|
|
Разработчикам |
Проектирование и управление разработкой сайта на платформе «1С-Битрикс: Управление сайтом»

Кратность связи «один-к-одному». Дискриминация
Отображение дискриминации в одну таблицу (инфоблок)Создаётся только одна таблица (инфоблок), в которую включаются все возможные атрибуты. Дискриминатором является выделенный атрибут. При этом их заполнение и обязательность контролируются программно (см. пример выше).
При использовании классических таблиц этот способ неэффективен (много пустых ячеек, слишком большие row-массивы, трудность программного контроля).
В случае Битрикса способ весьма эффективен: это обусловлено особенностями организации хранения свойств. Однако использовать его следует только в том случае, если уникальных свойств не очень много, а правила, определяющие, какие свойства есть у каких сущностей, просты. Иначе форма редактирования элемента будет просто огромной даже после её настройки, а код, контролирующий правильность ввода, может стать местом скопления ошибок.
Отображение дискриминации в N таблицСоздаются N таблиц (инфоблоков), как это было в самом начале. При этом каждая таблица (инфоблок) содержит как общие атрибуты, так и свои собственные. В роли дискриминатора выступает название таблицы (инфоблока).
Этот способ используется, когда сущности чаще используются по отдельности, чем совместно.
Когда же требуется совместное использование, программно происходит выборка сразу из нескольких таблиц (инфоблоков). Такие выборки называются объединением (в SQL им соответствует оператор UNION).
Более сложно организовывать хранение списка объектов, принадлежащих разным сущностям. Так, например, если у нас есть две таблицы: Мальчики и Девочки, и надо занести в отдельную таблицу список участников вечеринки, то потребуется в списке участников, помимо внешнего ключа, указывать также и признак (в данном случае – пол), по которому можно будет понять, из какой таблицы – Мальчики или Девочки – можно будет потом узнать имя и возраст участника.
В Битриксе для свойства типа «Привязка к элементу» можно легко указать, к элементу какого именно инфоблока должны делаться привязки. Или можно указать, что привязка может быть к элементу любого инфоблока. А вот ограничить список инфоблоков, к элементам которых может осуществляться привязка, увы, невозможно в режиме настройки инфоблока (для этого придётся воспользоваться обработчиками событий). Зато данный вариант очень удобен в плане вывода списков элементов на сайте. Для таких сущностей крайне удобно сделать компонент вида «список чего-нибудь», который потом помещать на главные страницы разделов с одинаковыми настройками (за исключением имени инфоблока-источника).
Отображение дискриминации в N+1 таблицуСоздаётся родительская таблица (инфоблок), которая содержит общие атрибуты и ссылку на строку дополнительной таблицы, а также N таблиц, содержащих только уникальные атрибуты каждой из сущностей. Дискриминатором является выделенный атрибут.
Этот способ идеологически наиболее «красив», поскольку все данные хранятся именно там, где должны.
Пользоваться «общей» частью удобно точно так же, как в первом варианте. А вот при использовании частных свойств всё не столь однозначно. Способ очень эффективен в случае классических таблиц, поскольку SQL предоставляет возможность делать выборку из главной таблицы и дополнять её столбцы столбцами дополнительной таблицы. Такие выборки называются соединением (в SQL им соответствует оператор JOIN). Поскольку число строк в основной таблице заведомо больше числа строк в каждой из дополнительных таблиц, такой JOIN практически всегда очень эффективен по производительности.
В Битриксе, к сожалению, в настоящее время нет полного аналога классическому JOIN, поэтому придётся делать отдельно выборки из главного и дополнительного инфоблоков. Так, если нужно, вывести список дисков из предыдущего примера с указанием длительности, придётся сделать одну выборку из основного инфоблока – и столько выборок из дополнительного инфоблока, сколько строк в первой выборке.
| Битрикс в текущей версии 8.5 позволяет немного абстрагироваться от этого, но физической сути явления это не меняет. Так, современное API получения выборок из инфоблоков позволяет делать выборки из связанных инфоблоков (подобно классическому JOIN), однако на уровне физического хранения данных эти выборки по-прежнему весьма тяжелы. | ||
Конечно, можно сначала загнать в массив список ID’ов выбранных элементов, а потом сделать один запрос к дополнительному инфоблоку, выдав этот массив в качестве $arFilter (именно так обычно и следует поступать). Но это дополнительное кодирование.
Ещё один минус данного подхода для Битрикса – крайне неудобный ввод данных через стандартный администраторский интерфейс (требуется сначала ввести информацию в дополнительный инфоблок, сохранить, затем ввести информацию в основной инфоблок, связать элемент основного инфоблока с дополнительным, сохранить). Поэтому такой подход однозначно предполагает создание отдельного интерфейса для редактора.
Зато такой способ значительно удобнее первого в тех случаях, когда много уникальных атрибутов или N велико.
Иногда этот способ применяют совместно с первым: в основную таблицу (инфоблок) включают также наиболее часто используемые частные атрибуты, а менее часто используемые помещают в дополнительные таблицы (инфоблоки). Это позволяет в большинстве случаев избавиться от JOIN (или дополнительных выборок), но зато приходится программно контролировать корректность заполнения атрибутов, включённых в основную таблицу (инфоблок).
Отображение дискриминации в 5 таблиц
Создаются:
- таблица с общими атрибутами,
- таблица со списком возможных значений дискриминатора «ID значения дискриминатора – наименование значения дискриминатора»,
- таблица видов свойств «ID вида свойства – наименование вида свойства»,
- таблица назначений свойств «ID вида свойства – ID значения дискриминатора» (в ней указывается, у какой сущности какие имеются свойства),
- и таблица значений свойств «ID элемента основной таблицы – ID вида свойства – значение свойства».
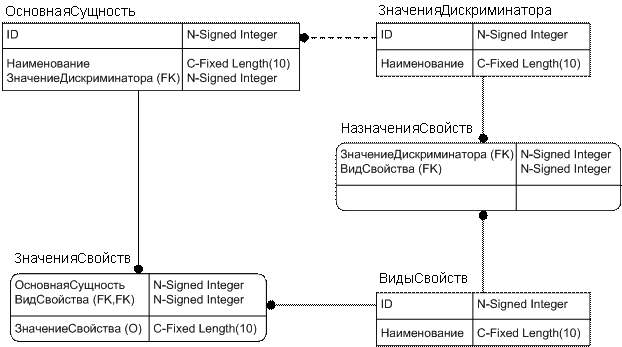
Этот вариант следует применять, если всё-таки оказалось, что список возможных значений дискриминатора не является конечным или конечен, но очень велик.
Этот способ весьма тяжёл для классических таблиц, поскольку SQL-запрос получается достаточно сложным (либо разбивается на несколько запросов).
| Однако он достаточно производителен для того, чтобы Битрикс применял его на физическом уровне платформы для хранения свойств инфоблоков. У этого решения могла бы быть альтернатива в виде второго или третьего способов с теми же достоинствами и недостатками. Существуют удачные примеры реализации этих способов, например, в платформе «1С:Предприятие». | ||
В Битриксе, если реализовывать его «в лоб» на уровне API инфоблоков, этот способ крайне неэффективен (и в плане удобства редактирования, и в плане производительности), и пользоваться им стоит только в самом крайнем случае. Поэтому описание этого способа мы приводим лишь для ознакомления.
| Дело в том, что в случае Битрикса невозможно нормально расставить индексы для быстрого сканирования инфоблоков видов, назначений и значений свойств, поскольку на уровне платформы они сами являются свойствами. | ||
Страница 10 - 10 из 12
Начало | Пред. | 8 9 10 11 12 | След. | Конец

