | 0 | 0.000000 |
| 1000.000000 | 0 | 0.000000 |
| 10000.000000 | 0 | 0.000000 |
| 100000.000000 | 0 | 0.000000 |
| 1000000.000000 | 0 | 0.000000 |
| TOO LONG | 0 | TOO LONG |
+----------------+-------+----------------+
14 rows in set (0.00 sec)
Как жить с большим количеством баз и таблиц?
Если позволяет логика приложения можно разделить одну установку mysqld на несколько и разнести данные по ним. Этот способ имеет смысл только при достаточном количестве ресурсов на физическом сервере (многоядерные системы, гигабайты RAM). Несколько установок лучше используют ресурсы, это проверено тестами.
Два теста с помощью sysbench: первым тестом грузим в 100 потоков одну установку; вторым тестом грузим параллельно 50 потоков на один инстанс, 50 потоков на второй. Во втором тесте в среднем получаем на 15% больше запросов в секунду.
Минус такого метода - некоторая сложность администрирования.
Описанное разделение не всегда можно использовать. Оно возможно, если на одном сервере работает несколько проектов и возможно логическое разделение по разным базам.
Несколько полезных советов по настройке
Один из полезных параметров - sync_binlog (особенно, если используется репликация). Это запись всех изменений базы, записанные в бинарный лог. Если важно, что бы репликация была надёжной и в случае падения какой-то машины у нас никакие данные не потерялись, то этот параметр должен быть выставлен в 1 (то есть запись ведётся постоянно). В обычном окружении такой значение кардинально снизит производительность базы. Но если sync_binlog вынести на отдельный диск, то его можно смело включать, производительность базы падать не будет.
# самый надежный
sync_binlog = 1
# hint: писать на отдельный раздел
log-bin = /mnt/binlogs/mysql/mysqld-bin
Формат binlog-format чаще используется mixed. MIXED фактически является псевдоформатом. Этот формат по умолчанию работает как STATEMENT. Но если в SQL запросе встречается функция, которая корректно логгируется только в ROW, то формат временно (в это запросе) переводится в него и после выполнения возвращается назад. Такое решение позволяет использовать преимущества одновременно обоих форматов STATEMENT и ROW.
binlog-format = mixed
Сброс логов buffer_pool'а - innodb-flush-log-at-trx-commit можно выставить в значении 2. В этом случае логи будут сбрасываться достаточно часто, но не на каждый коммит.
# сбрасываем log buffer на каждый commit, flush на диск –
# раз в секунду
innodb-flush-log-at-trx-commit = 2
Параметры sync_master_info, sync_relay_log и sync_relay_log_info существенно влияют на производительность. Для надёжности их надо выставлять в значении 1, но производительность упадёт. Можно установить значение 0, но надо иметь в этом случае опыт восстановления данных, возможности диагностики проблем другими средствами и всё равно понимать, что вы идёте на определённый риск.
Параметр max-connect-errors влияет на надёжность косвенным образом. По умолчанию у него стоит не высокое значение (10). Это параметр означает, что если с определённого хоста пришло 10 коннектов с ошибками, то этот хост блокируется до перезагрузки базы, либо ручного выполнения команды flush-hosts. Другим и словами, если возникла какая-то сетевая проблема между веб-сервером и базой (проблема частичная, например, коннект проходит, но не проходит авторизация, пакеты или ещё что-то), то после 10 попыток обратиться к базе хост блокируется. То есть проект перестаёт работать. Если на проекте нет мониторинга, то возникшая ночью такая проблема до утра сделает сайт неработающим.
Это глупая и мелкая ошибка и можно смело ставить это значение больше, которое позволит обойти такие мелкие сетевые проблемы, и проект будет работать.
Резюме по работе с БД
На производительность БД влияют:
- Все внутренние ресурсы системы, их нехватка, либо достаточность.
- Блокировки (таблицы, строки), если выполняются INSERT и UPDATE при работе с MyISAM
- Прочие блокировки ("waiting for query cache lock")
Мониторинг "узких" мест:
- Внешними инструментами мониторинг системы (nagios - в реальном времени, munin - аналитика).
- Смотрим логи медленных запросов: slow.log.
- Используем SHOW PROCESSLIST, SHOW STATUS, SHOW ENGINE INNODB STATUS.
Рекомендации:
- Используем InnoDB, а не MyISAM.
- Для дисков - лучше RAID
- Нужно больше памяти (в идеале вся база должна помещаться в buffer pool), но не в ущерб системе в целом (нельзя допускать ухода в swap)
- Использовать репликации (чтение - со slave’ов, запись - на master’е)
