|
Пример отображения динамической схемы
|
|---|
 |
Разработка и эксплуатация высоконагруженных проектов
Содержание
Разработка проекта
Разработка высоконагруженного или сложного проекта серьёзно отличается от "типовой" работы по целому ряду параметров:
- наличия дополнительных этапов: прототипирование, например,
- более сложной и объёмной работы по написанию кода,
- необходимостью пересмотра подходов к архитектуре проектов,
- необходимостью созданию системы мониторинга,
- возможной необходимостью перехода с собственных разработок на какие-то фраймворки с целью сэкономить усилия на типовом функционале, которого нет в "загашниках" веб-студии,
- необходимостью освоения новых технологий, облачных, например.
Эти сложности могут привести к смене и стиля работы студии и технологии разработки, используемой до сегодняшнего момента.
В этой главе будут рассмотрены самые разные стороны процесса разработки сложного или высоконагруженного проекта.
Основные риски
Рассмотрим основные риски при работе с большими проектами:
Управленческие риски
Основной управленческий риск - это расхождение бизнес-целей и целей разработки, когда не найдено согласие между постановщиками задачи и теми, кому предстоит её решать.
К управленческим рискам можно отнести и организацию взаимодействия с заказчиком, организацию процесса производства в самой компании.
Детально управленческие риски рассмотрены в уроке Эффективная работа команды.
Риски проектирования
Забота о рисках проектирования лежит целиком на менеджере проекта. Это ещё один аргумент в пользу того, что им должен быть менеджер-технолог. Для уменьшения вероятности провала проекта необходимо составить "план управления рисками", который необходимо обсудить с клиентом. Для более точной оценки рисков необходимо провести тестирование на прототипе. Смоделируйте нагрузку и проверьте свои решения.
Типичные ошибки стратегии и тактики:
- Отсутствует видение системы: "Давайте начнем делать систему, а программисты придумают как это реализовать".
- При рассмотрении ТЗ менеджер проекта соглашается на любые модификации: ядра, админки, визредактора и т.п., в угоду бизнес-целям веб-студии.
- Менеджер проекта не уделяет проектированию и созданию прототипа должного значения.
- Вопрос производительности «закрывается» железом.
- Заказчик отказывается мыслить логически.
Чтобы избежать этих ошибок:
- При проектировании нужно разделить запрашиваемый заказчиком функционал на стандартный и нестандартный для используемой платформы.
- Проектировщик в деталях должен понимать, как реализовать стандартный функционал.
- Составьте логическую модель данных, глоссарий, кейсы использования. Растолкуйте их Клиенту.
- Сделайте Клиента участником проектной команды.
- Сделайте прототипы для снятия технических рисков (сложные технологии, нагрузка).
- Сделайте прототипы интерфейсов.
- Менеджер проекта должен вызубрить онлайн курсы по Bitrix Framework, если проект разрабатывается на Bitrix Framework.
Риски разработки
Риски разработки зависят от подготовки программистов, знания ими продукта, а также от стратегии и тактики разработки, выбранной менеджером проекта.
Типичные ошибки стратегии и тактики (убывание по важности):
- Не определена программная структура проекта.
- Отсутствует, либо реально не работает система контроля версий.
- Бесконтрольное программирование на ООП. Создаётся сложная иерархия для решения проблемы, которую можно решить одним скриптом. Нерациональное использование трудовых ресурсов для решения задач.
- Не используются инструменты отладки кода.
- Не регулируются права доступа на тестовых, боевых, девелоперских серверах: все сотрудники работают от root.
- "Секретные" объекты: агенты, обработчики, созданные самими разработчиками. Эти объекты могут быть недокументированы, располагаться где и как попало, что затрудняет дальнейший их поиск и отладку.
- Отправка транзакций на e-mail разработчику. Отключение этой нужной в ходе разработки функции может быть просто забыто.
- Отсутствие комментариев в коде.
- Лог-файлы размещаются в корне сайта.
Типичные ошибки при использовании собственно Bitrix Framework:
- Модификация ядра
- Прямые запросы в БД.
- Код пишется либо вне компонентов, либо в шаблонах компонентов. Объяснение: "так удобнее", вопреки идеологии Bitrix Framework.
- Настройки собственных, либо кастомизированных компонентов работают частично. После сдачи проекта им будет управлять администратор, и ему некогда, да и не должен он разбираться в собственно коде компонента.
- Огромные файлы кэша - не учтены все особенности кеширования. Встречается кеширование всего, что попало "под руку".
- Огромный init.php.
- Не оптимальное использование API Bitrix Framework, как правило, вызванное плохим знанием разработчиком API системы.
- Беспорядочный
/bitrix/php_interface/dbconn.php. - Обработчики событий переопределены везде, где можно, без комментариев зачем.
- Эксплуатационные параметры могут задаваться константами где угодно, на страницах, в компонентах, в классах модулей.
Информационная безопасность
Писать код "без дыр" крайне сложно и требует высокого профессионализма и большого опыта. Если в команде нет хотя бы одного такого высококлассного профессионала, способного проконтролировать написание кода остальными программистами, то использование Проактивной защиты должно стать для вас правилом.
API Bitrix Framework – защищено, написание кода в обход него всегда чревато если не текущими ошибками, то потенциальными проблемами, если вдруг обнаружится какая-то уязвимость.
Очень полезно использование сканера безопасности, который, конечно, не панацея, но позволяет выловить большинство ошибок.
Не забывайте перед сдачей проекта удалить тестовых пользователей, тестовые группы, тестовые файлы, лишние резервные копии. И обязательно использовать Монитор качества
Эксплуатация
Банально, но: для эксплуатации высоконагруженного проекта нужен хороший системный администратор, способный оптимально настроить сервер. Администратор не должен "забывать" делать резервное копирование, обновлять софт.
При эксплуатации проекта менеджер проекта не должен допускать ни ситуации, когда разработчики ходят на сервера под правами root'а, ни ситуации когда права закрыты настолько, что разработчики не могут посмотреть логи сервера.
Видео
Подводные камни разработки - чего делать нельзя
Программная архитектура веб-систем на Битриксе: от простого сайта до веб-кластера
Особенности проектирования под Битрикс
Сбор и анализ требований
Введение
Необходимый этап для любого проекта, но если в малых ещё можно что-то делать через постоянное обращение к клиенту: "делаем так?", то в случае большого или высоконагруженного проекта без проведения этого этапа в полном объёме реализовать проект невозможно.
Анализ требований действительно необходим, когда речь идет о больших сложных проектах со сроком разработки больше месяца. Необходимо вести предварительную работу, в которую входит настройка необходимых инструментов, налаживание связи с людьми заказчика, наиболее разбирающимися в сути вопроса, а также изучение самой предметной области сайта.
Цель этапа не создать юридический документ, а максимально полно зафиксировать требования клиента по проекту. На выполнение этого этапа не нужно выделять очень много времени. В зависимости от проекта от нескольких дней до пары недель.
В случае сложной предметной области, возможно, заказчик сам не может толком собрать такие требования. Часто клиент приходит к исполнителю с "кашей" в голове. Этап сбора и анализа требований в этом случае - это упорядочивание и формальная регистрация этой "каши". И согласование полученного с клиентом.
В случае больших и сложных проектов этап сбора и анализа требований рекомендуется проводить отдельным пунктом в договоре с отдельной сметой и оплатой. Это обезопасит как клиента, так и исполнителя от недобросовестных или непрофессиональных действий.
Требования
Требования делятся на функциональные и нефункциональные, то есть описывающие поведение системы (требуемую функциональность) и различные особенности поведения или эксплуатации системы, например, требования к удобству использования, надежности, производительности и тому подобное.
Функциональные требования - это пользовательские сценарии, которые должны быть реализованы в системе. Если они работают так как нужно клиенту, то эти требования выполнены.
Нефункциональные требования оформляются отдельно и должны учитывать экстремальные особенности которые должна выдерживать система. Одним из самых оптимальных способов выполнения нефункциональных требований на данный момент является использование веб-кластера, решающего задачи отказоустойчивости (дублирует несколько узлов), масштабируемости (можно добавлять сервера приложений и базы данных), надёжности (данные распределены по нескольким машинам).
Как проводить сбор и анализ требований
Сбор и анализ требований может быть (в случае больших и сложных проектов - должен быть) итерационным, пошаговым. В противном случае можно потерять очень много времени на данном этапе, для сложных систем (типа Softkey) - до года. В этом случае возникают свои риски: не учесть всего и встать перед необходимостью переделки.
Надо организовать с клиентом серию встреч в доверительной атмосфере. Клиент должен увидеть что вы не "отжимаете" деньги, а пытаетесь вместе с ним понять что ему нужно, решить его задачу эффективно, дёшево, быстро и максимально просто. Заказчик должен быть уверен, что он в любой момент может прийти, увидеть доступные документы по работе над его проектом. Это называется выстроить атмосферу Agile манифеста. В этом случае клиент будет максимально открыт, сообщать всё что он знает о проблеме.
Эта же мера позволит снизить риск формализации, когда стороны переводят общение в формат e-mail с целью фиксировать всё общение на случай непонимания и претензий. Такой подход сразу лишает стороны желания разбираться и понимать. Проектирование переходит в фазу юридических перестраховок, подстилания "соломки", что резко снижает вероятность удачной реализации проекта.
Без создания доверительной атмосферы возможны попытки клиента скрыть от разработчика бизнес-процесс и цели. Это когда задачи формулируются без разъяснения для чего это надо. Заказчик обрисовывает для себя проблему, но не зная принципов работы CMS и ее возможностей, придумывает решение, которое крайне сложно реализовать. А при этом эту же проблему можно решить совершенно иначе, например, проставлением галки где-то в админке. Но заказчик не объясняя для чего это надо, заявляет требование сделать именно то, что он придумал. В итоге разработчик тратит время впустую. Заказчик тратит деньги впустую.
Очень важно "качество" менеджера, занимающегося проектом со стороны исполнителя. Менеджер должен сам "прочувствовать и вжиться" в проект, должен научиться говорить с клиентом на его языке, на языке его предметной области, стать экспертом, "хранилищем знаний" для разработчиков. Менеджер должен научить предметной области ведущего разработчика или аналитика.
Методы и инструменты
Существует несколько методологий сбора и анализа требований. Существуют и разные инструменты сбора и анализа требований. Задача, которая стоит перед исполнителем - выбрать именно те методы и инструменты, которые подойдут к конкретному проекту. Максимально простые и эффективные методы и инструменты.
Есть несколько инструментов:
- Общий словарь терминов проекта. Например: "Ценовое предложение - это ...", "Цена - это ...", "Валюта - это..." и так далее. В этом случае, заказчик и исполнитель начинают говорить друг с другом на понятном языке. В больших проектах такой словарь может быть в несколько сотен терминов. В дальнейшем описание всех остальных документов ведется терминами словаря.
- Модель сущностей (классов) (Class\Object Diagram) определяем сущности системы:
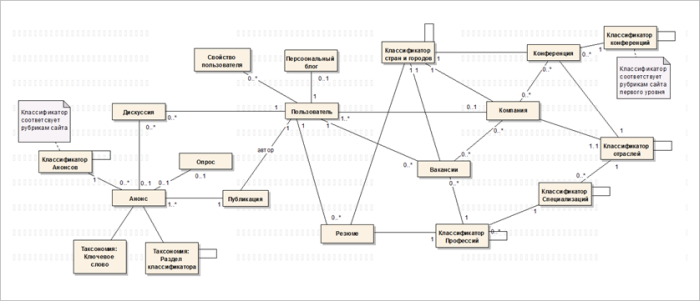
Это статическая модель. На неё переносятся термины из словаря и устанавливаются связи и отношения между сущностями. Здесь потребуется серьёзная логическая работа со стороны Клиента. Он должен показать и обосновать почему эта связь есть, откуда она берётся. На больших проектах таких диаграмм может быть несколько (встречается до 10) и каждая охватывает какую-то часть системы.
- Сценарии, Use Case или User story - динамическая модель системы. Описание поведения пользователей с определёнными ролями в системе.
В простом случае описываются просто цепочки действий, в более формальных случаях сложных предметных областей лучше использовать формат Сценария поведения.
- Story map - Упорядоченная карта выявленных требований. Расстановка приоритетов в выявленных требованиях: более срочные, главные и понятные пишутся наверху, менее важные, менее приоритетные, менее понятные - пишутся внизу.
Если требуется более глубокая проработка требований (это может потребоваться когда в проекте появляются какие-то алгоритмы вычисления, шифровки, работы банкоматов, корзины), то используются:
- Диаграмма деятельности (Activity Diagram) для "окольцовки" блок схем логики.
- Диаграмма состояний (State machine diagram) для описания состояний конечных автоматов, когда система может ходить между статусами. (Например, заказ в интернет-магазине.)
- Диаграмма последовательности (Sequence diagram) для упорядочивания по времени взаимодействия объектов (редко используемая диаграмма).
- Технические спецификации обмена данных – структура файлов импорта-экспорта и тому подобное.
Примечание: В ряде случаев возможно использование других видов UML диаграмм. Главное: выбрать диаграмму максимально удобную для вашего конкретного случая.
Возможно вам ещё понадобится "картинка" того, как вы будете размещать всё на серверах: Диаграмма развёртывания Deployment Diagram.
|
Пример диаграммы развёртывания
|
|---|
 |
Возможна ситуация, когда требование озвучено, но не понятно ни клиенту, ни исполнителю. Это не страшно. Его надо зафиксировать не описывая. Впоследствии к нему можно вернуться.
Работа по сбору, формализации и структурирования требований не требует каких-то сложных и дорогих программных инструментов. Всё можно выполнять в обычном Excel.
Риски
Основные риски при сборе и анализе требований:
- Риск непонимания задачи, приводящий к переусложению системы. Нужно стремиться к простоте, использовать только нужное.
- Риск "невовлечённости" Клиента. Непонимание клиентом необходимости сбора и анализа требований приводит к провалу проекта. Клиенту может быть выгодно не иметь формализованного и согласованного списка требований. В этом случае он может "давить" на исполнителя, требуя выполнения работ, ранее не предусмотренных.
Иногда проблема возникает при недобросовестности, либо некомпетентности менеджера клиента, ведущего проект. Решение: требовать от клиента адекватного и добросовестного сотрудника.
- Риск формализации, когда слишком много времени и сил уходит на полную формализацию требований.
Критерии завершённости этапа
Сбор требований - сложный этап, который крайне сложно завершить в один заход. Как правило, Клиент не может сразу высказать все свои "хотелки". Это процесс долгий в силу того, что осознание потребностей приходит в результате постоянного контакта клиента с исполнителем, в результате итерационной реализации уже сформулированных заданий.
Переход к этапу проектирования можно выполнять после получения некоторых документов из перечисленного выше списка, достаточных для осознанного начала работ по проектированию. Риск возникновения каких-то не выявленных требований, незадекларированных сущностей при этом существенно снижается.
Прототип
На этапе сбора требований стало примерно понятно чего хочет клиент. Следующий шаг: создание прототипа.
Прототипи́рование (англ. prototyping) - быстрая "черновая" реализация базовой функциональности для анализа работы системы в целом. На этапе прототипирования малыми усилиями создается работающая система (возможно неэффективно, с ошибками, и не в полной мере). Во время прототипирования видна более детальная картина устройства системы.
Для чего делается прототипирование? Нужно проверить идею. Этап необходимый, так как позволяет оценить возможные риски, показать границы возможностей реализуемой идеи, выявить возможные сложности в реализации.
Примеры задач, где требуется создание прототипов.
- В магазине планируется 1 000 000 ценовых предложений, проект должен работать. Можно делать проект, заносить данные, но потом может выясниться, что система не сможет держать такую нагрузку.
Заливается 1 000 000 ценовых предложений на один сервер и проверяется как работает административная часть, как работает публичка, выбирается способ хранения данных (в случае Bitrix Framework: инфоблоки, инфоблоки 2.0 с индексами или Highloadblock), выбирается База данных и так далее.
- Внедрение какой-то сторонней системы в уже существующую. Например, Sphinx в Bitrix Framework. Необходимо изучить детали обоих систем, которые могут вызвать проблемы при взаимодействии. И проверять их.
- Раздача с сайта в 100 потоков 100 фильмов. И сделать это на одном сервере. Поднимается сервер и запускается аналогичная нагрузка. Оказалось, что выдерживает только 10 потоков.
- Использование какой-то библиотеки. Например, архивирование файлов: сжать файл, зашифровать, положить на удалённый сервер. В результате обнаружены ошибки в самом PHP, утечки памяти в библиотеке, незаметные в обычной жизни. На больших нагрузках это приведёт к неблагоприятным последствиям.
Для создания прототипа нужен опытный программист, способный увидеть технологические риски реализации конкретной задачи. Хотя прототип принесет немалую пользу и для начинающей команды: прежде всего убережёт от ошибок, связанных с отсутствием опыта работы с той или иной технологической платформой.
Прототип надо обязательно проверять на высокие нагрузки.
На работу с прототипом уходит не более двух-трёх дней и в случае положительного отзыва можно приступать к работе. В противном случае нужно предложить клиенту альтернативные варианты решения его задачи.
Архитектура проектов
Архитектура проекта
Архитектура проекта - набор сервисов и серверов, настроенных и связанных определенным образом в целях обеспечения требуемых характеристик производительности и отказоустойчивости.
Самый простой в реализации пример архитектуры - это двухуровневая конфигурация веб сервера. Однако она применима только к несложным и ненагруженным (по нынешним меркам) проектам.
Для сложных и высоконагруженных проектов одной двухуровневой схемой не обойтись, нужен отдельный этап в разработке проекта: проектирование архитектуры.
Что бывает если нет архитектурного проектирования? Программисты начинают писать код на своё усмотрение, часто даже не согласовывая друг с другом. Если в компании слабая техническая вертикаль, не контролируют работу программистов ни технический директор, ни ведущий разработчик, то получается усложнённый код, так как у программистов нередко встречается желание "прокачаться" за счёт компании.
Если чёткого проектирования нет, а программисты слабо знакомы с предметной областью (а чаще вообще не знакомы), то часто выясняется, что сделано не совсем то или совсем не то. Требуется переделка, которая требует времени и может рождать дополнительные баги. Такой цикл может повторяться несколько раз, пока не подойдёт срок сдачи проекта. Как правило именно в этот момент до всех разработчиков доходит что нужно было на самом деле сделать, но времени уже нет.
Исполнитель пытается сдать то, что сделано, что непонятно как работает. Иногда это удаётся. Но если и удалось, то при попытке что-то поменять всё "рассыпается".
Что необходимо учитывать при архитектурном проектировании
- TDD не применимо в разработке сайтов. Слишком сложно и слишком трудоёмко. Вёрстка, например, вообще не поддаётся автоматическому тестированию. Но этот метод может принести немалую пользу при разработке кастомных модулей и библиотек для сайта.
- ООП - требует подготовленных специалистов. Есть мнение, что ООП-программист - это вообще программист особого типа, им надо родиться. Если нет соответствующего опыта, то создавать проект с активным использованием ООП не рекомендуется, так как будет создан сильносвязанный и слабоуправляемый объектный "зоопарк".
- Использование фреймворков и библиотек, хотя и является оптимальным вариантом для большинства проектов, тоже представляет собой определённый риск при недостаточной подготовке команды и при отсутствии технического контроля со стороны ведущего разработчика.
Бесплатные фреймворки не гарантируют преемственности своих разработок. Разработчики могут просто начать вести новую ветку, приостановив поддержку старой, а для клиента это означает либо возрастание риска уязвимости (если оставаться на старой ветке), либо большие вложения (если переводить работу проекта на новую ветку фреймворка).
Материалы по теме
- Доклады на конференции FailOver Conference Украина
- Разработка сложного высоконагруженного проекта без SQL
- Контейнерная виртуализация для растущих проектов
Виды архитектур
Самые распространённые виды архитектур
PHP-FPM + nginx
Наиболее простым и логичным решением по изменению архитектуры проекта являются следующие этапы "эволюции":
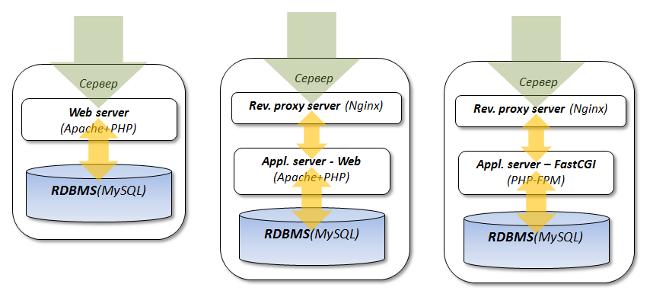
Переход к последней схеме позволяет в будущем проще и легче масштабировать проект и достичь более высокой производительности.
PHP-FPM – более эффективное решение:
- Исключен лишний веб-сервер.
- Меньший расход памяти [ds]форками[/ds][di]
Форк (fork с англ. — «развилка, вилка») или ответвление — использование кода программного проекта в качестве старта для другого, при этом основной проект может как продолжать существование, так и прекратить его.
Подробнее...[/di]. - Меньшее использование CPU и системных вызовов.
- Связка nginx – Apache использует TCP/IP, что ведет к накладным расходам.
- Связка nginx – PHP-FPM использует Unix domain socket, что быстрее.
Разнесение приложений
Дальнейшим логическим развитием схемы является разнесение всех "приложений" на отдельные серверы:
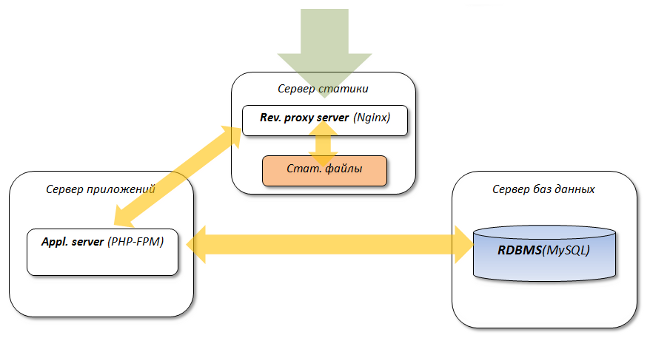
Это позволяет значительно поднять общую производительность системы.
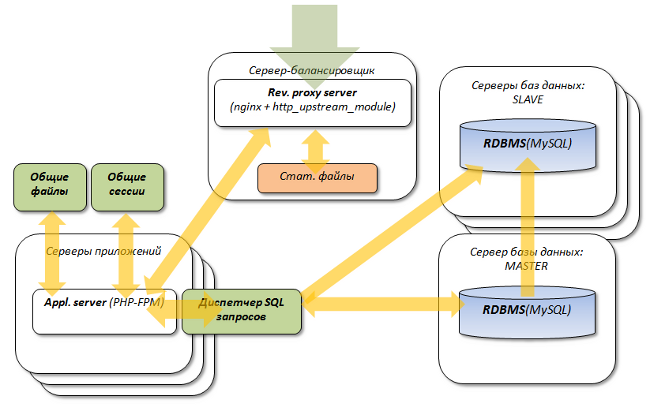
Кластеризация
След этап развития архитектуры проекта:
- Масштабирование серверов приложений;
- Master-Slave репликация базы данных с масштабированием slave-серверов;
- Балансировка нагрузки.
Интернет-магазины, высокие нагрузки
Общие сведения
Достаточно сложной категорией веб-проектов являются интернет-магазины. Для разработки магазина вам необходимо разбираться в следующих ключевых сущностях Bitrix Framework, используемых при его проектировании:
- модуле Информационные блоки;
- модуле Интернет-магазин;
- модуле Торговый каталог;
- модуле Валюты;
- вопросах авторизации.
Бывают такие ситуации, когда интернет-магазин (например, магазин некоторых услуг) может обойтись без модуля Торговый каталог. Поэтому перед началом разработки необходимо сразу определиться нужен ли вам данный модуль.
Если в магазине представлены каталоги товаров, то модуль Торговый каталог должен быть изучен очень тщательно. Прежде всего вам необходимо спроектировать ценообразование: определиться какие типы цен будут использоваться и в каких валютах. Также необходимо заранее решить какой курс валют будет использоваться, как он будет браться и обновляться, как вы будете его округлять (если делать будете это сами). При проектировании структуры каталога товаров следует заранее продумать будут ли использоваться у вас торговые предложения, наборы и комплекты. Кроме того, модуль Торговый каталог позволяет настроить гибкие системы скидок. Даже, если возникнет ситуация, что вам требуются скидки, которых нет в Bitrix Framework, то разрешить ее можно с помощью API Bitrix Framework, написав собственные обработчики.
Модуль Интернет-магазин позволяет сделать:
- Корзину. Она позволяет изменять свойства ее позиций, при этом цена изменяется динамически. При разработке корзины необходимо понимать, что корзина - это отдельная сущность. То, что находится в корзине, это уже не элементы каталога, это уже записи корзины.
- Мастер заказа. Необходимо понимать как работать с типами плательщиков, как интегрировать платежные системы и работать со свойствами заказа. Кроме того, следует предусмотреть возможность быстрого заказа.
- Персональный раздел. Когда клиент сделал заказ, то он должен видеть подробную информацию по своему заказу, список всех заказов, кнопку Повторить заказ, список подписок на товары и т.п. В зависимости от структуры вашего магазина, возможно, необходимо выводить клиенту список оплат, информацию по его лицевому счету (при наличии), пластиковым карточкам.
- Административную часть по обработке заказов. Необходимо спроектировать статусы заказа, продумать работу менеджеров магазина. Полезно также создавать и использовать кастомизированные формы административной части магазина.
Если ожидается, что проект будет большим, то к нагрузкам необходимо готовиться сразу. На этапе разработки следует выполнять аудит кода и оптимально использовать API Bitrix Framework, необходимо смотреть, чтобы не делались лишние запросы к базе. Кроме того, следует тщательно проектировать модели данных. Таким образом, следует использовать инфоблоки 2.0, в которых можно добавлять кастомные индексы.
Следует аккуратно работать с кешем: нельзя все кешировать. Проверяйте страницы так, чтобы они без кеша работали быстро, только потом включайте кеш, а не наоборот.
Что касается конфигурации, то настройте прекомпилятор PHP и анализируйте, что в него попадает. Проверьте в мониторе производительности, чтобы были включены все требуемые настройки PHP. Помимо этого, следует вести контроль версий и логи. Поскольку смотреть запросы - это задача программиста, то необходимо научиться понимать состояние базы данных. При работе используйте разного рода отладчики, Xdebug, XHPprof. Кроме того, рекомендуется использовать PHP-FPM для крупных проектов, потому что расходуется меньше памяти, выполняется меньше tcp/ip соединений.
Высокие нагрузки
Допустим, что магазин уже разработан и запущен. Рассмотрим теперь простую и эффективную стратегию достижения и поддержки высокого уровня качества обслуживания посетителей интернет-магазина.
Фиксация обращений в логах
Для веб-проектов с посещаемостью в единицы миллионов хитов в сутки нужно настроить логирование всех обращений клиентов как к страницам, так и ресурсам. Важно понимать, что система может сохранять информацию о каждом обращении клиента и включить эту возможность очень просто (это штатное средство). Если интернет-магазин развернут на веб-кластере, то несложно настроить удаленное логирование на выделенный для этих целей сервер с использованием, например, syslog-ng. Логирование всех запросов клиентов незначительно (всего на несколько процентов) снижает производительность конфигурации, однако вы сохраняете полную информацию и контроль над качеством обслуживания клиентов. Практически все случаи ошибок и зависаний интернет-магазина фиксируются, доступны для дальнейшего анализа и корректировки процесса разработки и системного администрирования. Если логирование не настроено, то можно сказать, что вы не контролируете ситуацию.
Прежде всего нужно модифицировать стандартный формат логов NGINX, Apache, PHP-FPM и добавить туда описанные ниже ключевые показатели производительности. Кроме стандартных данных (таких как URL запроса, код ответа и т.п.), важно фиксировать по каждому хиту следующие данные:
- Время выполнения запроса: для NGINX это "$request_time", для Apache - "%D", для PHP-FPM - "%{mili}d". Кроме того, при двухуровневой конфигурации NGINX+Apache или NGINX+PHP-FPM полезно зафиксировать в логе NGINX также "$upstream_response_time".
- Пиковое использование памяти при обработке запроса. Если вы используете PHP-FPM, полезно сохранить в логе "%{bytes}M".
- Код HTTP ответа. Обычно код HTTP ответа сохраняется в логах по умолчанию. Важно сохранять эту информацию, т.к. ошибки в обслуживании клиентов, как правило, имеют код ответа 40х или 50х.
- Отдельные логи производительности и настройки логов. Иногда удобно создавать отдельные логи, сохраняющие информацию о времени отработки скрипта и пиковом использовании памяти. Можно использовать такие опции:
- для nginx:
log_format main '$remote_addr - $remote_user [$time_local] "$host" "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for" -> $upstream_response_time';
- для apache:
LogFormat "%t \"%r\" %>s %b child:%P time-> %D" timing
- для php-fpm:
access.format = "%R # %{HTTP_HOST}e # %{HTTP_USER_AGENT}e # %t # %m # %r # %Q%q # %s # %f # %{mili}d # %{kilo}M # %{user}C+%{system}C"
- для nginx:
Анализ логов
Процесс фиксации информации об обращении клиентов в логах организован, все ошибки попали в лог. Теперь необходимо научиться их трактовать и инициировать устранение причин их появления.
Для начала рассмотрим самые распространенные типы ошибок:
- В случае ошибок в коде, прекомпиляторе (Segmentation Fault) или в операционной системе как правило отдается статус 500 (Internal Server Error). В этом случае посетителю показывается страница с сообщением о регламентных работах, либо (если не настроено) техническое сообщение об ошибке.
- Во время перегрузки Apache или PHP-FPM в двухуровневой конфигурации (долгие запросы к БД либо в коде идет обращение к внешнему сокету, либо число процессов Apache/PHP-FPM не соответствует реальной нагрузке) front-end (NGINX) зафиксирует в своих логах превышенное время отдачи страницы back-end'ом или ошибки 502 Bad Gateway, 504 Gateway Timeout. В этом случае, если не используется балансировщик нагрузки, посетителю, как правило, показывается страница о регламентных работах. При использовании балансировщика (например, upstream в NGINX) время отдачи страницы клиенту просто увеличится (что также будет зафиксировано в логах).
- При превышении скриптом PHP памяти в лог попадет ошибка 500 (Internal Server Error).
Теперь на примерах проанализируем, что происходило с обслуживаем клиентов магазина за сутки:
- Допустим, имеется следующая гистограмма HTTP-ответов на front-end'е и back-end'е:
Total hits: 265532 200 : 264654, 99.67% 207 : 34, 0.01% 302 : 830, 0.31% 401 : 7, 0.00% 403 : 1, 0.00% 404 : 1, 0.00% 500 : 16, 0.01%
Мы видим, что более 99% хитов были успешны (код 200), однако было 16 ошибок, с которыми нужно разбираться разработчикам (в логах PHP) и искать способы их устранения. - Гистограмма времени выполнения страницы на front-end'е и back-end'е следующая:
Total: 386664 0 ms: 276203, 71.43% 100 ms: 81466, 21.07% 200 ms: 13155, 3.40% 300 ms: 4282, 1.11% 400 ms: 2183, 0.56% 500 ms: 1373, 0.36% 600 ms: 968, 0.25% 700 ms: 721, 0.19% 800 ms: 586, 0.15% 900 ms: 470, 0.12% 1000 ms: 398, 0.10%
Видим, что подавляющее число запросов клиентов было обслужено со временем менее 500 ms. Однако с 398 хитами более секунды нужно основательно разбираться. Страницы или сервисы могут отрабатывать единицы секунд в следующих случаях:- Не используется кеширование результатов обращений в базу данных либо само обращение в базу данных не оптимизировано.
- Выполняется тяжелый аналитический запрос, например, число заказов такого-то товара за такой-то период. В этом случае ошибки нет, такой запрос лучше исключить из анализа.
- В коде скрипта идет обращение к внешнему ресурсу, который завис (RSS-лента, внешняя авторизация и т.п.). Общее правило в таком случае: обращаться к подобным «рискованным» внешним ресурсам либо в отдельном потоке (cron), либо асинхронно из браузера клиента по ajax, кешируя результаты ответа. Таким образом, даже если внешний ресурс недоступен, то веб-страница должна отдаться посетителю быстро, менее чем за секунду (и аккуратно догрузить части страницы).
- Гистограмма потребления скриптами памяти на back-end'е - PHP-FPM:
Total hits: 265562 0 KB: 25, 0.01% 4000 KB: 16, 0.01% 6000 KB: 67094, 25.26% 7000 KB: 123746, 46.60% 8000 KB: 61102, 23.01% 9000 KB: 3453, 1.30% 10000 KB: 1263, 0.48% 11000 KB: 890, 0.34% 12000 KB: 826, 0.31% 13000 KB: 917, 0.35% 14000 KB: 1129, 0.43% 15000 KB: 1125, 0.42% 16000 KB: 936, 0.35% 17000 KB: 798, 0.30% 18000 KB: 631, 0.24%
Видно, что большинство скриптов веб-решения потребляют 6-8 МБ памяти, что немного. Однако, нередко при разработке «в сжатые сроки» получаются скрипты, которые потребляют 500МБ или единицы гигабайт памяти, что вызывает зависание сервера и общую дестабилизацию системы. Важно анализировать данную гистограмму и ставить ТЗ разработчикам на оптимизацию объема потребляемой страницами памяти в пределах, допустим 64 МБ. Таким образом, постепенно, система будет потреблять стабильно предсказуемый объем памяти и вы будете уверены, что она внезапно не впадет «в спячку» на несколько десятков минут.
Кроме того, используя для логов соответствующие bash/awk-скрипты, полезно также получить статистику по максимальным значениям: топу самых медленных страниц в сутки и топу самых затратных по памяти страниц в сутки. А также если вы используете PHP-FPM, то можете получить более подробную информацию о зависания PHP-скриптов с помощью специальной возможности логирования скриптов, которые выполняются более N секунд.
Таким образом, настроив сбор ключевой статистики по хитам клиентов интернет-магазина, нужно создать постоянно действующий бизнес-процесс по доработке и оптимизации веб-решения: раз в сутки статистика должна рассылаться всем участникам технологического процесса и при превышении заранее оговоренных показателей автоматически должен начинаться поиск, устранение ошибок и/или оптимизация кода веб-проекта. В качестве целевых критериев можно взять:
- число показов клиентам страницы о регламентных работах (т.е. число ошибок 50х): 0;
- число хитов в публичной части, обслуженных быстрее 0.5 секунды: 100%;
- число хитов в административном разделе (где могут выполняться «тяжелые» аналитические выборки): быстрее 10 секунд - 100%, среднее время хита в админке - 0.5 сек;
- максимальный объем памяти, использованный скриптом: менее 128МБ, средний объем - 32МБ.
Программная архитектура высоконагруженных веб-систем
Традиционное устройство веб-продуктов
Стандартное веб приложение работает на одном сервере: собственно веб-сервер, кеширование, база данных приложения. Достаточно часто ресурсов сервера перестаёт хватать и приходится переходить на новый тарифный план или производить апгрейд сервера. Это первый шаг в долгом процессе - вертикальное масштабирование, когда добавляются ресурсы сервера. Рано или поздно происходит упор в ограничение возможностей либо хостинга, либо "железа".
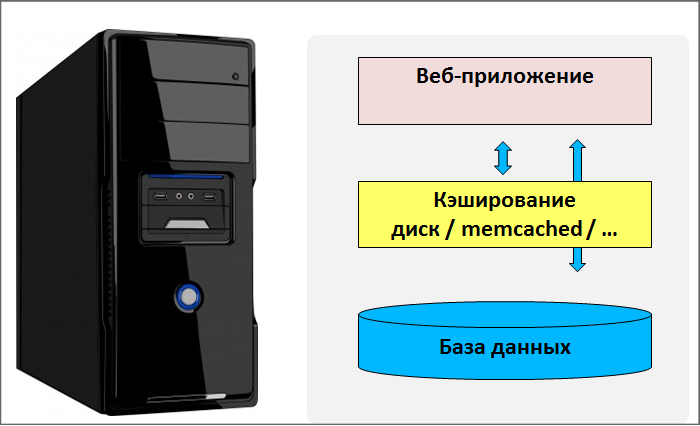
Следующий шаг - разделение приложения, когда приложение делится на составные части (web, БД, кеш) и эти части работают на разных серверах. С точки зрения производительности большинству проектов бывает достаточно такого разделения. Однако такое деление не решает задачу надёжности и отказоустойчивости. Каждый узел не зарезервирован и в случае выхода из строя любого из них перестаёт работать весь проект в целом.
Следующий логический шаг - научиться масштабировать дальше. Научиться представлять любой узел системы в виде кластера серверов, которые будут взаимозаменяемы, и в случае аварии проект продолжит работу. На этом этапе возникают сложности: просто так добавить несколько серверов под БД, несколько серверов под web уже становится сложно, потому что приходится значительно переписывать, перерабатывать логику веб-приложения.
Основные задачи, которые решает веб-кластер - это задача производительности и задача отказоустойчивости:
- Обеспечение высокой доступности сервиса, так называемые HA (High Availability или Failover) кластеры.
- Масштабирование веб-проекта в условиях возрастающей нагрузки (HP - High Performance кластеры).
- Балансирование нагрузки, трафика, данных между несколькими серверами.
- Создание целостной резервной копии данных для MySQL.
Как представить своё приложение в виде кластера
Введение
Когда переходы на новый тарифный план или апгрейд "железа" сервера перестают решать проблемы производительности (либо становятся чрезмерно дорогими), то направление развития приложения одно: переход на кластерные технологии.
Решать задачу представления приложения в виде кластера можно с помощью следующих технологий, которые позволяют масштабировать базу данных, кеш, web и представить каждую из составляющих в виде группы взаимозаменяемых серверов:
- Вертикальный шардинг (вынесение модулей на отдельные серверы MySQL).
- Репликация MySQL и балансирование нагрузки между серверами.
- Распределенный кеш данных (memcached).
- Непрерывность сессий между веб-серверами (хранение сессий в базе данных).
- Кластеризация веб-сервера:
- Синхронизация файлов.
- Балансирование нагрузки между серверами.
С проектной точки зрения создание такого приложения в виде веб-кластера нужно выполнять в два шага:
- разделение веб-сервера и базы на два разных сервера (это не кластер как таковой),
- построение собственно кластера.
Разделение веб-сервера и базы на два разных сервера
На этом этапе приложение делится на составные части (web, БД, кеш), и эти части работают на разных серверах.
Этот этап не сложен в проектировании, и его выполнения с точки зрения производительности большинству проектов бывает вполне достаточно. Однако такое деление не решает задачу надёжности и отказоустойчивости. Каждый узел не зарезервирован, и в случае выхода из строя любого из них перестаёт работать весь проект в целом.
Построение кластера
Для реализации этого этапа необходимо решить следующие задачи:
- Репликация и балансировка нагрузки MySQL.
- Масштабирование веб-сервера.
- Задачи синхронизации файлов и авторизации пользователей.
- Масштабирование кэша.
Репликация и балансировка нагрузки MySQL
Самое простое решение - репликация, возможность которой предоставляет любая современная база данных. Чаще всего используется MySQL, так как она достаточно проста, понятна, хорошо документирована. Средствами самой базы можно организовать репликацию, добавить некоторое количество slave-серверов, которые будут получать данные с master'а, и логично вынести select и запросы на чтение на эти slave.
Схема типового веб-приложения с реплицированной базой:

Все запросы на запись отправляются на master, все запросы на чтение отправляются на slave. Это самый простой способ масштабирования.
Если этот механизм будет реализован средствами Базы данных, то на долю самого приложения остаётся диспетчеризация всех этих запросов и распределение их между серверами. Делать это лучше именно на уровне ядра приложения, потому что:
- Обеспечивается гибкая балансировка нагрузки SQL.
Очень часто необходимо произвести чтение с данных, которые были только что изменены. Например, первым запросом добавили пользователя, а вторым - запросили список пользователей. Если запрос на запись отправляется на мастер, а запрос на чтение списка пользователей отправляется на slave, то возможна ситуация, когда slave отстают от master'а (типовая ситуация) и в ответ приходят устаревшие данные. Для списка пользователей такое положение, возможно, терпимо, но если речь идёт о заказах интернет-магазина или банковских транзакциях, то неправильные данные - это критично. Именно приложение должно определять, какие select'ы нужно отправлять тоже на master для получения актуальных данных. Это означает чуть большую нагрузку на master, но зато это гарантирует получение корректных данных.
- Приложение проще администрировать.
- Обеспечивается дешевое и быстрое неограниченное масштабирование.
Приложение должно заниматься балансировкой нагрузки между slave'ми, условия которой задаются произвольным образом. В административном интерфейсе можно подключить любое количество серверов и для каждого из них задать свой вес. Возможны разные случаи, например, разные конфигурации серверов, и на тот, что помощнее, оптимально будет задать больше нагрузки. Если для этого сервера поставить больший вес, то ядро приложения будет отправлять на него больше запросов.
- Облегчается работа приложения во время выполнения бэкапа, что особо актуально для больших объёмов данных. Если на один из серверов задать вес, равный 0 (то есть не отправлять на него запросы вообще), то его можно использовать для снятия резервных копий. Это удобно в том плане, что не создаётся дополнительная нагрузка на "боевые" сервера, что в любом случае будет замедлять работу проекта.
- Не требуется доработка логики веб-приложения.
Задачи синхронизации файлов и авторизации пользователей

Не внося больших изменений в логику веб-приложения, можно добавить несколько веб-серверов, над ними поставить любой из доступных балансировщиков: от распределения по DNS и заканчивая специализированными решениями типа балансировщика Amazon'а, либо "железные" решения типа Cisco, или простейший отдельный сервер NGNIX, который распределит запросы по нескольким серверам.
Этими инструментами можно решить задачу балансировки, но нельзя решить задачи:
- Синхронизации контента между серверами. (Администратор или пользователь добавляет контент, например, картинку, и этот контент должен отобразится на всех серверах.)
- Синхронизации пользовательских сессий. Пользовательская сессия должна быть прозрачной для всех серверов веб-кластера. После авторизации на одном из серверов пользователь должен считаться авторизованным и для всех других серверов. И наоборот - окончание сессии на любом сервере должно означать ее окончание на всех серверах сразу.
Вопрос с сессиями решается достаточно просто. Они выносятся в отдельное централизованное хранилище. Либо в Базе данных, либо в мемкеше.
Вопрос с синхронизацией файлов в случае небольшого проекта достаточно прост. Можно подключить единое хранилище, например, через Network File System и работать с файловой системой со всех серверов. Удобно, но не быстро.
Другой вариант: хранить файлы на каждом сервере и использовать для синхронизации сторонние утилиты. Просто, но нет возможности синхронизировать данные моментально, всё равно будет временной промежуток недоступности файлов на каких-то серверах. С ростом объёма данных этот механизм будет работать всё менее надёжно и с замедлением.

Оптимальным решением будет вынесение всего основного контента (чаще всего это документы, картинки, видео- и аудио-файлы) в какое-то отдельное централизованное хранилище. То есть полностью разделить логику кода и веб-приложение и не хранить эти данные на веб-сервере. Этим способом будет кардинально решена задача синхронизации.

Для реализации такого хранилища можно сформулировать несколько правил:
- Должно существовать API хранилища для прозрачной работы с файлами.
- Нужно разработать API в создаваемом приложении для разработчиков. Файл не хранится локально, значит, не подойдут стандартные функции для работы с ними, нельзя оперировать какими-то свойствами файлов (размер, изображение). Эти данные должны получаться при загрузке файла через какой-то (административный или пользовательский) интерфейс системы и сохраниться в служебной таблице.
- Необходимо избегать "диких", то есть загруженных в обход системы файлов (например, FTP). Такие файлы можно отлавливать через обработку 404-ой ошибки.
- Необходимо простое подключение хранилищ, желательно одной кнопкой в приложении.
- Нужно создать правила при работе с несколькими хранилищами.
- Нужно обеспечить прозрачность работы для всех модулей системы.
Для реализации можно использовать какой-то отдельный FTP сервер и выносить файлы туда. Но при этом не решается задача резервирования и надёжности. Для решения этих задач придётся применять другие методы, скажем, средства операционной системы, систем резервного копирования и других инструментов.
Заведомо надёжное хранилище - это облачное хранилище, которое в последнее время предоставляет всё большее число провайдеров. При этом оптимальным будет решение, когда на одном проекте одновременно можно хранить разные файлы в разных облачных хранилищах. Например, все файлы "весом" больше 100 Мб перемещать в Google Storage, а все видео - в Amazon S3.
Такое деление позволяет:
- прямо в ходе работы оценить удобство, скорость и стоимость работы каждого хранилища и подобрать оптимальные варианты размещения контента.
- избежать не очень комфортной ситуации vendor lock-in.
- прямо в ходе работы переезжать с одного хранилища на другое, не прерывая работу проекта.
Rest API для всех популярных языков есть у всех хранилищ, проектирование системы на облаках не вызывает затруднений у квалифицированного разработчика.
Распределенный кеш данных
Работа с кешем аналогична работе с БД: можно подключить группу кеш-серверов, масштабируя группу по мере необходимости. (На практике использование более одного сервера - ситуация крайне редкая, только в случае очень больших проектов.)
Основная задача, которая решается распределением кеша по группе серверов - это отказоустойчивость. Кеш можно распределять, как и в случае с БД, по весам, которые задаются в административной части приложения.

- Высокая эффективность - за счет централизованного использования кеша веб-приложением.
- Надежность - за счет устойчивости подсистемы кеширования к выходу из строя отдельных компонентов.
- Неограниченная масштабируемость - за счет добавления новых memcached-серверов.
Гео-кластер
База данных, узкие места
Можно организовать распределение нагрузки на чтение между slave'ми. Но, так как все веб-сервера читают данные со всех серверов MySQL, то остаются высокие требования к связанности сети, пропускной способности, величине задержки между пакетами. В идеале все сервера должны находиться в одном дата-центре. Однако, если случится авария на уровне целого дата-центра, возникнет проблема. Такое возможно, более того, такое происходило.
Другая проблема - невозможность масштабирования между разными серверами, так как мы потеряем в скорости.
Третья проблема может возникнуть, если выйдет из строя master. В этом случае требуется заранее либо автоматизировать процедуру его восстановления, написать какие-то скрипты, которые будут превращать один из slave в master, либо оставить это администратору на ручной разбор ситуации. Правда, если авария произошла когда администратор недоступен, то проект может простаивать достаточно долго.
Необходимо резервировать сам дата-центр. По-хорошему, проект должен быть распределён географически по миру или, как минимум, по двум дата-центрам, чтобы можно было обезопасить проект даже от таких аварий.
Что можно сделать? Гео-кластер, хотя бы в упрощённом варианте. Правда, тут возникают повышенные требования к проектированию приложения.
Гео-кластер
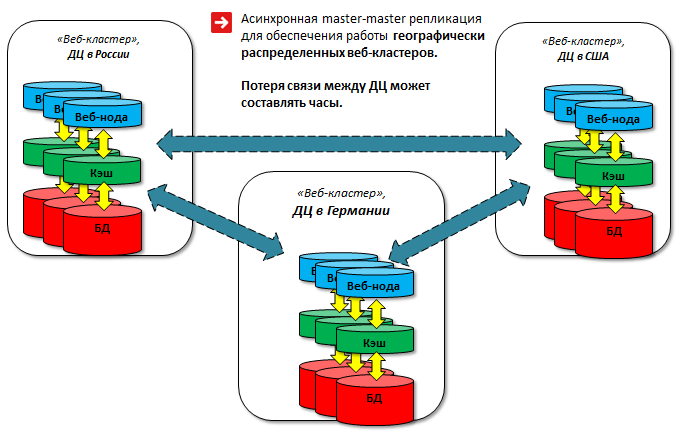
Предлагаемая схема - весьма условная master-master репликация, так как не происходит одновременной записи в две базы. Однако в большинстве случаев задача резервирования решается полностью. Эта схема позволяет держать несколько master'ов, хотя и с рядом ограничений.
Создаются группы серверов в административном интерфейсе:
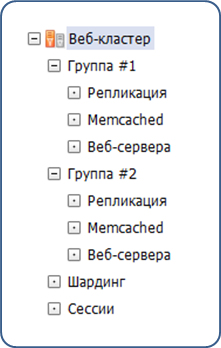
У каждой группы свой MySQL master (указан в dbconn.php). Мастеры MySQL объединены в кольцо (в минимальном варианте – 2 сервера).
Каждая группа клиентов работает с определённым сервером. Например, посетители из Европы должны попадать в европейский дата-центр и писать в master, который, находится там. Посетители из России должны попадать в российский дата-центр, и так далее. В случае аварии трафик переключается на другой дата-центр, и все посетители продолжают работать с "горячими" данными без каких-то отставаний и потерь.
Реализуется такая схема следующим образом: в самом MySQL есть возможность задать смещение для полей: auto_increment_increment и auto_increment_offset. Это обеспечивает поступление данных "стык в стык" и они не будут дублироваться. Базы в разных дата-центрах синхронны, при этом независимы друг от друга: потеря связности между дата-центрами может составлять часы, данные синхронизируются после восстановления. Таблицы БД должны иметь подобные ключи, чтобы данные не дублировались и не попадали одинаковые в разные дата-центры.
Пользователь и все сотрудники одной и той же компании работают в одном датацентре за счет управления балансировщиком. Этим исключаются сбои в подобной схеме работы master-master репликации. Сессии хранятся в базе, и объём этих данных достаточно большой. В результате были ошибки в получении данных из query кеша. Эти данные, так как пользователи направляются на определённые сервера, можно не реплицировать из-за большого трафика и возможных блокировок:
SET sql_log_bin = 0
или
replicate-wild-ignore-table = %.b_sec_session%
В результате достигнут один из приоритетов - постоянная доступность сервиса, его отказоустойчивость. Все ноды заменяемы и не зависят друг от друга, в случае аварии стартуем новые. Два дата-центра синхронизированы друг с другом и равноценно обслуживают клиентов. В случае аварии на уровне дата-центра или плановых работ с базой трафик прозрачно для клиентов переключается на рабочий дата-центр.
Вертикальный шардинг
Вертикальный шардинг - разделение одной базы данных веб-приложения на две и более базы данных за счет выделения отдельных модулей, без изменения логики работы веб-приложения.

Вертикальный шардинг - первое, что обычно делается при возникновении нехватки ресурсов. Реализация этого разделения БД не сложна и не требует серьёзного программирования, зато появляется возможность идеально подстроить сервер для работы с одной специфической таблицей, постараться уместить ее в память, возможно, дополнительно партиционировать ее и т.д.
Архитектура Базы данных
Схемы работы с БД
Работа напрямую через PHP-функции. Обеспечивает скорость разработки, гибкость, но вызывает сложность поддержки и неудобство использования. Подходит для простых проектов, не рекомендуется для больших и средних.
Работа через прослойку на основе паттерна TableModule. Работа с базой данных идёт через класс (объект), предоставляющий собой интерфейс доступа к таблице. Преимущество подхода в том, что работа с БД инкапсулируется в каком-то классе, сущности. Любые модификации идут через эту сущность. При этом упрощается развитие, поддержка и эксплуатация проекта. Недостаток: реализация сложнее, если проект разрабатывается без фреймворка, где это уже реализовано.
ORM для сложных проектов. На проектах со сложными предметными областями и сущностями иногда полезно использовать паттерны:
- ActiveRecord — объект представляет собой запись в таблице, позволяющую успешнее решать задачи большой и сложной предметной области со связями. Недостаток: большой объём кодирования, но можно использовать библиотеки.
- DataMapper — объекты не знают о БД ничего, есть только объекты и их свойства. Программисту легко реализовывать бизнес-логику в таких условиях, а за работу с БД отвечает слой DataMapper.
Внимание! Любые библиотеки для работы с БД увеличивают расходы. У TableModule накладные расходы минимальные, у DataMapper — максимальные. Поэтому DataMapper рекомендуется только для сложных областей, но не для высоконагруженных проектов.
На этапе разработки архитектуры важно предусмотреть горизонтальное масштабирование базы данных. Позже это может быть сложно. О веб-кластере стоит задуматься уже на этапе прототипа, если проект большой и высоконагруженный. Оптимально использовать готовый фреймворк, чем самостоятельно решать вопросы:
- Репликация: решаемая и несложная задача.
- Кластеризация кода: сложнее всего кластеризовать сессии и кеш. Сессии можно хранить в базе данных или memcache.
- Нагрузка и распределение: возможно через NGINX или другим способом.
- Хранение и отдача статики. Использовать CDN?
- Авторизация.
- Шардинг: может потребоваться для очень больших проектов.
Что выбрать?
Для слабых и средних команд рекомендуется использовать фреймворк, с которым команда знакома лучше всего. Это убережет от множества проблем и рисков, сократит затраты на разработку проекта (за счет того, что фреймворк даёт готовую архитектуру).
Сильные команды с большим опытом могут решиться на разработку «с нуля», если это позволит клиент по срокам и финансированию.
NoSQL для архитектора веб-проекта
NoSQL и его возможности
В последнее время все больше говорят про NoSQL. Технологии этого семейства начинают активно использовать известные авторитетные компании, в том числе в высоконагруженных проектах с немалыми объемами данных. Чтобы понять, применима ли эта технология к создаваемому вами проекту, надо разобраться в ваших потребностях и понять, сможет ли она их удовлетворить.
NoSQL (англ. not only SQL, не только SQL) - термин, обозначающий ряд подходов, направленных на реализацию хранилищ баз данных, имеющих существенные отличия от моделей, используемых в традиционных реляционных СУБД с доступом к данным средствами языка SQL. Применяется к базам данных, в которых делается попытка решить проблемы масштабируемости и доступности за счёт атомарности и согласованности данных.
В двух словах NoSQL - это необходимость выбора в рамках проекта двух из трех принципов работы с БД: согласованность данных (Consistency), доступность (Availability), устойчивость к разделению (Partition tolerance).
Причина такой необходимости - новые бизнес-задачи, которые возникли в последнее время:
- База должна быть всегда доступна для записи и чтения, и кейсы типа: сервер перезагружается, сеть упала - становятся критичными для бизнеса.
- Интенсивный рост объемов данных и ужесточение требований к их доступности, в том числе из-за бурного развития всемирной сети (в одной базе данные просто перестали помещаться).
- Клиентов становится много в разных точках мира, и нужно сохранить заказы как можно быстрее.
- Бурный рост веб-сервисов, появление мобильных устройств.
В техническом плане эти требования означают, что база должна:
- быть доступна всегда, нельзя потерять заказ клиента или его корзину, даже если пропала синхронизация между нодами базы данных.
- быть доступна везде (Европе и США), и, конечно, синхронизировать данные между копиями.
- неограниченно масштабироваться при увеличении объема данных.
- масштабироваться под нагрузку: на запись, на чтение.
При этом классические кластера БД не могут обеспечить эти возможности. Вот описания проблем, свойственных популярным БД:
- Oracle RAC - дорого и сложно, тяжеловесно, и непонятно, как раскидывать по разным материкам.
- MySQL cluster - быстрый мастер-мастер, но много подводных камней и ограничений вроде хранения данных только в памяти. Всё же достаточно удобен для некоторых кейсов.
- galera cluster for mysql - честный мастер-мастер, пиши куда хочешь (но должен знать, куда именно). Нет "устойчивости к разделению", может зависнуть при отсутствии кворума. Трудно восстанавливается при падении и тормозит при геораспределенном использовании, т.к. синхронно передает данные на все копии. Нет шардинга данных между мастерами.
Так вот, прошло не так много времени, как в начале нынешнего столетия появились NoSQL-продукты и стало возможным:
- писать на любой элемент кластера;
- размещать элементы кластера на разных материках и читать с локальных;
- выключать любую ноду кластера без угрозы для системы в целом
- добавлять ноды кластера по потребности, что позволяет масштабировать как запись, так и чтение.
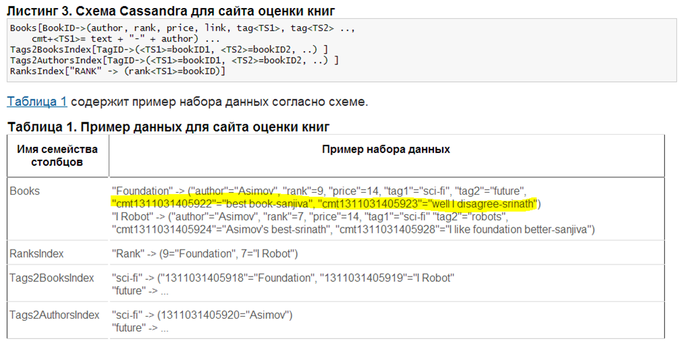
Пример того, как программисты реализуют требования бизнеса используя NoSQL. В строке с информацией о книге хранятся комментарии пользователей к ней. Что невозможно в рамках традиционной БД:
Ограничения NoSQL
Но и у NoSQL есть свои ограничения.
- NoSQL позволяет писать на любую ноду кластера, но по умолчанию читать приходится устаревшую неконсистентную информацию, так как информация распространяется с ограниченной скоростью. NoSQL-продукты предоставляют опцию чтения только что записанной информации, но за это придется платить увеличением времени ожидания.
- NoSQL позволяет разместить ноды кластера на разных материках, но так как информации нужно время, чтобы она разошлась по континентам, то приложение должно уметь это обработать.
- NoSQL позволяет выключать любую ноду кластера, но устойчивость к разделению кластера реализована за счет технологий, похожих на версионность. Следовательно, периодически нужно будет запускать поиск рассогласований типа Anti-entropy using Merkle trees.
- NoSQL позволяет добавлять ноды кластера по необходимости, но конфигурировать остальные ноды все-таки придется, и иногда это совсем не просто сделать.
Это общие для продуктов NoSQL ограничения. Но есть нюансы и в использовании конкретных реализаций. Рассмотрим их на примере Amazon DynamoDB (очень похожий на Apache Cassandra.)
Ограничения Amazon DynamoDB:
- Мало типов данных: число, строка, бинарные данные. Нет DATETIME (их можно эмулировать таймстампом).
- Ограничения по индексам. Индексы нужно указать сразу, их должно быть не более 5 на таблицу. Причем добавлять их в существующую таблицу нельзя, нужно ее удалять, пересоздавать и перезаливать туда данные.
- Можно хранить любой объем данных, но размер одной "строки таблицы" с именами и значениями "колонок" не должен превышать 64КБ. Правда число "колонок" не ограничивается. И на одной ноде кластера (c одним значением основного индекса hash key) при наличии дополнительных индексов нельзя хранить больше 10ГБ. (Термин "колонока" - условный. В NoSQL нередко понятия схемы данных просто нет, поэтому в каждой "строке таблицы" могут быть разные "колонки" или "атрибуты".)
- Запросы. Можно выбрать данные только по одному индексу. Есть еще основной (hash key) индекс, но диапазонные выборки делать по нему нельзя - только константные. Отсортировать можно только по одному индексу.
Нельзя использовать сложные WHERE, GROUP BY, не говоря уже о подзапросах: NoSQL-движки их просто эмулируют и могут выполнять очень медленно.
Можно выполнять более сложные выборки, но методом полного сканирования таблицы (table scan) и затем поэлементной фильтрации результатов на серверной стороне, что и долго и дорого.
- Транзакции: гарантируется лишь атомарное обновление отдельных сущностей. (Есть, правда, приятные возможности с чтениями/инкрементами за одну операцию). Так что транзакции придется эмулировать: данные разнесены по 20 серверам/дата-центрам всего земного шара.
- Атрибуты. Нередко в NoSQL, в том числе в DynamoDB можно использовать что-то типа:
user=john blog_post_$ts1=12 blog_post_$ts2=33 blog_post_$ts3=69
где
$ts1-3- таймстампы публикаций пользователя в блог. Это позволяет получить список публикаций за один запрос. Но работа программиста увеличивается.
Варианты подходов NoSQL
CA - согласованность данных (Consistency) и доступность (Availability)
Система, во всех узлах которой данные согласованы и обеспечена доступность, жертвует устойчивостью к распаду на секции. Если у вас интернет-магазин, сервера находятся в разных дата-центрах, и в какой-то момент один из серверов "упал", то система становится неработоспособной в целом.
Такие системы возможны на основе технологического программного обеспечения, поддерживающего транзакционность в смысле ACID. Примерами таких систем могут быть решения на основе кластерных систем управления базами данных или распределённая служба каталогов LDAP.
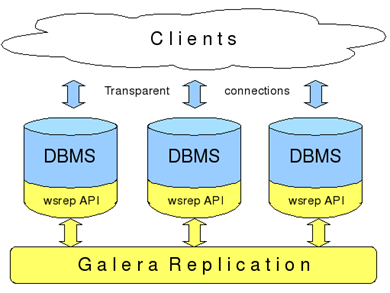
CP - согласованность данных (Consistency) и устойчивость к разделению (Partition tolerance)
Распределённая система, в каждый момент обеспечивающая целостный результат и способная функционировать в условиях распада, в ущерб доступности может не выдавать отклик. Данные пишутся на одну машину, дублируются на другую. Если одна "упала", то можно работать со второй. Устойчивость к распаду на секции требует обеспечения дублирования изменений во всех узлах системы, в этой связи отмечается практическая целесообразность использования в таких системах распределённых пессимистических блокировок для сохранения целостности
AP - доступность (Availability), устойчивость к разделению (Partition tolerance)
Распределённая система, отказывающаяся от целостности результата. Большинство NoSQL-систем принципиально не гарантируют целостности данных. Задачей при построении AP-систем становится обеспечение некоторого практически целесообразного уровня целостности данных, в этом смысле про AP-системы говорят как о "целостных в конечном итоге" (eventually consistent) или как о "слабо целостных" (weak consistent). Наиболее распространённые системы.
Выводы
Прежде чем выбирать для проекта NoSQL хранилище, оцените все возможные призы и риски:
- NoSQL - это часто не что иное, как набор memcached-подобных серверов с надстроенной довольно простой логикой и, соответственно, сохранение данных и простые выборки будут действительно быстрыми. В случае более сложных запросов задачу придется решать на стороне приложения.
- Помните, что по теореме Брюера при реализации придётся выбирать не более двух из трёх свойств: согласованность данных, их доступность и устойчивость к разделению.
- Внимательно изучить документацию по используемому продукту, особенно ограничения, к которым нужно будет аккуратно подготовиться.
- NoSQL создает ложное впечатление, что можно не знать принципы работы SQL. На самом деле, нужно хорошо понимать классическую реляционную теорию, чтобы предвидеть развитие модели данных приложения в NoSQL, угадать варианты денормализации, чтобы приложение не пришлось потом несколько раз переписывать.
С помощью NoSQL вы получите очень надежное, высокодоступное, поддерживающее гибкие схемы репликации современное решение. Однако платить придется жесточайшей денормализацией и усложнением логики работы приложения (в т.ч. эмулировать транзакции, жонглировать тяжелыми данными внутри приложения и тому подобное).
Как выбрать дисковую систему для базы MySQL
Введение
Если вы периодически наблюдаете близкую к 100% утилизацию диска в iostat, то пришло время задуматься над тем, правильно ли вы выбрали дисковую систему.
Самое, как кажется, очевидное решение: надо использовать более быстрые диски - SSD. Но требуется поддержка SSD в серверах (контроллер, драйверы) и это довольно дорого.
Другой подход - использовать не один, а несколько дисков: RAID.
Для высоконагруженных проектов актуальны, прежде всего software RAID, так как такие проекты, как правило, размещаются в облачных структурах. Поэтому предложим методики тестирования для определения конфигурации RAID подходящей для вашего проекта.
Примечание: также можно посмотреть результаты тестов на EBS дисках в Amazon, опубликованные в MySQL Performance Blog. Эта информация тоже будет полезна, несмотря на то, что не корректно сравниваются очень разные результаты (например, чтение с одного диска в один поток, RAID 0 - 8 потоков, RAID 10 - 4; и тому подобное).
Пример тестирования
Пример тестирования проведём на работе с RAID 10. Именно он одновременно и быстрый, и надежный. А, вот, различных его конфигураций - достаточно много.
Примечание: В процессе тестирования оцените еще одно очень важное преимущество "облака": в нём очень удобно проводить самые разные тесты, собирая и разбирая любые тестовые стенды. И при этом платить — только за время реального использования.
Собрано 5 стендов:
- single disk - 100 Gb
- RAID 10 - 4 диска по 50 Gb. Добавить через админку Амазона 4 диска, подключить их, назначив соответствующие имена. А затем создать рейд вот так:
# mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/xvd[g-j]
- RAID 10 - RAID 0 из двух RAID 1 (каждый по 2 диска по 50 Gb). Та же процедура, но итоговый рейд создается в три приема:
# mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/xvd[g-h] # mdadm --create /dev/md1 --level=1 --raid-devices=2 /dev/xvd[i-j] # mdadm --create /dev/md2 --level=0 --raid-devices=2 /dev/md[0-1]
- RAID 10 - 8 дисков по 25 Gb. Аналогично пункту 2, но только подключаются 8 дисков, а не 4.
# mdadm --create /dev/md0 --level=10 --raid-devices=8 /dev/xvd[g-n]
- RAID 10 - RAID 0 из четырех RAID 1 (каждый по 2 диска по 25 Gb).
# mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/xvd[g-h] # mdadm --create /dev/md1 --level=1 --raid-devices=2 /dev/xvd[i-j] # mdadm --create /dev/md2 --level=1 --raid-devices=2 /dev/xvd[k-l] # mdadm --create /dev/md3 --level=1 --raid-devices=2 /dev/xvd[m-n] # mdadm --create /dev/md4 --level=0 --raid-devices=4 /dev/md[0-3]
На всех тестовых стендах используйте однотипную файловую систему, например: ext4. Параметры монтирования:
noatime,nodiratime,data=writeback,barrier=0
Для тестов лучше использовать sysbench - на файле 256 Мб; режимы - random read, random write, random read/write; разным количеством потоков, от 1 до 16.


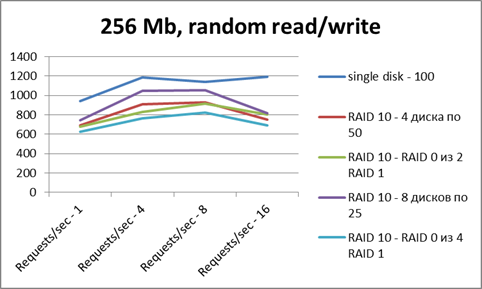
- Ось X - число потоков
- Ось Y - число операций в секунду.
По тестам видно, что в чтении все сопоставимо по результатам. Рейд не дает особого преимущества. Но картинка эта - весьма искаженная, так как на результаты очень сильно повлиял файловый кэш (тестовый файл помещается в RAM целиком). По записи рейды несколько проигрывают (сказываются некоторые накладные расходы).
Чтобы определить, какая дисковая система лучше в конкретно вашем случае, необходимо чётко поставить задачу. В нашем случае выбирается дисковая система для базы. Формат хранения данных: InnoDB. Это означает, что работа в основном ожидается с большими файлами (несколько Гб) ibdata.
Значит, типичный профиль нагрузки - random read/write (чтений больше). И вот уже исходя из более понятной реальной задачи делаем новую серию тестов - на файле размером 16 Гб:
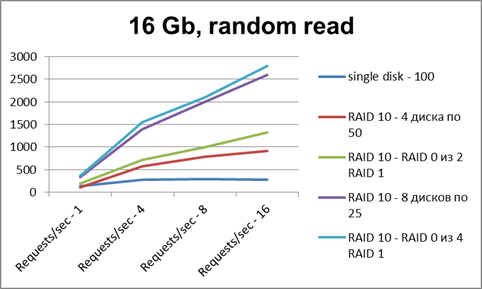
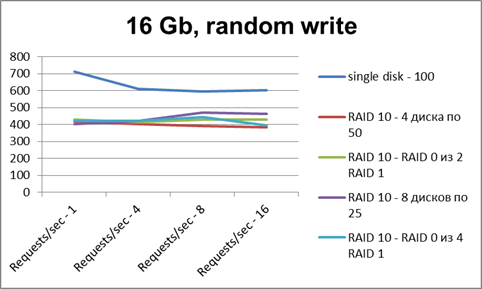

Видно, что при чтении один диск сразу упирается в потолок, и увеличение количества потоков не дает прироста производительности. А рейды из 4 дисков на нескольких потоках дают прирост производительности в 3-4 раза. Рейды из 8 дисков — в 6-7 раз.
На запись у рейдов примерно та же картина, что и с одним диском.
Резюме
Типичная работа базы MySQL - random read/write, чтений больше, чем записи. Самые производительные для такой задачи: RAID 10 с большим количеством дисков.
Минус такого решения - в удвоенной стоимости дисков (что при текущей их стоимости не является критичным).
Главное преимущество - у нас есть простое решение (software RAID можно собрать как на физическом сервере, так и в "облаке") для масштабирования производительности дисковой системы.
Программная архитектура веб-систем на Битриксе
Введение
Для программиста не важно, какой использовать framework. Framework - это просто основа, из которой бывает нередко целесообразнее собрать проект, чем писать с нуля. И Bitrix Framework здесь не исключение. Его надо понять, увидеть в целом, оценить его сложность и возможности. Но для ведущего разработчика, который выбирает модель реализации, знание системы важно, иначе трудно ожидать разумного и оправданного выбора архитектуры решения. Рассмотрим несколько вариантов архитектур, позволяющих решать определённые задачи.
Есть два варианта использования Bitrix Framework: "простой" и "сложный". Простой - обычный сайт, без магазина. Магазин - это более сложно, независимо от платформы. Если разработчик делал простые сайты, а потом начинает делать магазин, то ему, возможно, только с неделю нужно осваивать штатный функционал магазина.
Работая с Битрикс, нужно в первую очередь понимать, что можно выжать из стандартных компонентов и шаблонов, а что придётся дописывать.
Простой сайт
Модель простого сайта и что должен предусмотреть проектировщик при реализации такого проекта.
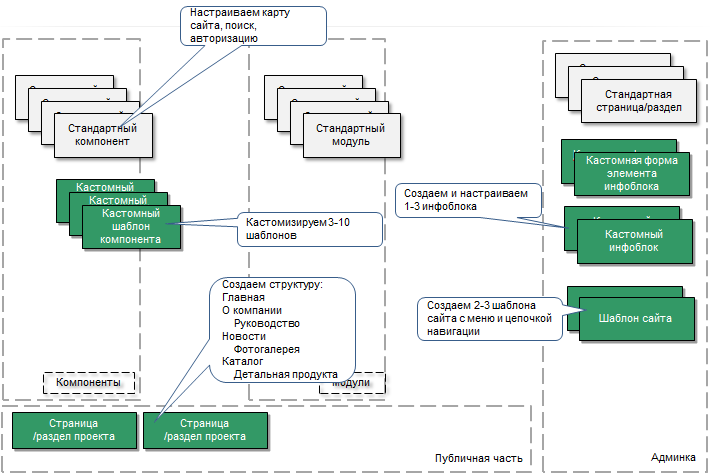
В случае простого сайта не производится больших объёмов работ. Как правило, это: создание кастомных шаблонов компонентов, создание структуры сайта, шаблона сайта, несколько инфоблоков. Иногда создаётся кастомная форма добавления элемента инфоблоков.
Сайт с объёмным контентом
Одно из главных отличий такого сайта - разделение прав доступа при создании контента с системой проверки и выпуска контента. Другое отличие - большие объёмы данных, к которым нужно обеспечить быстрый доступ и при этом гарантировать их сохранность.
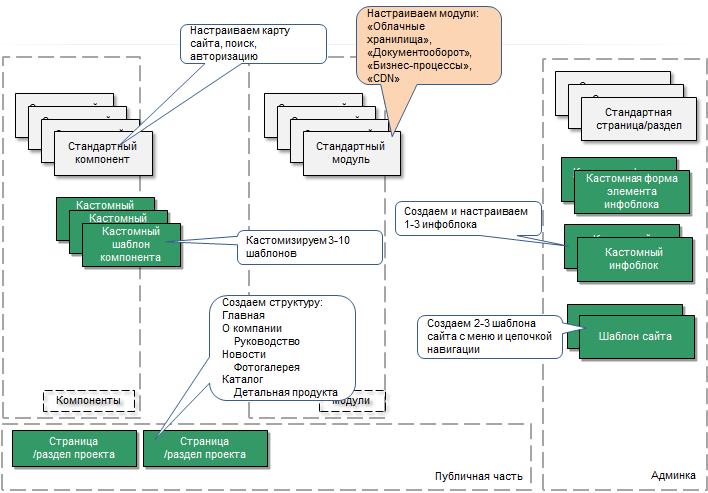
Для хранения большого объёма данных рекомендуется использовать Облачное хранилище. Весь большой контент рекомендуется хранить там.
Для организации поэтапной работы над контентом рекомендуется использовать Документооборот и Бизнес процессы
Много данных в инфоблоках
Под "много данных" понимается сотни тысяч и миллионы элементов.
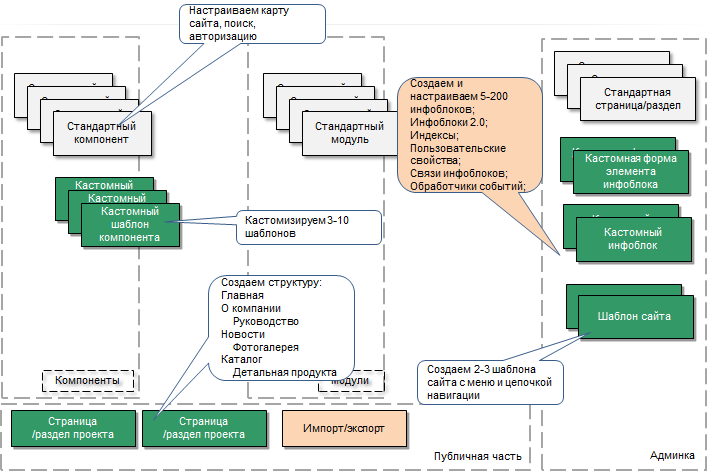
Такой проект "тяжёл" для административной части. Рекомендуется не использовать опцию Совместный просмотр разделов и элементов в настройках модуля Информационные блоки (и настройках самого инфоблока) и обязательно разносить инфоблоки по типам.
Обязательно для таких проектов необходимо:
- Спроектировать модель данных в инфоблоках. Необходимо понять, где нужна денормализация, где - агрегация, где кеширование.
- Описать и реализовать основные запросы к данным из публички (иногда админки). Нужно понять цепочки использования. Например, клиент планирует получать регулярно список новостей (или список элементов в каталоге), и редко (раз в месяц) строить выборки, например, по продажам. Следовательно нужно обеспечить быструю обработку частых запросов, в нашем случае: просмотр списков новостей (каталога), просмотр разделов каталога.
- Реализовать соединение выборок из инфоблоков (joins). Нужно спроектировать модель соединения данных из инфоблоков. В крайних случаях использовать прямые запросы в БД. НО перед этим надо попытаться использовать все доступные средства API.
- Пользовательские свойства. Скорее всего, они будут не совпадающими у инфоблоков, так как контента много и он наверняка разнотипный.
- Кастомные страницы административной части к инфоблокам. При больших объёмах есть смысл в таком проектировании.
- Управляемое и эффективное кеширование данных.
- Экспорт/импорт - JSON, XML, REST, очереди, инкременты.
Много ролей
В этом случае на сайте работает много сотрудников, и, как следствие этого, возникают повышенные запросы по безопасности, повышенные требования к разделению доступа.
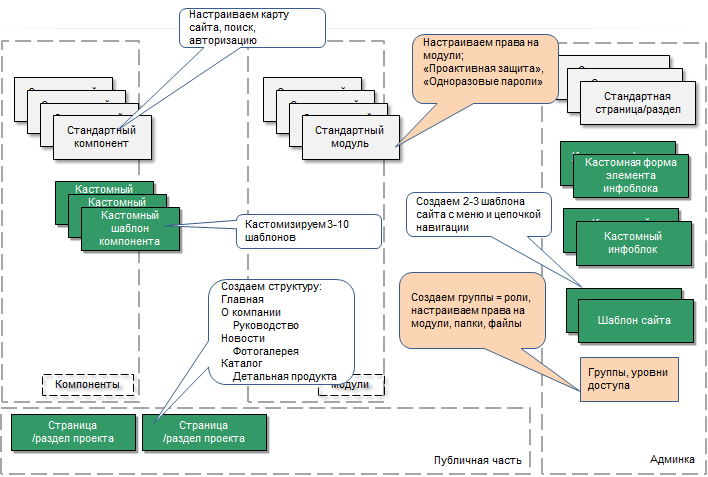
На таком проекте практически всё делается штатными средствами, надо только понять систему уровней доступа к модулям, папкам, файлам:
- Настраиваем группы и учетные записи пользователей. Настраиваем параметры безопасности группы.
- Настраиваем уровни доступа и доступ к модулям.
- Включается проактивная защита, безопасная авторизация, а лучше - одноразовые пароли.
- Тщательное тестирование складывающейся системы доступа.
- В процессе эксплуатации не забывать отслеживать процесс изменений в системе.
Много кода
Сложный проект, когда функционал выходит за стандартные возможности Bitrix Framework. Основная опасность: желание залезть в ядро Bitrix Framework и изменить его. В этом случае либо все изменения затрутся при обновлении, либо придётся отказаться от обновлений системы. Битрикс поддерживает обратную совместимость API, и любой проект может спокойно обновиться и получать новый функционал.
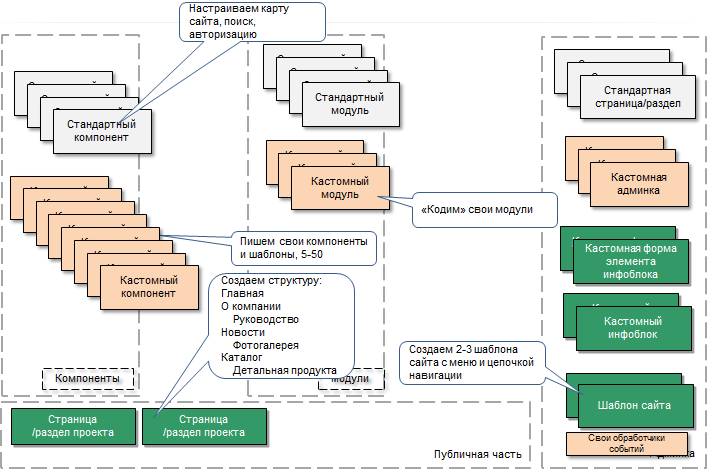
Кастомизируются или создаются компоненты. Создаются собственные модули с интерфейсом настройки, где хранятся общие классы, библиотеки. Определяем обработчики событий, которые могут менять поведение системы в нужную вам сторону, и пишем в техподдержку Bitrix Framework, если событий не хватает. Создаем свои страницы административного раздела.
В таких проектах ответственность лежит полностью на разработчиках, за Bitrix Framework не спрячешься, надо внимательно рассматривать вопросы производительности, безопасности, аудита.
Интеграция с внешними системами
Задача потребует нетривиального программирования. Используется модуль Веб-сервисы. Если не хватает функционала, то используя REST, SOAP, JSON, XML-RPC API, дорабатываем нужный функционал. Далее реализуете систему синхронизации.
Если данных очень много, то есть смысл создать свои таблицы в MySQL и хранить данные там.
В проектах такого уровня разработчики должны представлять себе администрирование систем. Так, при работе с веб-сервисами нужно понимать XML, TCP-IP, FTP. Как пойдут пакеты, где что пропадает. И кроме этого, в группу разработчиков надо подключать квалифицированного сисадмина как можно раньше.
Веб-кластер
Веб-кластер позволяет решать множество задач. При этом в коде вашего проекта ничего делать не нужно, это штатная функция Bitrix Framework.
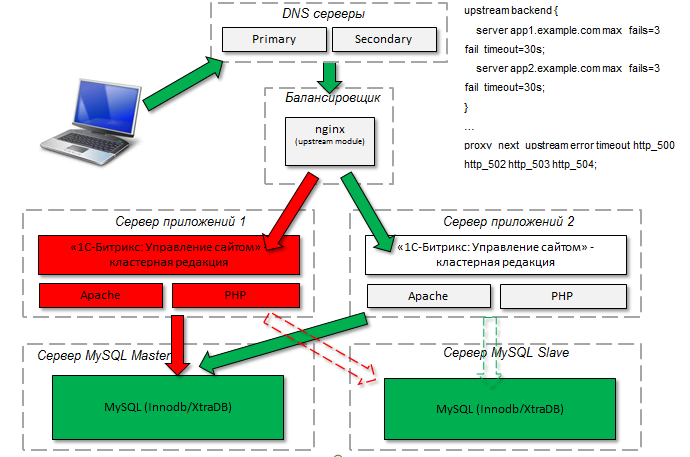
При проектировании проектировщик должен рассчитать возможную нагрузку на проект и на основании этого сказать, что делать будем кластер. На этом его функции заканчиваются, всё остальное делает система. Нужно только настроить в административной части пулы ресурсов: базы, кэши, обл. хранилища.
Нужно подумать о логике восстановления на базе требований SLA. Надо понять, как сделать так, чтобы максимум 2 минуты система была недоступна. Последнее - резервное копирование. Нужен отдельный регламент.
Особенности проектирования под Битрикс
Проектирование
В данном уроке мы рассмотрим вопросы, связанные не с разработкой, а именно с проектированием под Bitrix Framework.
Важно! Для успешного проектирования системы следует изучить учебные курсы: Контент-менеджер, Администратор. Базовый, Администратор. Модули, Администратор. Бизнес, Администратор "1С-Битрикс: Корпоративный портал", Разработчик Bitrix Framework.
Проектированием веб-системы может заниматься: менеджер проекта, аналитик или разработчик. При этом учитывайте, что могут возникнуть трудности в связи с тем, что менеджер старается угодить клиенту в ущерб архитектуре, аналитик может сделать слишком много моделей и объектов, а разработчик спроектирует систему так, чтобы удобно было программировать, а не использовать.
В модели проектирования должны быть отражены следующие вещи:
- права и роли (необходимо определить, кто что может делать и где);
- структура контента сайта (список страниц и разделов);
- шаблоны сайта и их динамика;
- меню сайта;
- свойства страниц и разделов, как выполняется управление ими;
- модели данных и работа с ними (инфоблоки, кастомизированные формы административной части)
- компоненты и их размещение на страницах;
- поиск на сайте;
- иногда веб-сервисы;
- выгрузка во внешние системы (при необходимости), синхронизация данных с внешними системами;
- многосайтовость (если используется).
Что должно быть в ТЗ
В техническом задании описывается структура информации проекта - это шаблон сайта (какие в нем включаемые области, типы меню и т.д.) и дерево разделов и страниц. Также описывается и структура самой веб-страницы, какие в ней используются компоненты.
В общих словах, для проектировщика система Bitrix Framework - это набор компонентов, модулей, административная и публичная части. Компоненты подразделяются на стандартные и на свои, кастомные. Модули системы также разделяются на стандартные, которые могут быть расширены кастомными обработчиками событий, и на собственные кастомные, которые могут быть связаны со своей базой данных. В административной части также, помимо стандартных страниц/разделов, могут быть кастомные страницы/разделы, формы инфоблоков, кастомные свойства и настройки инфоблоков. Публичная же часть пишется разработчиком полностью с нуля.
При составлении технического задания обратите внимание, что публичная часть модифицируется очень гибко, а административная часть модифицируется значительно сложнее и только в ограниченных местах. В ТЗ должно быть кратко описано то, что делается с помощью стандартных возможностей (можно ссылаться на официальную документацию и учебные курсы), а весь нестандартный функционал должен быть описан детально. Если необходима разработка кастомных админок (в очень редких случаях), то по ним также составляется детальное описание.
Права и роли в ТЗ
В системе Bitrix Framework права и роли играют ключевое значение. В техническом задании необходимо расписать роли, настраиваемые группы пользователей для этих ролей. Если вам не хватает возможностей стандартных уровней доступа, вы можете добавить свои уровни доступа. Все настроенные права доступа необходимо тщательно тестировать для всех групп пользователей.
Инфоблоки в ТЗ
Как правило, все сущности и данные представляются в Bitrix Framewok инфоблоками и некоторыми объектами из модулей. Поэтому в ТЗ вам необходимо четко определить типы инфоблоков, типы полей инфоблоков. Необходимо расписать модель сущностей, указать, как инфоблоки связаны между собой. Направление связей инфоблоков очень важно с точки зрения производительности. В связи с этим модель сущностей следует обсудить с разработчиком, чтобы не было тяжелых запросов. В случае необходимости можно прибегнуть к денормализации данных.
Также в ТЗ необходимо учесть, кто имеет права на те или иные инфоблоки и разделы. Прописать, какие и для чего используются обработчики событий при работе с инфоблоками.
При проектировании инфоблоков продумывайте, как избежать глубоких выборок. Если у вас часто будут обновляться данные, то, может быть, текущая структура инфоблоков вам не подходит, и ее необходимо заменить (обсудите с разработчиком). Кроме того, необходимо продумать сохранение целостности данных после выполнения некоторых операций, например, удаления.
Компоненты в ТЗ
В ТЗ следует подробно расписать, какие компоненты используются на страницах сайта. Кроме того, полезно указать, из каких инфоблоков тянет данные тот или иной компонент. Для нестандартных компонентов необходимо описать все их свойства. В параметрах компонентов не должно быть настроек, не связанных с логикой работы проекта. Если у компонента сложная логика работы (например, зависящая от настроек модуля), то об этом также необходимо отметить в ТЗ.
Полезные компоненты можно добавлять в свою библиотеку и потом использовать в других проектах. Если компонентов много или кода очень много, то делайте свой модуль, чтобы держать в нем общий код компонентов.
E-commerce в ТЗ
В первую очередь необходимо четко понимать, для чего нужен модуль Интернет-магазин, а для чего - Торговый каталог. Таким образом, в ТЗ должно быть указано, какие именно модули вам нужны, а также нужно ли вам много корзин.
В ТЗ обязательно должна быть подробно описана логика ценообразования, система скидок, как выполняется округление при пересчете цены. Вопросы, связанные с используемыми типами товаров (наборы, комплекты, торговыми предложениями) и остатками, также должны быть освещены в ТЗ.
Статусы заказов полезно описать с помощью диаграммы статусов (диаграммы состояний UML). Платежные системы, службы доставки и все нестандартные настройки других объектов, связанных с магазином, необходимо также добавить в ТЗ. Не следует забывать описывать и используемый формат импорта/экспорта данных магазина.
Веб-сервисы в ТЗ
Нередко в сложных проектах нужно обеспечить взаимодействие магазина, например, с SAP или с 1С, но не по стандартному протоколу обмена. В этом случае может быть удобным использование веб-сервисов, особенно если необходимо быстро передавать изменения. Механизм работы и использование веб-сервисов полезно отображать с помощью диаграмм UML: деятельности (activity), последовательности и др.
Быстрое веб-приложение
При рассмотрении и оптимизации проекта обычно берут во внимание 2 слабо связанные технологически и социально части: фронтэнд и бэкэнд. И нередко забывают про третью ключевую составляющую - сеть.
Сеть. Расстояние и пропускная способность сети
Расстояние и пропускная способность сети
Для типичного веб-приложения пропускная способность не особо важна (если только файлы не качать) - гораздо важнее latenсy, т.к. делается много небольших запросов по разным соединениям и TCP-окно просто не успевает раскачаться.
И разумеется, чем дальше клиент от веб-сервера, тем дольше. Но бывает что нельзя иначе или трудно. Именно поэтому придумали:
- CDN
- Динамическое проксирование (CDN-наоборот). Когда в регионе ставится, например nginx, открывающий постоянные коннекты на веб-сервер и терминирующий ssl. Понятно зачем? Именно - в разы ускоряется установление соединений от клиента с веб-прокси (хэндшейки начинают летать), а дальше используется прогретое TCP-соединение.
Еще можно увеличить TCP’s initial congestion window - это нередко помогает, т.к. веб-страничка отдается одним набором пакетов без подтверждения.

"Разогрев" соединения
TCP-окошко соединения должно разогнаться сначала. Если веб-страница загружается меньше секунды - окошко может не успеть увеличиться. Средняя пропускная способность сети в мире - немного превышает 3 МБит/с. Вывод - нужно передавать через одно установленное соединение как можно больше, "разогрев" его.
Помочь тут может мультиплексирование HTTP-ресурсов внутри одного TCP-соединения: передача нескольких ресурсов вперемешку как в запросе, так и ответе. Поэтому тут можно использовать HTTP 2.0 или pipelining (но не из браузера, а из приложения напрямую).
Бэкэнд
Приложение
Типичная схема работы веб-приложения состоит из следующих шагов:
- Приложение и/или веб-сервер (php, java, perl, python, ruby и т.п.) - принимает запрос клиента;
- Приложение обращается к БД и получает данные;
- Приложение формирует html;
- Приложение и/или веб-сервер - отдает данные клиенту.
Тут все понятно с точки зрения обеспечения скорости:
- оптимальный код приложения, без зацикливаний на секунды;
- оптимальные данные в БД, индексация, денормализация;
- кеширование выборки из БД.
Главное одно - чтобы приложение было прозрачно и можно было измерить скорость прохождения запроса через разные компоненты приложения. Если этого нет - дальше можно не читать, не поможет.
Как этого добиться? Пути известны:
- Стандартное логирование запросов (nginx, apache, php-fpm);
- Логирование медленных запросов БД (опция в mysql);
- Инструменты фиксации узких мест при прохождении запроса. Для php это xhprof, pinba;
- Встроенные инструменты внутри веб-приложения, например модуль Монитор производительности.
Если логов вас много и вы запутываетесь в них, то тогда следует агрегировать данные, смотреть процентили и распределение.
При обнаружении запроса более 0.3 секунд начинайте разбор полетов и так до победного конца.
Веб-сервер
В плане скорости тут может помочь "костылизация" - через установку обратного прокси-веб-сервера перед веб-сервером (fascgi-сервером).
Это помогает:
- держать значительно больше открытых соединений с клиентами (за счет другой архитектуры кеширующего прокси - для nginx это использование мультиплексирования сокетов небольшим числом процессов и низкого объема памяти для одного соединения)
- более эффективно отдавать статические ресурсы напрямую с дисков, не фильтруя через код приложения
Постоянные соединения
Ключ к пониманию появления тормозов в следующей диаграмме:

Установление TCP-соединения занимает 1 RTT. Эта величина довольно тесно коррелирует с расположением вашего пользователя относительно веб-сервера (да, есть скорость света, есть скорость распространения света в материале, есть маршрутизация) и может занимать (особенно с учетом провайдера последней мили) - десятки и сотни миллисекунд, что конечно много. И беда, если это установление соединения происходит для каждого запроса, что было распространено в HTTP/1.0.

Ради этого по большому счету и затевался HTTP 1.1 и в этом направлении развивается и HTTP 2.0 (в лице SPDY ). IETF с Google в настоящее время пытаются сделать все, чтобы выжать из текущей архитектуры сети максимум - не ломая ее. А это можно сделать максимально эффективно используя TCP-соединения, используя их полосу пропускания как можно плотнее через мультиплексирование, восстановление после потерь пакетов и др.

Поэтому обязательно нужно проверить использование постоянных соединений на веб-серверах и в приложении.
TLS
Без TLS, который изначально зародился в недрах Netscape Communications как SSL - в современном мире никуда. И хотя, говорят, Последняя "дырочка" в этом протоколе заставила многих поседеть значительно раньше срока - альтернативы практически нет.
Но не все почему-то помнят, что TLS ухудшает "послевкусие" - добавляя 1-2 RTT дополнительно к 1 RTT соединению через TCP. В nginx вообще по умолчанию кеш сессий TLS - выключен, что добавляет лишний RTT.
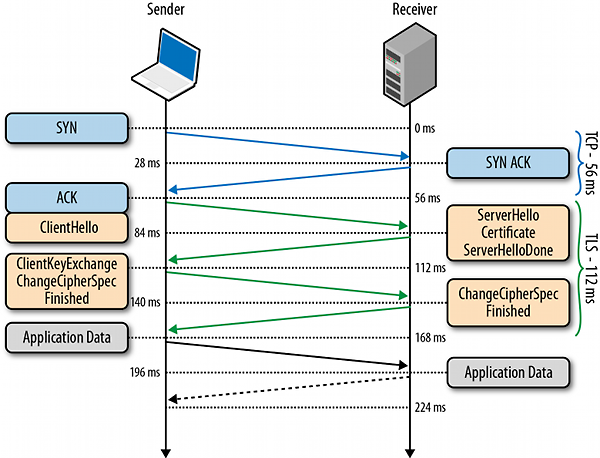
Поэтому следует проследить, чтобы TLS-сессии в обязательном порядке кешировались, что позволит сэкономить еще 1 RTT (а один RTT все-таки останется, к сожалению, как плата за безопасность).
Фронтэнд
Введение
Тема про известные вещи типа скорости рендеринга веб-страницы и размера изображений и JavaScript, порядка загрузки ресурсов и т.п. достаточно избита.
Если кратко ее затронуть, то необходимо кешировать ресурсы на стороне веб-браузера, но с головой. Кешировать 10МБ js-файл и парсить его внутри браузера на каждой веб-странице ни к чему хорошему не приведет.
Гораздо более острые подводные камни могут скрываться за достаточно новыми и бурно развивающимися сетевыми возможностями веб-браузера:
- XMLHttpRequest
- Long Polling
- Server-Sent Events
- Web Sockets
XMLHttpRequest
Это всем известный AJAX - способность браузера обращаться к внешним ресурсам по HTTP. С появлением CORS - начался совершенный "беспредел". Теперь чтобы определить причину торможения, нужно лазать по всем ресурсам и смотреть логи везде.
Технология, несомненно, взорвала возможности браузера, превратив его в мощную платформу динамического рендеринга информации. Писать о ней нет смысла, тема многим известна. Однако стоит упомянуть про ограничения:
- отсутствие мультиплексирования нескольких "каналов" заставляет неэффективно и не полностью использовать пропускную способность TCP-соединения;
- нет адекватной поддержки streaming (открытие соединения с последующим ожиданием), т.е. остается обращаться к серверу и смотреть, что он ответил.

Тем не менее, технология очень популярна и сделать ее прозрачной с точки зрения мониторинга скорости - несложно.
Long Polling
Как сделать веб-чат? Да, нужно как-то передавать со стороны сервера в браузер информацию об изменениях. Напрямую через HTTP - нельзя, не умеет. Только: запрос и ответ. Вот в лоб люди и решили: сделать запрос и ждать ответ, секунду, 30 секунд, минуту. Если что-нибудь пришло - отдать в ответ и разорвать соединение.

Куча антипаттернов и костылей - но технология очень широко распространена и работает всегда. Но, нагрузка на серверы при таком подходе - очень высока, и может сопоставляться с нагрузкой от основной посещаемости веб-проекта. А если обновления от сервера к браузерам распространяются часто - то может основную нагрузку превышать в разы.
Server-Sent Events
Тут открывается TCP-соединение с веб-сервером, не закрывается и через него сервер передает разную информацию в UTF-8. Нельзя, правда, бинарные данные передавать оптимально без предварительного Base64 (+33% увеличение в размере), но как канал управления в одну сторону - превосходное решение. Правда не поддерживается в Internet Explorer (см. пункт выше, который везде работает).

Плюсы технологии в том, что она:
- очень проста;
- не нужно после получения сообщения заново переоткрывать соединение с сервером.
Web Sockets
Браузер "хитрым" способом через HTTP 1.1 Upgrade меняет "тип" HTTP соединения и оно остается открытым.
Затем по соединению в ОБЕ стороны можно начать передавать данные, оформленные в сообщения (frames). Сообщения бывают не только с информацией, но и контрольные, в т.ч. типа "PING", "PONG". Первое впечатление - снова изобрели велосипед, снова TCP на базе TCP.
С точки зрения разработчика - конечно, это удобно, появляется дуплексный канал между браузером и веб-приложением на сервере. Хочешь streaming, хочешь messages. Но:
- не поддерживается html-кеширование (работа происходит через бинарный framing-протокол);
- не поддерживается сжатие, его нужно реализовать самостоятельно;
- жутки глюки и задержки при работе без TLS - из-за устаревших прокси серверов;
- нет мультиплексирования, в результате чего каждое bandwidth каждого соединения используется неэффективно;
- на сервере появляется много висящих и делающих что-то "гадкое с базой данных" прямых TCP-соединений от браузеров.
Как же отслеживать производительность Web Sockets? Со стороны клиента - сниффер пакетов WireShark, со стороны сервера и с включенным TLS - можно решить задачу через патчинг модулей для nginx, как вариант.
Резюме
Так что же лучше: XMLHttpRequest, Long Polling, Server-Sent Events или Web Sockets? Успех - в грамотном сочетании этих технологий. Например, можно управлять приложением через WebSockets, а загружать ресурсы с использованием встроенного кэширования через AJAX.
Выводы
Что теперь делать?
Научиться измерять и реагировать на превышение заданных значений. Обрабатывайте логи веб-приложения, разбирайтесь с медленными запросами в них. Скорость на стороне клиента тоже стало возможным мерить благодаря Navigation timing API. Можно собирать данные по производительности в браузерах, отправлять их средствами JavaScript в облако, агрегировать в pinba и реагировать на отклонения. Очень полезное API.
В результате вы найдете себя в окружении системы мониторинга типа nagios, с десятком-другим автоматических тестов, на которых видно, что со скоростью работы вашей веб-системы все в порядке. А в случае срабатываний - команда собирается и принимается решение. Кейсы могут быть, например, такими:
- Медленный запрос в БД. Решение - оптимизация запроса, денормализация в случае крайней необходимости.
- Медленная отработка кода приложения. Решение - оптимизация алгоритма, кэширование.
- Медленная передача тела страницы по сети. Решение (в порядке увеличения стоимости) - увеличиваем tcp initial cwnd, ставим динамический прокси рядом с клиентом, переносим серверы поближе
- Медленная отдача статических ресурсов клиентам. Решение - CDN.
- Блокировка в ожидании соединения с серверами в браузере. Решение - шардинг доменов.
- Long Polling создает нагрузку на серверы, большую, чем хиты клиентов. Решение - Server-Sent Events, Web Sockets.
- Тормозят, неустойчиво работают Web Sockets. Решение - TLS для них (wss).
Коллективная работа над проектом
Введение
Организация коллективной работы в рамках веб-студии - основа успеха. Решить эту задачу не сложно, всё зависит от настойчивости и дисциплинированности самого руководителя. Ему достаточно ответить на вопросы:
- Как организовать разработку в коллективе?
- Кто отвечает за костяк процесса?
- Какие риски следует минимизировать на начальном этапе производства?
- Как контролировать риски в процессе разработки.
В коллективной работе есть много нюансов.
Человеческий фактор
Творческая атмосфера. Как только в командах появляется какой-то прессинг членов команды, показуха, депрессивные настроения, то с методиками гибкой разработки можно попрощаться навсегда. Жесткие методики вроде Водопада могут ещё выдать какой-то результат, но качество работ упадёт и в этом случае.
Открытые коммуникации. Как можно проще должен быть реализован механизм коммуникации и в разработке и в проектировании. И с клиентом и между сотрудниками. Если при реализации проекта не созданы открытые эффективные коммуникации, то риски значительно возрастут.
Проблема рефакторинга
У разработчиков всегда есть желание что-то переписать в уже созданном коде. Сделать лучше не меняя функционала. Два подхода возможны к этой проблеме:
Первый. Разрешать это делать в ограниченные сроки. Но нужно суметь подать это клиенту, так как придётся объяснять почему студия тратит время (то есть деньги клиента) на то что уже есть и работает.
Второй. Если не прислушиваться к этой потребности, то код скоро может стать не оптимальным.
Нужен баланс между обоими путями. Нельзя запрещать полностью, но и нельзя поощрять излишнюю работу и "прокачку" программиста за счёт студии. Клиенту нужно суметь объяснить необходимость рефакторинга, если такая необходимость реально возникла. (Проще поддерживать и развивать проект - основные аргументы.) Если клиент входит в положение, то это серьёзно повышает мотивацию разработчика и качество системы.
В принятии решении о рефакторинге нужно ориентироваться на мнения ведущих разработчиков, так как точность оценки объективной необходимости рефакторинга прямо пропорционально зависит от уровня профессионализма разработчиков.
Совет потенциальному клиенту: Есть команды, которые тонут в собственных багах. Они делают 5-6 коротких итераций по разработке, потом баги порождают новые баги. Рекомендация: задавайте короткие 2-3-хнедельные итерации и смотрите, тянет студия или нет. Если начнутся циклы по исправлению ошибок, то от такой студии надо уходить.
Технические особенности командной работы будут рассмотрены далее.
Эффективная работа команды
Эффективная работа команды над проектом зависит от нескольких факторов:
Менеджер проекта
Менеджер проекта - не обязательно отдельная штатная должность в рамках студии, это скорее организатор процесса, в котором он участвует сам. В небольших студиях это может быть самый опытный программист или авторитетный член команды.
В инженерных дисциплинах цель команды - работающая система (и как следствие удовлетворённый клиент). Система должна работать эффективно, дёшево решать задачи клиента. Поэтому любые позиции внутри команды, которые эту цель отодвигают (личные амбиции, желание "прокачаться" вместо решения задач) - это плохо. Нужно создать атмосферу, когда всплывают идеи, как решить задачу проще, эффективнее, прозрачнее - это хорошо. Менеджер проекта должен это понимать.
Не тот человек в качестве менеджера проекта - большой риск. Человек для этой роли - достаточно уникальный, он должен совмещать в себе понимание технологий проектирования и понимание технологий управления.
В сложных проектах командой должен управлять менеджер-технолог, понимающий техническую суть проекта. Ни в коем случае вопросы бизнеса не должны влиять на процессы разработки. Задача перед программистами должна при этом ставиться так, чтобы у них "загорелись" глаза.
Подбор команды, организация её работы и мотивация
Что нужно учитывать при подборе команды?
- Образование. Конечно, бывают гениальные самоучки, но их число не велико. А системные знания - это основа основ.
- Опыт работы, проекты, роли в этих проектах. Практический опыт надо оценивать не только с точки зрения сложности задания, но и с точки зрения работы в команде.
- Владение технологиями.
- Возраст, мотивация.
- Лидерство.
- И в последнюю очередь - владение сертификатами Битрикс. Потому что обучение работе в рамках платформы Bitrix Framework - задача не сложная, если есть системные знания программирования и опыт работы.
В штате команды должен быть как минимум один качественный программист. Такой, у которого "горят" глаза при виде сложной задачи. Верстальщик, умеющий вставлять простенький PHP код - не программист. Такого достаточно для сайтов-визиток, для кастомизации шаблонов компонентов Bitrix Framework. Но для сложного и крупного проекта необходим программист с высокой квалификацией, серьёзным портфолио. В крайнем случае - с высшим образованием.
И чем сложнее проект, тем больше должно быть настоящих программистов. Это не означает, что в команде не может быть неопытных разработчиков. Такие могут выполнять несложные задачи, попутно совершенствуясь в собственном мастерстве. Обучение у опытных мастеров - лучший способ вырасти в профессионала.
Подбор команды при использовании Bitrix Framework:
Отдавайте предпочтение разработчикам имеющим хотя бы онлайновые сертификаты о прохождении курсов. К сожалению, разработчики не знакомые с архитектурой и технологиями Bitrix Framework пишут неоптимальный код.
Разработчик должен уметь смотреть на систему глазами клиента и менеджера, знать административную и публичную части.Однако у программистов всегда есть соблазн залезть в "высшие материи". Попробовать технологии, которые он ещё не использовал. И в этой ситуации может возникнуть "вилка" между желаниями и возможностями. Не забывая про свободу программистов нужно постоянно держать в уме то, что проектирование должно быть проведено адекватно поставленной технической цели, разработка должна быть простой, надёжной и расширяемой. Менеджер-бизнесмен в ситуации сложного, высоконагруженного проекта может не справиться с этой задачей.
Вопрос денежного стимула не прост. С одной стороны программист с "горящими глазами" может работать достаточно долго "за идею". Однако, "обиженный" программист работает не в полную меру, а "сильно обиженный" может представить даже угрозу при слабом контроле за качеством кода и его безопасностью.
С другой стороны, у каждого есть "внутренняя оценка" своих качеств и несоответствие этой оценке (в сторону завышения) только развращает сотрудников. Деньги должны быть достойными, но не лёгкими.
Один из серьёзных факторов риска - незнание продукта и предметной области проекта. С незнанием продукта, думается всё понятно. По предметной области должна быть возможность получить чёткую, конкретную и быструю консультацию к заказчика. Это должно быть оговорено с ним (и понято им) ещё на стадии переговоров.
Другой фактор риска - недисциплинированность программистов. Она вызвана разными причинами: от незнания продукта через обычную невнимательность, до чрезмерного увлечения новыми технологиями.
Инструменты коллективной работы
Правильно организованная коллективная работа обязательно предполагает использование IDE, баг-трекеров, систем накопления информации типа Wiki, других инструментов. Об этом в курсе есть отдельная глава.
Знание предметной области заказа
Разработчик не должен разбираться в предметной области. Иначе ему некогда будет программировать. Разработчик должен иметь возможность получать ответы на свои вопросы в идеале - сразу, "по жизни" - в течение разумного времени. Получать конкретные ответы на конкретные вопросы.
Вот, например, фраза из ТЗ: «покупатель может принадлежать группе клиентов, получающих скидку». Вопросы, которые возникнут у программиста:
- Покупатель может входить в несколько групп?
- Как в этом случае рассчитывается скидка? Нужна формула.
- На какой срок покупатель включается в группу?
- При удалении покупателя из группы его уведомить? По e-mail или смс?
- и т.д, и т.п
Точные и формальные ответы на эти вопросы должны быть понятны разработчику перед началом работы. Эти ответы - зона ответственности менеджера проекта. Он должен сам давать ответы или найти того, кто ответит разработчику точно на возникающие вопросы по предметной области. Например, можно включить в проектную группу аналитика, эксперта или толкового представителя заказчика, который будет не спать ночами, пока в деталях не раскопает все тонкости и логику проектируемой системы. Или менеджер должен сам погрузиться в проект, предметную область и сделать эту работу сам.
Способ снижения рисков в ситуации с пониманием предметной области простой: проверьте цепочку формирования требований от менеджера, аналитика - к программисту.
- Задайте менеджеру веб-проекта пару вопросов, уточняющих детали предметной области и если в ответ польется "вода", то примите меры по экстренной мотивации. Или замене менеджера.
- Выясните насколько клиент, как эксперт в предметной области, участвует в процессе проектирования и уточнения требований. Или он ждет и грезит?
- Поговорите с разработчиками — кто и как отвечает им на вопросы по предметной области, как четко и непротиворечиво? Им все понятно?
Материалы по теме
- Как изучать Bitrix Framework? (учебный курс)
- Как подобрать разработчиков? (тема на форуме)
Как выбрать методологию и оценить сложность задачи
Выбор методологии
Методология определяет многое: состав команды, способ взаимодействия с клиентом, порядок работы и многое другое.
При выборе методологии надо понимать самим и разъяснить клиенту, что требования к проекту у клиента будут меняться. И чем жёстче используемая методика, тем сложнее вносить изменения в требования. Клиент изначально может не осознавать части своих требований, часть требований может поменяться со временем, это объективный процесс. Поэтому, если клиент настаивает на жёстком процессе, то он должен быть готов к усложнению и удорожанию процесса разработки.
Выбор методологии зависит и от состава команды, имеющейся в распоряжении студии. Если же клиент настаивает на каком-то конкретном процессе, то придётся искать людей под него.
Чем сильнее в профессиональном плане команда, имеющаяся в распоряжении, тем более гибкие методологии можно использовать. Для высокопрофессиональных сотрудников можно использовать XP - экстремальное программирование. Вчерашние студенты в режиме XP завалят самый простой проект. Для бывших студентов чем более формализован процесс, тем работа будет успешнее. С такими сотрудниками придётся применять Водопад.
Слабая команда и один сильный разработчик
Первое. Всё максимально формализовать и упростить. (Что это значит в плане использования, например, Bitrix Framework? Использование стандартных компонентов, использование стандартной административной части, сделать всё, чтобы люди как можно меньше написали кода. Править компоненты, шаблоны, вёрстку править, настройки менять, не более.)
Второе. Построить процесс разработки максимально близкий к Водопаду. Неопытный сотрудник не может правильно оценить сложность задачи и подобрать адекватные методы её решения. Для него опытный разработчик должен всё расписать в виде подробного плана проекта с диаграммой Ганта.
Проект лучше разбить на итерации большой продолжительности (2-3 месяца) для снижения рисков. Первый этап - это создание сайта с интегрированной вёрсткой на основе стандартного функционала. То есть всё то, что можно реализовать без сложных работ, предъявить клиенту как результат первого этапа.
Второй и последующие этапы - какая-то часть сложного высоконагруженного функционала, например, объёмный каталог. Создаётся, тестируется, накатывается на сделанное, сдаётся.
Средняя по силе команда
В этом случае возможна меньшая формализация итерационного процесса. Можно не делать аудит кода, можно делать меньше веток контроля версий, детально не указывать параметры настроек компонентов, модулей, можно сделать более короткими итерации (примерно месяц - полтора). Для таких команд подходит RUP, Agile, Kanban.
Сильная команда
Сильная команда постоянного состава - редкий случай. Подходят все виды процессов, выбирать которые нужно в зависимости от проекта. Сложные и большие проекты могут потребовать Водопад и для сильной команды, но в большинстве случаев сильные команды работают по технологиям XP, с элементами Agile, Scrum или Continuous Integration. Итерации могут становиться короче, примерно 2-3 недели.
Как оценивать необходимое время и сложность задач
Точность оценки зависит от качества проектирования и от квалификации разработчиков. Как правилно, для оценки используется технология Planning Pocker.
Технология крайне проста: оглашается задача, обсуждается и разработчики выкидывают карты с указанием времени необходимого на реализацию этой задачи. Время на картах указано в числах Фибоначи.

Большое расхождение в оценках времени исполнения говорит о слабости команды, либо неясной задаче. В слабых командах лучше не проводить коллективную оценку необходимого времени, а довериться мнению сильного разработчика. Менеджер не должен оценивать сам сложность задач. В этом случае программисты могут выдавать некачественный код, лишь бы успеть в срок. Но если разработчик недобросовестный либо хитрый, то он будет стремиться завысить срок. Менеджер должен учитывать и этот риск.
При проведении оценки задач Planning Pocker'ом менеджер должен быть уверен, что задача ясна команде. Иначе её невозможно правильно оценить. Будут названы либо завышенные сроки, из боязни не успеть, либо заниженные, из-за недооценки сложности. В обоих случаях сроки окажутся под риском срыва, а качество исполнения - невысоким.
Можно применять модификацию Planning Pocker, когда разработчики оценивают задачу по критерию: Просто\Средне\Сложно. Если у менеджера уже есть сложившаяся оценка сколько времени уйдёт на задачу каждого типа.
Методологии разработки
Минусы и риски работы от потребностей
Разработка сложного проекта требует системных действий. Если небольшой проект с небольшим числом разработчиков (не более 3-х) можно реализовывать по принципу текущих потребностей, то со средними и большими такая организация процесса уже не будет эффективной.
Минусы работы от потребностей следующие:
- С заказчиком согласуется расплывчатое ТЗ. ("В целом всё понятно, а там додумаем!")
- Отсутствие проектирования. ("Разработчики у вас умные, сами сообразят что и как делать.")
- Разработчик делает лишь бы работало и побыстрее.
- Тестировщик проверяет разработку бессистемно.
- Аврально вносятся выявленные изменения.
- Не ведётся документация ни на проект, ни на код.
Это приводит к следующим рискам:
- Систему все сложнее развивать. Причём сложность увеличивается по экспоненте.
- Большие трудности входа в проект новых разработчиков: им сложно разобраться, что приводит к попыткам всё переписать с нуля.
- Монолитности создаваемой системы, которая боится изменений. Любое изменение порождает множество ошибок.
- Никто не помнит, как все работает (даже Заказчик)
- Крайне сложна задача тестирования. Никто не знает, как все проверить.
Создание определённого алгоритма работы внутри веб-студии помогает не только в плане внутренней организации. Такой процесс упорядочивает и взаимодействие с клиентами, особенно с большими и крупными компаниями, когда от заказчика может выступать несколько человек.
Типы процессов создания проектов
Существует несколько типов процессов создания программного обеспечения. Для веб-студий можно порекомендовать:
- Водопад или Каскадная модель, в которой процесс разработки выглядит как поток, последовательно проходящий фазы анализа требований, проектирования, реализации, тестирования, интеграции и поддержки.
- Итеративный процесс. В конце каждой итерации (в идеале продолжающейся от 2 до 6 недель) проектная команда должна достичь запланированных на данную итерацию целей, создать или доработать проектные артефакты и получить промежуточную, но функциональную версию конечного продукта.
Как разбивать проект на итерации? Самое первое что нужно сделать - это разбить на стандартный функционал CMS и нестандартный, который надо дописывать. Первый этап - это всегда реализация стандартного функционала. На этом этапе и студии и клиенту легко определиться продолжать ли дальнейшую работу вместе. Расставание на этом этапе - самое безболезненное для обеих сторон.
Последующие этапы - реализация нестандартного функционала по мере возрастания сложности. - Agile. Вид итеративной разработки, основанный на динамическом формировании требований и обеспечения их реализации в результате постоянного взаимодействия внутри самоорганизующихся рабочих групп, состоящих из специалистов различного профиля.
- Экстремальное программирование XP. Вид итеративного процесса, основанный на непрерывности разработки с коротким циклом обратной связи.
- Kanban. Модель для веб-студий, работающих с большим количеством заказов. Позволяет сократить время прохода задачи до состояния «готовности».
- Continuous Integration. Выполнение частых автоматизированных сборок проекта с целью минимизации рисков.
Примечание: Эта глава не ставит своей целью дать детальное пояснение той или иной технологии разработки. Её задача - дать общее представление о технологиях и за счёт этого показать направление поиска оптимальных для вас методик. О деталях технологий поинтересуйтесь у Yandex'а.
Видео
Выбор и внедрение процесса: от водопада до Kanban/XP/RUP
Водопад или Каскадная модель
Каскадная модель (англ. waterfall model) – модель процесса разработки программного обеспечения, в которой процесс разработки выглядит как поток, последовательно проходящий фазы анализа требований, проектирования, реализации, тестирования, интеграции и поддержки.
Каскадная модель подходит для больших проектов с большими сроками, штатами и функционалом: сложные системы в банковской сфере, большие интернет-магазины, проекты с большим числом пользователей и так далее. ТЗ для таких проектов может занимать тысячи страниц, но для разработчиков такой процесс фактически идеален: все описано, всё завизировано и утверждено, сделано максимально всё, чтобы понять как должна работать система.
Водопад даёт качественный результат в силу чёткого следования порядку работы, отсутствию смены требований.
Минус системы: при необходимости изменений возникает большой объём «бюрократических» работ: согласование и утверждение со всеми заинтересованными лицами.
Итеративный процесс
Итеративная разработка - это выполнение работ параллельно с непрерывным анализом полученных результатов и корректировкой предыдущих этапов работы. Проект при этом подходе в каждой фазе развития проходит повторяющийся цикл: Планирование — Реализация — Проверка — Оценка (англ. plan-do-check-act cycle).
Предпочтителен в случаях когда система сложная и непонятно как она должна работать в конечном виде. Основной принцип: пошаговое приближение к конечной цели. То есть сделать от начала и до конца часть системы, внедрить, собрать фидбек, обсудить, скорректировать процесс и перейти к следующему шагу. Итерация может быть большой (2-3 месяца) или нет (2-3 недели).
Метод очень эффективен в плане взаимодействия с клиентом. Особенно с тем, кто толком не представляет чего он хочет. Улучшается обратная связь с Заказчиком – он принимает каждый этап (итерацию). Выпуск проекта в стартовой, урезанной конфигурации позволяет Заказчику самому понять куда идти дальше. И он идёт дальше вместе с вами.
Метод позволяет брать в работу приоритетные задачи и риски. Распределяется нагрузка равномерно по всему сроку, то есть проектировщики не сидят без дела, после выполнения проектирования, как было бы в методе "водопад", а после выполнения первого этапа, когда программисты только начали работу, переходят ко второму. В это время дизайнеры могут заниматься уже третьим этапом.
Затраты на проект распределяются равномерно, а не в конце проекта. Это важно для Заказчика.
Сложности метода:
- Нужно внедрять, обучать людей;
- Много ролей, требующих узкой специализации;
- Требуется постоянный контроль, поддержание процесса.
Итеративный процесс имеет несколько видов: Agile, XP, Kanban, RUP и другие.
Канбан
Kanban - модель разработки, в условиях ограничения числа выполняемых задач каждым разработчиком.
Модель подходит для веб-студий, работающих с большим количеством несложных заказов. Работа по этой модели - это работа без конечных сроков. Клиент платит за то, что студия потратила время. При доверии со стороны клиента, что программист работает эффективно и поставленную задачу реально можно было решить именно за то время, которое на неё потрачено.
Канбан позволяет сократить время прохода задачи до состояния «готовности». Количество незавершённой работы разработчика должно быть ограничено. Новая задача может ставиться только тогда, когда какая-то из существующих передаётся следующему элементу производственного цикла. Kanban (или сигнальная карточка) подразумевает, что производится некое визуальное оповещение о том, что можно задавать новую работу, так как текущий объём работ не равен принятым лимитам.
Смысл системы с точки зрения разработчика: максимально упростить бюрократию и дать человеку просто работать над небольшим числом задач.
Смысл системы с точки зрения веб-студии: снижение времени прохождения задачи через группу специалистов до её релиза. Система позволяет создать работнику такие комфортные условия работы, что бы задача проходила через все эти этапы быстро. При этом происходит визуализация задач, облегчающая контроль.
Нет планирования времени. На доске размещаются столбцы специалистов. В столбцах специалистов указывается лимит на число задач, которые "висят" на специалисте. Больше этого числа задач им нельзя ставить. Не должно быть такого, что прибегает кто-то и: "Срочно нужно сделать!", все делается только в порядке установленном на доске.
Менеджер может визуально отслеживать состояние дел: где происходит "затык" в работе, кто отстаёт и начать разбираться почему это происходит и принимать меры по устранению проблем.
На одной доске можно вести учёт всех проектов, если, например, определить для каждого проекта свой цвет задач. На карточках можно указывать время начала работы и время её завершения.
Agile/Scrum
Принципы организации работы
Agile - серия подходов к разработке программного обеспечения, ориентированных на использование итеративной разработки, динамическое формирование требований и обеспечение их реализации в результате постоянного взаимодействия внутри самоорганизующихся рабочих групп, состоящих из специалистов различного профиля.
Scrum - методология гибкой разработки программного обеспечения. Scrum чётко делает акцент на неотвратимости срока демонстрации готового функционала клиенту.
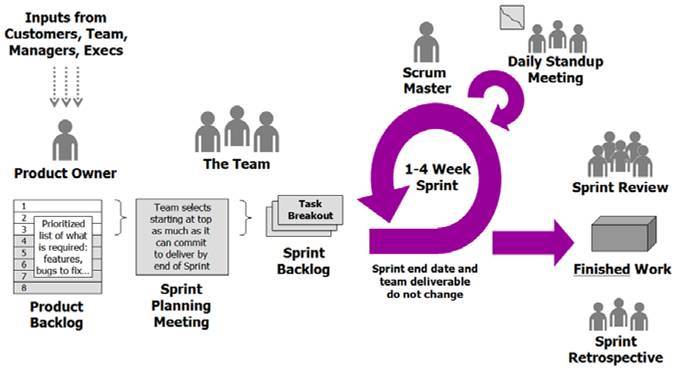
Работа организуется по следующему принципу:
- Менеджер проекта (Product owner) собирает все потребности, "хотелки" по продукту, сценарии использования в списке задач (Product backlog).
- На основе Product backlog на собрании перед циклом разработки (Sprint planning meeting) составляется круг задач (Sprint backlog) решаемых в этой итерации (Sprint'e)
- Производится цикл с разработкой, тестированием, демонстрацией результата заказчику.
- По результатам Sprint'а проводится публичный анализ (Sprint Retrospective) результатов работы.
- Цикл повторяется нужное число раз до выхода готового продукта.
Составляющие методологий
Менеджер проектов - Product owner
Ключевой человек в технологии Scrum. Он закрывает команду от Клиента. Если Клиент - корпоративный, то с его стороны участвует несколько (до нескольких десятков) сотрудников. Доступ этих сотрудников к разработке напрямую должен быть исключён. Это делает Product owner.
Product owner выстраивает взаимодействие с Клиентом. Если Product owner "прогнётся" под наплывом требований со стороны Заказчика, Scrum становится бесполезен. Задача очень трудная, для человека с крепкой психикой.
Product owner говорит со всеми менеджерами, директорами, аналитиками и так далее и вырабатывает понимание того как должна работать создаваемая система. И он отвечает за продукт. Он знает ответы на все вопросы по продукту, что позволяет разработчикам чувствовать стабильность при работе, что завтра не поменяются требования и не придётся всё переделывать.
Для команды Product owner формирует ранжированный список "хотелок" (Product backlog) из которого и формируется список задач на конкретный цикл (Sprint backlog).
Список задач - Product backlog
Список потребностей, сценариев использования описываются в таблице Product backlog. Список линейный, приоритезированный, предварительно оценённый на трудозатраты по простейшей схеме: простой, средний, сложный.
Product backlog позволяет легко проверять работу менеджеров: скорость работы, возможные проблемы. В том числе и в плане работы с клиентами: если Клиент не может высказать внятно свои потребности (составить backlog), то, возможно, есть смысл сменить методику работы с ним.
Планирование цикла - Sprint planing meeting
Срок собрания - не более одного дня. Команда с подачи Product owner'а отбирает задачи из Product backlog, оценивает их во временных единицах (как правило, это человеко-часы) на выполнение. Оценка проводится в "игровой форме" (Planning poKer), при большом разногласии в оценке может проводиться в несколько туров с периодами обсуждения.
Задачи конкретного цикла - Sprint backlog
Отобранный из Product backlog список задач на данную итерацию (Sprint). Задачи отбираются с учётом выделенного времени на Sprint и выставленных каждой задаче временных оценок.
Цикл разработчки - Sprint
Небольшой по срокам (1-4 недели) цикл разработки. Разработка ведётся на основе Sprint backlog. Учёт работы можно вести по аналогии с доской Kanban:
Учёт "сожжённого" времени, представленный в графической форме, позволяет судить о процессе производства. Если процесс идёт нормально, то часы "сжигаются" равномерно. Если скорость "сжигания" замедлилась или встала совсем, то на лицо проблемы, которые требуют вмешательства руководства.
Примечание: Учёт скорости нужно вести систематически, от Sprint'а к Sprint'у. Это позволяет прогнозировать сроки релизов и оптимизировать процесс разработки.
Команда - Team
В Scrum'е нет личности. Работа - коллективная, ответственность коллективная. Это порождает как преимущества, так и проблемы. Есть сотрудники - таланты, которые просто не могут работать в команде, но они нужны. Есть просто недобросовестные товарищи. И со всеми нужно работать.
Кроссфункциональность не подразумевает универсальность каждого участника команды. В команде всегда кто-от что-то лучше делает, чем другой. Под кроссфункциональностью подразумевается тесное сотрудничество между её участниками.
Размер команды для каждого проекта нужно подбирать. Оптимально - 5-7, при большем количестве возникают проблемы контроля.
Считается, что если Sprint провален, то провалила вся команда. Но в реальности провалы бывают из-за конкретного человека. Как быть в такой ситуации?
Но если команда - настоящая, слаженная команда, то этот принцип работает просто великолепно.
Управляющий процессом - Scrum master
Авторитетный и уважаемый всеми участниками разработки человек. Его задача - следить за тем, чтобы поддерживался процесс Scrum'а. Специальность этого сотрудника в рамках проекта - не важна. Это может быть верстальщик, программист. Он следит за тем, чтобы люди не расслаблялись, не тусовались, а работали. При этом он не командует, а все вопросы решаются только за счёт авторитета.
Другая функция - устранять препятствия, возникающие перед группой разработчиков. Не боясь при этом поругаться и "повоевать" за нужное оборудование, условия работы и прочее.
Ежедневное планирование - Daily standup meeting
Ежедневное, короткое (не более 15 минут) собрание участников для оценки сделанного накануне, задач на день, возникших проблем. Идея в том, чтобы каждый в команде знал кто чем занимается, к кому с какими вопросами обращаться, кому, если нужно, помочь.
Условие готовности задачи - Definition of Done
Очень важно правильно определиться с этими условиями. Они должны быть чётко оговорены: проверено тестировщиками, проверено безопасниками, проверено сисадминами, проверено Product owner'ом и так далее.
Демонстрация результатов - Sprint review
Демонстрация клиенту результатов цикла. Контролирующее, организующие и вдохновляющее на дальнейший труд мероприятие. Клиент видит, что работа идёт, есть за что платить. Команда видит оценку своей работы.
Внутрикомандная оценка этапа - Sprint retrospective
Оценка результатов цикла самой командой, оценка механизма разработки. В целом оценивается результат и ищутся способы как сделать лучше.
Плюсы и минусы технологии
Плюсы:
- Просто внедрить
- Разработчикам обычно нравится
- Прозрачность проекта
- Ориентация на результат
Минусы:
- Не все люди сработаются, сложности "человеческого фактора".
- Издержки на «болтовню» 10-30%
- Качество веб-системы может сильно пострадать, если неверно организован процесс и неверно заданы Definition of Done.
Видео
Экстремальное программирование
Экстремальное программирование
Экстремальное программирование (XP) - вид итеративного процесса, основанный на непрерывности разработки с коротким циклом обратной связи.
Экстремальное программирование - не методика, а несколько базовых принципов работы. В чистом виде применяется крайне редко, чаще идёт в связке с какими-то итеративными методами. Использование XP требует наличия высокопрофессиональной команды, постоянного контакта с заказчиком, способности гибко реагировать на изменения требований заказчика и, как следствие, к рефакторингу кода.
Базовые принципы XP
- Короткий цикл обратной связи (Fine scale feedback)
- Разработка через тестирование (Test driven development)
- Игра в планирование (Planning game)
- Заказчик всегда рядом (Whole team, Onsite customer)
- Парное программирование (Pair programming)
- Непрерывный, а не пакетный процесс
- Непрерывная интеграция (Continuous Integration)
- Рефакторинг (Design Improvement, Refactor)
- Частые небольшие релизы (Small Releases)
- Понимание, разделяемое всеми
- Простота (Simple design)
- Метафора системы (System metaphor)
- Коллективное владение кодом (Collective code ownership) или выбранными шаблонами проектирования (Collective patterns ownership)
- Стандарт кодирования (Coding standard or Coding conventions)
- Социальная защищенность программиста (Programmer welfare):
- 40-часовая рабочая неделя (Sustainable pace, Forty hour week)
В XP многое непривычно. Для многих программистов непривычна работа в паре, непонятно требование писать тесты до написания кода, который они должны тестировать. Профессионализм исполнителей должен быть таким, чтобы разработчик мог в любой момент "въехать" в любой участок кода, поменять его и гарантировать работоспособность своих изменений в рамках всей системы.
Continuous Integration
Continuous Integration
Continuous Integration - это практика разработки программного обеспечения, которая заключается в выполнении частых автоматизированных сборок проекта для скорейшего выявления и решения интеграционных проблем. Частый и постоянный выпуск релизов позволяет модулям системы постоянно взаимодействовали между собой целостно, что снижает риск срыва сроков.
Как элемент используется в Экстремальном программировании.
Эта практика рекомендуется для больших проектов, имеющих большой временной период для исполнения. То над чем вам предстоит работать и что поддерживать, а не просто сделать и сдать. В маленьких проектах в этой технологии просто нет необходимости, лучше использовать Kanban или SCRUM.
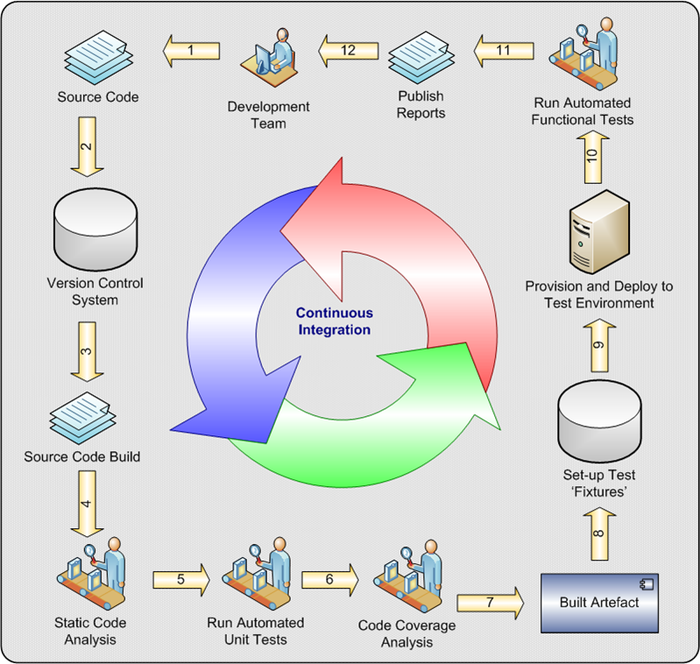
Требования к производству
Требования к производству по практике Continuous Integration
- Использование системы контроля версий.
- Создаются ветки, система аудита и политики коммита.
- Используются обработчики событий – hooks.
- Частые коммиты, лучше – раз в день.
- Модульные тесты
- Тесты можно делать не сложные.
- Можно не использовать PHPUnit, Simple Test
- Версии Bitrix Framework на тестовом и "боевом" серверах всегда должны совпадать.
Видео
Continuous Integration — от простого к сложному
Организация инфраструктуры разработки
Введение
Несколько советов о том как организовать внутри вашей студии процесс разработки.
Использование удобных инструментов для работы существенно ускоряет процесс. Можно программировать и в Notepad'е, но любой современный инструмент обеспечивает "малую механизацию", существенно облегчая труд разработчика:
- Подсветка кода (ошибок, функций) - резко снижает число ошибок;
- Подсказки параметров функций/методов - ускоряют разработку;
- Встроенная справка по PHP - уменьшает число ошибок, ускоряет работу;
- Дерево проекта, структура классов - упрощает навигацию;
- Структура сущностей программы, теги PhpDocumentor - облегчают работу по документированию кода;
- Codestyle - настраивается один раз и затем облегчает работу;
- Встроенная работа с удаленными серверами - упрощение выполнения обыденных операций.
Существует достаточно много Интегрированных сред разработки (IDE). Каждая из них имеет свои сильные и слабые стороны. На решение какую использовать в большей степени влияют привычки и вкусы конкретного разработчика, но не представляется правильным использование разных сред в рамках одной студии. Купите одну и пусть все разработчики научатся в ней работать. Необходимо стандартизировать настройки IDE в рамках вашей организации.
Кроме IDE необходимы инструменты для хранения информации по стандартам и методам работы в команде и по работе над конкретным проектам. Обязательным инструментом также можно назвать багтрекер.
Видео
Инструменты для эффективной работы команд - IDE, контроль версий, трекеры, wiki
Особенности использования IDE и Bitrix Framework
Рассмотрим несколько схем использования:
Схема 1
Оптимальный результат для разработчика: отдельный выделенный сервер на котором стоит виртуальная машина Linux (либо вообще сервер на Linux), установлена IDE, папка с проектом, установлен вебсервер с ядром Bitrix Framework. В этом случае IDE может локально всё проиндексировать. В такой конфигурации чрезвычайно удобно работать одному разработчику, но над проектом работает несколько человек. Соответственно, нужно делать (желательно автоматически) deploy, нужно иметь сервера тестирования, "боевые" сервера. Как организовывать взаимодействие всего этого? Предложенная схема - для самых простых проектов.
Схема 2
Часто встречается схема для IDE PHP Storm: у разработчика локально размещена IDE, ядро Bitrix Framework, локально скопирован код проекта, который синхронизируется (через контроль версий, либо ftp) на удалённый сервер. На удалённом сервере размещён веб-сервер и ядро Bitrix Framework.
Плюсы схемы: подсказка по ядру работает
Минусы схемы: возникают сложности с синхронизацией ядра Bitrix Framework, так как оно синхронизируется достаточно долго, и сложности с обновлениями ядра.
Схема 3
Более удобная схема для IDE, поддерживающих sftp: локально у разработчика ничего нет. Проект находится либо на shared-диске, либо на удалённом сервере. Разработчик обращается к нему напрямую. В этом случае возникает проблема индексации, когда IDE должна проиндексировать всё удалённо по сети.
Схема 4
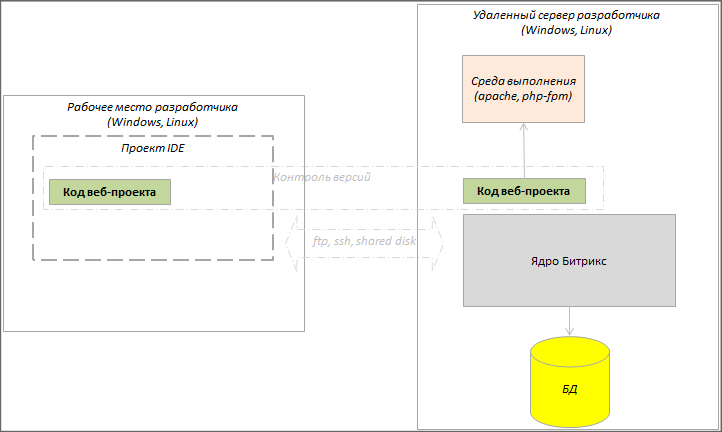
Последняя из возможных схем: локально хранится только код проекта, ядро Bitrix Framework не индексируется. В этом случае подсказки работают только по проекту, по ядру не работают. В этом случае лучше использовать документацию API по продукту.
Материалы по теме
- Инструменты для разработки под 1С-Битрикс (статья на habrahabr)
- Продуктивное использование PHPStorm (статья на habrahabr)
- Какую IDE вы используете для разработки на Битрикс (тема на форуме)
Отладка кода
Отладка кода
К сожалению, веб-студии редко используют инфраструктуру отладки. Традиционно для этого используют команды echo, die. Этот вариант медленный и чреват ошибками.
В виртуальной машине BitrixVM уже установлен Xdebug. Подключить его к IDE не сложно.
Отладка методом breakpoints - классическая технология отладки, позволяющая отслеживать какие-то сложные моменты, например, рекурсии.
- Задайте в скрипте breakpoints, значение которой, при необходимости, можно поменять в памяти, не меняя самого скрипта. В нашем примере это - а.
- Запустите сессию отладки.
- Если случился breakpoints, то можно найти в списке переменных а и поменять её значение:
Примечание: Для удобства рекомендуется использовать плагины к браузерам.
Инструменты для отладки
- Xdebug. Рекомендуется использовать только на тестовых серверах. Позволяет сделать бэктрейс выполнения страниц (и даже построчно) с указанием какая функция с какими параметрами использовалась, сколько памяти и сколько времени. То есть, можно отловить баги с производительностью.
- XHProf. Возможно использование и на "боевых" проектах. Позволяет строить иерархический граф вызовов функций, обращений к CPU и памяти. Позволяет увидеть "узкие места" при исполнении страницы, практически не замедляя создание самой страницы (например, сбор статистики по вызову функции). Помогает составить ТЗ на оптимизацию кода для разработчиков.
- Pinba. Инструмент для эксплуатации. Позволяет оценить как быстро и устойчиво работает код веб-проекта. Позволяет строить графики по времени выполнения.
- gdb – в основном на "боевых" серверах. Позволяет просмотреть трейс вызовов PHP. Используется, когда всё остальное уже не помогает.
- Apache /server-status Это первое что надо смотреть при торможении веб-приложения.
- Включенные логи медленных запросов PHP-FPM, NGINX, Apache, MySQL.
Материалы по теме
Управление версиями
Система управления версиями |
Система управления версиями (от англ. Version Control System, VCS или Revision Control System) - программное обеспечение для облегчения работы с изменяющейся информацией. Система управления версиями позволяет хранить несколько версий одного и того же документа, при необходимости возвращаться к более ранним версиям, определять, кто и когда сделал то или иное изменение, и многое другое.
Система контроля версий нужна даже одному разработчику. Она дисциплинирует, даёт устойчивость проекту. При работе нескольких разработчиков этот инструмент уже становится обязательным.
Для чего осуществляется контроль версий?
- Код всегда под контролем, в случае ошибок можно "откатиться".
- Контроль действий: всегда видно, кто из разработчиков что и когда делал
- Облегчает работу над новым, позволяет экспериментировать.
- Можно добавлять свои компоненты, шаблоны, модули.
- Удобно проводить аудит кода и аудит безопасности
Есть несколько систем: Mercurial, Git, Subversion и другие. Нет каких-то строгих рекомендаций кому что использовать. Система выбирается под собственные предпочтения.
Один из возможных вариантов организации управлением версий для проекта среднего размера:
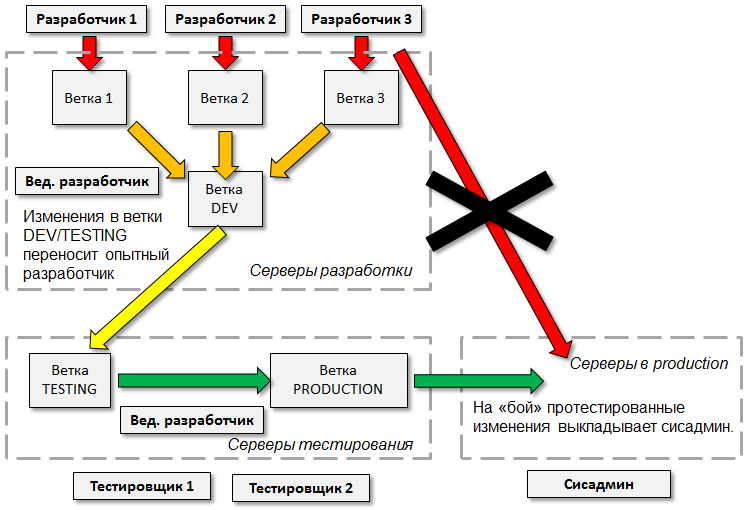
Каждый разработчик ведёт свою ветку на собственном виртуальном сервере. Ведущий разработчик объединяет эти ветки в единую ветку DEV. Полезно вести отдельную ветку для тестирования (TESTING). После тестирования системный администратор переносит всё на "боевой" проект
Примечание: В новом ядре D7 Bitrix Framework есть папка
/local, которая создана специально для работы с системой контроля версий.Другие инструменты в помощь разработке
Wiki
Для каждого проекта желательно заводить свою Wiki, ветку в Wiki или Базу Знаний, в которой будет фиксироваться всё, что связано с реализацией проекта: от составления/обсуждения ТЗ до прямых инструкций как коммитить ветки, как выкладывать обновления на боевой сервер и так далее.
Преимущества:
- Сохраняется история изменений страницы
- Можно задать права доступа к тексту
- Легко создать древовидную структуру проектов
- Легко искать информацию
- Можно прикреплять файлы/изображения
Трекер задач и багов
Когда проект разросся и стал большим без трекера задач невозможно организовать эффективную работу. Можно использовать Универсальные списки и Бизнес-процессы в Битрикс24, но этот продукт рассчитан всё же более на решение бизнес-задач и не всегда удобны программистам. Поэтому можно порекомендовать: Redmine, Mantis, Jira
Преимущества использования баг-трекеров:
- Задачи (баги) не теряются;
- Можно отследить общение по задаче (багу);
- В Wiki (и любом другом месте хранения информации по проекту) можно сослаться на задачи (баги) и их статус;
- Удобно состыковать с гибким процессом разработки (ссылка на коммит).
Проблема версионности БД
При работе нескольких разработчиков на собственных базах данных возникает проблема совмещение изменений от всех разработчиков на едином тестовом сервере.
Вариант решения
Все изменения БД оформляются скриптом php. (Обновления самой системы Bitrix Framework реализованы подобным образом.) В скрипте проверяется текущая версия структуры БД (например, в опции COption). Если версия новая, то выполняется блок кода, модифицирующий БД, и устанавливается новое значение версии в опциях (инкремент). Скрипт коммитится наряду с "обычными" файлами. Каждый модуль подключает этот скрипт (на каждом хите, но клиентам этот вызов не уходит), и когда он приходит из репозитория, выполняются запросы и версии структуры БД выравниваются.
Скриптов может быть несколько, например, для каждого модуля отдельный. На проекте, также, могут быть разные области и удобнее будет несколькими скриптами вносить изменения. Примерный вид скрипта миграции:
$current_version = intval(COption::GetOptionInt("main", "~database_schema_version", 0));
if ($current_version < 5) // 11.5.7
{
if (!$DB->Query("select TIME_ZONE_OFFSET from b_user WHERE 1=0", true))
{
$updater->Query(array(
"MySQL" => "ALTER TABLE b_user ADD TIME_ZONE_OFFSET int(18) null",
"Oracle" => "ALTER TABLE b_user ADD TIME_ZONE_OFFSET number(18) NULL",
"MSSQL" => "ALTER TABLE b_user ADD TIME_ZONE_OFFSET int NULL",
));
}
COption::SetOptionString("main", "~database_schema_version", 5);
}
if ($current_version < 6) // 11.5.7
{
if (!$DB->IndexExists("b_event_message", array("EVENT_NAME")))
{
$updater->Query(array(
"MySQL" => "CREATE INDEX ix_b_event_message_name ON b_event_message (EVENT_NAME(50))",
"Oracle" => "CREATE INDEX ix_b_event_message_name ON b_event_message (EVENT_NAME)",
"MSSQL" => "CREATE INDEX IX_B_EVENT_MESSAGE_NAME ON B_EVENT_MESSAGE (EVENT_NAME)",
));
}
COption::SetOptionString("main", "~database_schema_version", 6);
}
Примечание: Каждый из разработчиков команды собирает скрипт самостоятельно, включая в него необходимые проверки и т.д.
Возможна несколько иная реализация. Например, не подключать скрипт на каждом хите, а сделать хук в системе контроля версий на пулл.
Примечание: В любом случае, независимо от масштабности проекта и способа реализации, необходимо документирование на каждом этапе и универсальность кода.
Например создали таблицу в БД - опишите ее в Wiki, чтобы каждый программист при написании классов, обращающихся к БД знал имя таблицы, имена и параметры полей.
Примечание: В Маркетплейсе есть решение Миграции для разработчиков, облегчающее решение проблемы версионности.
Решение не является разработкой компании 1С-Битрикс, все вопросы по его работе обращайте к разработчику.
Тестирование и нагрузочные испытания
В главе рассказывается об ошибках на этапе проектирования и разработки, а также даны рекомендации, как проводить тестирование и нагрузочные испытания на этапе разработки и перед сдачей проекта клиенту.
Когда и где появляются ошибки
Откуда и на каких этапах берутся ошибки?
Программист
- Менеджер/аналитик не знает точного сценария использования будущего продукта.
- В техническом задании нет четких задач.
- Клиент сам не знает, чего хочет, или думает, что знает.
- От вопросов программиста на первых этапах вздрагивают, т.к представители клиента не компетентны в данной сфере.
Как снизить число ошибок в данном случае:
- Product Owner/менеджер/аналитик/представитель клиента – должны давать компетентные ответы (здесь можно внедрить KPI и премии) на вопросы программиста о предметной области.
- Представитель заказчика – должен быть также компетентен и доступен для общения.
- Проведен предварительный анализ сценариев использования, объектов и отношений между ними.
- На вопросы программиста должны быть ответы, обсуждения и принятие решений.
- Программист обеспечен современными инструментами разработки - IDE.
- Программист использует систему контроля версий – SVN, git, Mercurial.
- Программист документирует код или пишет «понятно» для себя и других.
- Программист может писать модульные тесты.
- Программист должен сделать функциональные тесты.
Всех ошибок все равно не избежать, но их будет значительно меньше.
При изменении каких-либо требований помогает использование понятного модульного/объектного кода, и опять же на помощь приходят функциональные и модульные тесты, которые позволяют быстро протестировать сделанные изменения в коде.
Верстальщик
- Разные браузеры и их версии.
- Разные разрешения экрана, ОС.
- Разные диалекты Javascript.
- Непонятные сценарии использования – снова некого спросить, прочитать (ну как так???)
- Можно знать одновременно PHP, JS, CSS и HTML
- НЕЛЬЗЯ УМЕТЬ одновременно PHP, JS, CSS и HTML! Нельзя экономить на специалистах.
Как снизить число ошибок в данном случае:
- Создать стенд с разными версиями браузеров.
- Selenium – автоматические тестирование.
Тестировщик
Тестировщику отводится отдельная роль в продукте:
- Тестировщик - это призвание, неподдельная любовь к совершенству в простоте.
- Тестировщик - это свежий взгляд.
- Тестировщик - это умный, злой и въедливый «параноик», знающий требования не хуже:
- Клиента;
- Менеджера проекта;
- Аналитика;
- Программиста.
Системный администратор
Чтобы не создавать ошибок в продукте сисадмин должен знать и уметь:
- Понимать архитектуру веб-проекта - какие сервера, какие порты связаны между собой.
- Где и что настраивается и почему.
- Обновлять программное обеспечение серверов.
- Знать о распределении сервисов по машинам.
- Проводить мониторинг, аналитику.
- Проводить нагрузочные испытания.
- Проводить резервное копирование.
Сисадмин должен обеспечивать контроль качества работы веб-проекта изнутри.
Клиент
Большую ценность в тестировании представляют ранние отзывы от клиента.
- Разработчик - не эксперт в предметной области, только клиент может более точно оценить работу системы перед сдачей проекта.
- Короткие итерации, Product Owner, демонстрации (Scrum) - нужно чаще встречаться с клиентом, показывать промежуточные этапы работы.
- Customer representative (представитель клиента в офисе разработчика) - наличие такого человека сильно упрощает процесс разработки и тестирования.
- Наличие хоть какой-то бюрократии и здравого смысла позволит не затягивать процесс разработки надолго.
- «Секрет» бета-версий: привлечение сотрудников клиента к тестированию позволит еще больше охватить область тестирования и увеличить качество тестирования. Последнее время выгоднее тестировать большие проекты, выпуская их как бета-версии.
Тестирование продукта как на этапе разработки, так и в процессе изменения какого-либо функционала в работающем проекте с помощью функциональных тестов очень важно. Причем, чем больше функциональных тестов покрывают систему, тем больше ошибок будет найдено на этапе тестирования и разработки.
Как проводить тестирование
Test Cases
Test Cases - это набор условий, при которых тестировщик будет определять, удовлетворяется ли заранее определённое требование. Чтобы определить, что требование полностью выполняется, может потребоваться много вариантов тестирования. Часто варианты тестирования группируют в тестовые наборы. (Wikipedia)
Как проверять каждый кейс:
- Описываем шаги в виде Test Case.
- Поддерживаем их в актуальном состоянии в wiki.
- Программист создает скрипты для тестировщика.
- Организуем тестовые сервера с тестовыми данными.
- После каких-либо изменений в веб-проекте необходимо заново проходить по связанным Test Case-ам.
- Иногда полезна матрица зависимостей:
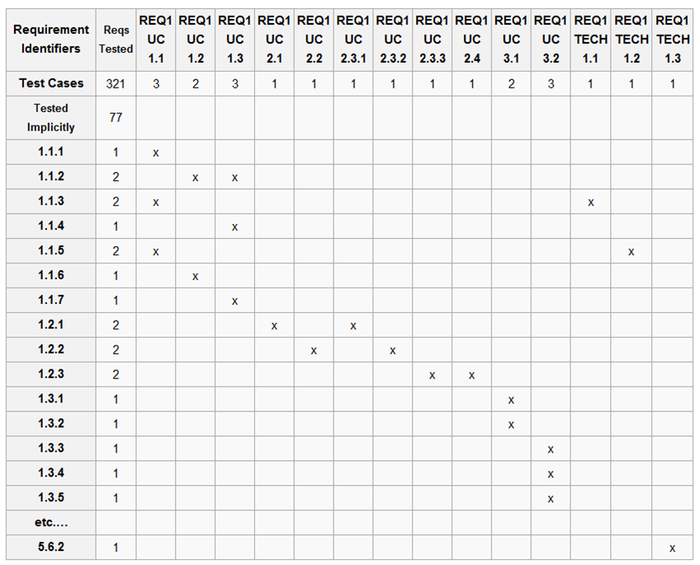
Модульные тесты - UnitTests
UnitTest - процесс в программировании, позволяющий проверить на корректность отдельные модули исходного кода программы.
Идея состоит в том, чтобы писать тесты для каждой нетривиальной функции или метода. Это позволяет достаточно быстро проверить, не привело ли очередное изменение кода к регрессии, то есть к появлению ошибок в уже оттестированных местах программы, а также облегчает обнаружение и устранение таких ошибок. (Wikipedia)
Полезны в ряде случаев:
- Когда пишете свой кастомный технически сложный функционал.
- Когда тестировать вручную очень долго и сложно.
- Когда создаете низкоуровневые утилиты/библиотеки.
- Когда пишете ООП-код в модулях.
В качестве инструментов модульного тестирования можно использовать: PHPUnit, SimpleTest или написать свой попроще.
Минусы:
- Клиент может не захотеть оплачивать время и ресурсы на эти тесты.
- Наличие в команде «фанатиков», которые требуют покрыть 100% всего функционала UnitTests-ами + DependencyInjection, серьезно замедляют работу.
- Вредны, когда используется не ООП-код, а простые скрипты компонентов.
- Объем кода UnitTests может превысить объем кода проекта. Любое изменение функционала - нужно переписывать тесты.
Функциональные тесты - Selenium
Функциональное тестирование - это тестирование ПО в целях проверки реализуемости функциональных требований, то есть способности ПО в определённых условиях решать задачи, нужные пользователям. (Wikipedia)
Можно автоматизировать часть ручных тестов c помощью Selenium:
- Пишется на Javascript «бот», эмулирующий действия пользователя.
- Тесты составляются просто.
- Можно постить формы, нажимать ссылки, обходить DOM.
- Значительно ускоряется «перетестирование» проекта.
- Систематизируется верстка.
Минусы:
- Поддерживать большой объем тестов Selenium непросто.
- Интерфейсы очень часто меняются - из-за чего нужно переписывать тесты.
- Верстка иногда серьезно усложняется под Selenium.
- Сложные сценарии трудно автоматизировать.
Попробуйте на практике, определите золотую середину.
Beta-тестирование
Одним из вариантов тестирования большого проекта является привлечение сотрудников клиента к тестированию. Либо, вообще, можно попробовать продать идею запуска проекта в качестве Beta. Это позволит найти незначительные и некритичные ошибки в проекте.
Монитор качества
Монитор качества - инструмент для проверки качества выполненного проекта перед сдачей его заказчику. Он позволяет решить задачу обеспечения прозрачного и гибкого процесса сдачи веб-проекта клиенту, повышая уровень гарантированного результата и снижая общие риски.
Монитор качества работает в продуктах «1С-Битрикс» и в каталоге веб-приложений для сайтов и корпоративных порталов «1С-Битрикс: Маркетплейс». Процедура сдачи включает обязательные и дополнительные тесты, в том числе, аудит безопасности PHP кода.
Монитор качества включает в себя:
- Структурированную методику управления качеством внедрения;
- Систему тестов для веб-разработчиков, набор рекомендаций для клиентов;
- Состоит из 26 обязательных тестов и ряда необязательных;
- Часть тестов - полностью автоматизирована. Их количество со временем увеличивается.
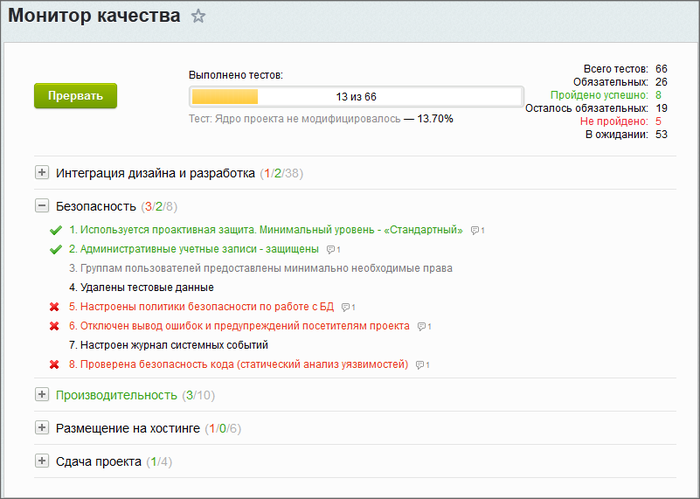
Зачем нужен контроль качества проекта?
Монитор качества дает дополнительные возможности разработчикам и клиентам:
- Плюсы для разработчика:
- Систематизация процедуры тестирования;
- Повышение качества создания интернет-проектов за счет систематизации производства;
- Формализация отношений с клиентом как на этапе сдачи, так и на этапе поддержки.
- Плюсы для клиента:
- Снижение рисков: чем раньше найдена проблема, тем дешевле ее устранить;
- Систематизация приемки проекта и запуска его в эксплуатацию: шаги расписаны, можно сосредоточиться на деталях;
- Формализация и упрощение взаимодействия с разработчиком на этапе поддержки и развития проекта;
- Снижение затрат на получение качественного результата;
- Высокая производительность и безопасность веб-решения.
Как проводить нагрузочное испытание
Для чего нагружать систему?
Нагружать систему нужно, т.к при нагрузочном тестировании выявляются узкие места и ошибки, которые не могут быть выявлены при обычном тестировании на этапе разработки:
- Невозможно заранее точно спрогнозировать поведение системы.
- MySQL иногда плохо масштабируется при нагрузке.
- Агенты Bitrix Framework и cron-скрипты могут "спутать все карты".
- Ошибки в конфигурации сервера выявляются долго и не сразу.
- Конкуренция потоков клиентов за ресурсы – файлы и т.п.
- Синхронное обращение к внешним сокетам/сервисам.
- Ошибки состыковки NGINX + Apache/PHP-FPM + MySQL + memcached.
- Перегрузка сетевого стека NGINX + Apache/PHP-FPM.
- Перегрузка сокета NGINX + Apache (unix domain socket).
- "Рассыпания" прекомпилятора php.
- и многое другое.
Нагрузочное тестирование нужно проводить всегда, хотя бы в базовом виде.
Критерии оценки
В зависимости от того, что хочет клиент от нагрузки, тот вывод и детальность отчета получаем в конце теста.
Пример отчета 1Гистограмма времени хитов: хитов менее 0.5 сек – 95%, хитов дольше 10 сек – 0,01%. Число ошибок < 0,01%
Пример отчета 2
Среднее время хита – 0.3 сек. Пиковое использование памяти скриптами - менее 128М. Время тестирования – 48 часов. Графики: munin по CPU, памяти, диску, трафику, детальные по mysql.
Подготовка к нагрузочному тестированию
- Устанавливаем инструменты анализа: munin, cacti.
- Настраиваем логгер состояния системы. Например - atop.
- Настраиваем опции логгирования NGINX, Apache, PHP-FPM, медленных запросов MySQL:
- Для NGINX - логгирование таймингов на upstream/backend.
- Для Apache/PHP-FPM - логгирование использования объема памяти.
- Для PHP-FPM - включается лог медленных запросов с backtrace.
- Также полезно написать несколько скриптов обработки логов:
- Гистограмма времени запросов.
- Гистограмма ошибок.
- Гистограмма расхода памяти.
Нагрузочное тестирование
- Тестируем на реальных объемах
Проводить нагрузочное тестирование нужно всегда на демо-данных, приближенных к реальным.
Что в таком случае происходит с системой:
- Важно «прикинуть» и воссоздать ожидаемый объем данных в БД.
- Тестирование на выборках, похожих на реальные.
- Компоненты могут отъедать много памяти на реальных выборках.
- Запросы к БД становятся тяжелыми.
- Запросы-убийцы и их влияние на веб-приложение
- Уход системы в swap.
Все эти процессы нельзя протестировать без нагрузки на этапе разработки.
Инструменты мониторинга:
- память, процессор - ps, top, free;
- диски - iostat, atop.
- "Утечка" контента
В процессе нагрузки возможны такие случаи из-за ошибки разработчика, что NGINX файлы перестает видеть как статику и начинает отдавать через Apache, заполняя в итоге все его свободные слоты.
Инструменты мониторинга - это лог-файлы:
apachetop –f /var/log/nginx/access.log
apachetop –f /var/log/httpd/access.log
- "Зависания" стека tcp/ip
Как выявить зависания стека tcp/ip:
- На графике числа обращений к Apache - провал.
- Резкий рост числа соединений между NGINX-Apache:
netstat –ntop. - Логи состояния БД:
show engine innodb status. - Логи netstat.
- Лог медленных запросов MySQL.
Частая ошибка в случае зависания стека tcp/ip кроется в запросах к БД.
- "Зависания" memcached
"Зависания" memcached происходит от резкого увеличения числа соединений к memcached.
Для выявления можно использовать команду:
netstat –ntop | grep 11211Решениями проблемы роста числа соединений могут быть:
- Настройка ядра:
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse echo 15 > /proc/sys/net/ipv4/tcp_fin_timeout
- Настройка опций запуска самого memcached:
memcached -d -p 11211 -u memcached -m 384 -c 10240 -P /var/run/memcached/memcached.pid
- Увеличение числа memcached-серверов (веб-кластерные решения).
- Настройка ядра:
Пример нагрузочного тестирования
В качестве примера нагрузочного тестирования опишем, как тестируется коробка "Битрикс24".
Описание и цели
Коробочная версия Битрикс24 уже проходила нагрузочное тестирование в 2015 году, и на тот момент были получены очень неплохие результаты. Тестирование продемонстрировало, что продукт, развернутый в компании из 15 тысяч сотрудников, работает стабильно и быстро.
За прошедшее время продукт сильно изменился, получил новые возможности и сценарии. Росло и количество крупных клиентов, появилось много заказчиков из ТОП-100 Forbes/РБК. В последнее время продуктом стали интересоваться действительно очень крупные клиенты с десятками тысяч сотрудников. Только за последние пару лет Битрикс24 был запущен в НЛМК, DNS, СУЭК, Полюс Золото, Почте России, ФК Открытие и многих других.
Одним из ключевых запросов от заказчиков такого уровня является надежность и стабильность в работе, производительность решения. Корпоративные порталы в крупных предприятиях, особенно после начала пандемии, стали понемногу переходить в разряд критических для бизнеса приложений. В них заводятся информационные потоки компании, организуются цифровые сервисы для сотрудников. В целом тенденция последних лет - это превращение интранета в единое корпоративное цифровое пространство для работы и коммуникации тысяч сотрудников.
Стало понятно, что кроме опыта аналогичных внедрений нужны новые подтверждения, что "Битрикс24" может справиться с такими нагрузками. Поэтому был запущен проект нового нагрузочного тестирования.
Партнером по проекту тестирования стала компания Selectel, традиционно предоставляющая оборудование для тестов. Также в работе над тестированием вендору помогали коллеги из QSOFT.
)
Цели тестирования
- смоделировать работу интранет-портала большой корпорации (100 тысяч сотрудников, большое количество демонстрационных данных);
- обеспечить методику тестирования, максимально близкую к поведению пользователей в реальной жизни;
- продемонстрировать стабильную работу портала без наличия ошибок в случае одновременной работы с порталом трети от всех сотрудников корпорации (не менее 30 тыс.) на доступном оборудовании;
- подтвердить эффективность технологии Веб-кластер в продукте 1С-Битрикс24: Enterprise;
- обеспечить уверенную одновременную работу примерно 1/3 из общего числа сотрудников и среднее время отклика портала в районе 1 секунды (для 95% запросов).
Параметры тестирования
Выделенное оборудование
Оборудование включало в себя физические серверы двух конфигураций:
|
Был развернут кластер, включающий 2 сервера баз данных и 3 сервера приложений (веб-серверы). Данная конфигурация была выбрана для обеспечения высокой производительности кластера с одновременным обеспечением высокой отказоустойчивости. Схема кластера и его описание приведены в детальном отчете.
)
Программное обеспечение
Программное обеспечение серверов было сконфигурировано с помощью продукта "1С-Битрикс: Виртуальная машина". Кластерное решение реализовано на основе технологии Веб-кластер.
Параметры тестового интранет-портала:
- Типовое коробочное решение 1С-Битрикс24: Enterprise, версия 20.x.x с последними обновлениями, задействован модуль «Веб-кластер» для построения кластерного решения
- Демонстрационный контент на момент старта финального теста: 590 тыс. сообщений в живой ленте, 540 тыс. комментариев, 40 тыс. новостей, 180 тыс. задач, 415 тыс. мгновенных сообщений
- Количество сотрудников в базе данных портала на момент старта финального теста: 111 304 (распределены по 67 структурным подразделениям)
Указанное количество пользователей за 1 час генерируют на тестовом портале:
- 39 новостей
- 4 614 сообщений в ленте Новостей
- 4 685 комментариев
- 440 чатов
- 3 386 мгновенных сообщений
- 2 297 заданий бизнес-процессов
- 912 задач
- 367 документов
- 92 рабочие группы и проекта
- 291 встречу в календарях
- 2 385 уведомления
За сутки (24 часа) на таком портале генерируются:
- 936 новостей
- 110 736 сообщений в ленте Новостей
- 112 440 комментариев
- 10 560 чатов
- 81 264 мгновенных сообщения
- 55 128 заданий бизнес-процессов
- 21 888 задач
- 8 808 документов
- 2 208 рабочих групп и проектов
- 6 984 встречи в календарях
- 57 240 уведомлений
Методика генерации нагрузки
Нагрузка создавалась инструментом JMeter версии 5.3.3. Данные теста записывались в [dw]InfluxDB[/dw][di]Высокопроизводительная БД, предназначенная для обработки высокой нагрузки записи и запросов.
Подробнее...[/di]. Для визуализации аналитики использовали приложение Grafana. Мониторинг серверов осуществлялся при помощи системы мониторинга Zabbix.
Для тестирования было выбрано 29 сценариев из 13 блоков, свойственных для типового интранет-портала:
- авторизация,
- живая лента,
- поиск,
- чат (групповой и один на один),
- задачи,
- календарь,
- мой диск,
- новости,
- фотогалерея,
- сотрудники,
- профиль,
- бизнес-процессы,
- рабочие группы.
Для каждого теста были подобраны веса, учитывающие работу различных пользователей на портале и долю каждого из блоков в общей нагрузке.
)
Была применена новая методика генерации нагрузки от пользователей. Вместо одного виртуального пользователя, перебирающего в случайном порядке типовые цепочки действий, нагрузка генерировалась большим количеством разных пользователей со своей учетной записью на портале. Генератор нагрузки авторизовывал каждого такого пользователя в системе, а затем выполнял под этим пользователем разнообразный набор сценариев. При этом между выполнением каждого нового сценария выполнялось ожидание (от 20 сек до 10 минут). Таким образом, эмулировалось максимально реальное поведение сотрудников предприятия, которые зашли в интранет-портал и работают с ним в течение дня.
Важно отметить, что не преследовалась цель максимизации показателей по сгенерированному контенту на портале за время теста (новостям, задачам, документам, сообщениям и другим). Важнее было обеспечить их соответствие реальной жизни. И тем не менее, скорость добавления информации на портал оказалась также очень высокой, что покрывает потребности многих заказчиков с большим запасом!
Результаты тестирования и сертификат
Демонстрационный портал, развернутый в кластерном решении из 5 серверов, обеспечил одновременную работу 30 тысяч пользователей, а это соответствует примерному профилю нагрузки для крупной корпорации, в которой работает 100 – 200 тысяч сотрудников.
При этом система обеспечила быстрый (даже по меркам интернет-проектов) отклик, для подавляющего большинства запросов не превышающий 1 сек, что, безусловно, делает работу с порталом комфортной для современного пользователя. Технология Веб-кластера вновь подтвердила свою производительность и надежность.
Ссылка на запрос подробного отчета.

Производительность
Производительность
Создать хорошее веб-приложение не сложно. Для этого достаточно обеспечить:
- согласованность данных (англ. consistency) (во всех вычислительных узлах в один момент времени данные не противоречат друг другу);
- доступность (англ. availability) (любой запрос к распределённой системе завершается корректным откликом);
- устойчивость к разделению (англ. partition tolerance) (расщепление распределённой системы на несколько изолированных секций не приводит к некорректности отклика от каждой из секций).
Однако при этом задачу высокой производительности никто с разработчиков не снимает. Создать "быстрое" приложение не сложно. Для этого достаточно:
- Формализовать требования производительности, которые высказывает клиент.
- Понять принципы создания высоконагруженных, масштабируемых приложений.
- Научиться логировать метрики.
- Научиться анализировать их (самое сложное).
- Запустить процесс с обратной связью.
- Свести анализ к маленькому набору индикаторов.
Клиентские требования по производительности
Чётко поймите, что именно для клиента означает "производительный сайт" и формализуйте эти требования. Большинство клиентов ориентируется на другие ресурсы и, как правило, говорят: "быстро как там-то". Такой ответ не должен вас удовлетворять. Требования должны быть чётко формализованы: Главная - 0,5 секунд, детальная - 0,3 секунды, "Умный фильтр" не более 1, 5 секунд.
Производительность JS в этом плане - первое, с чего надо начать. JS должен работать быстро.
Второе - картинки и стили, которые тоже должны грузиться быстро. Их лучше раздавать с разных доменов, так как браузер может качать с одного домена не более чем, как правило, в 6 потоков. Большие файлы отдавать через CDN
В итоге получается что верстальщик и JS-разработчик - это основные люди, отвечающие за производительность с точки зрения клиента.
При работе с SSL рекомендуется использовать SPDY через модуль NGNIX, ускоряющий загрузку.
Проблемы на клиентской стороне
Коллективная разработка при неумелой организации процесса также создает проблемы, по принципу: "У семи нянек дитя - без глазу". Тем более, что тестирует это все, как правило один человек, который просто не успевает сделать проверку всего и ограничивается только проверкой работы (а не скорости работы) созданного функционала.
Другая проблема - управленческая. Если руководство не понимает проблем разработки и качества разработки и его волнуют только сроки. В этом случае практически всё делается второпях, не оптимально и "на скорую руку".
Другие ошибки:
- использование несжатой графики,
- большое число файлов, грузящихся на страницу,
- не профилируются данные,
- отсутствие тестов,
- выбор неправильных алгоритмов для конкретной задачи.
Полезные рекомендации по клиентской производительности можно также почерпнуть тут.
Проблемы на серверной стороне
Создать себе реальные проблемы на серверной стороне можно с помощью:
- Непродуманной отдачи статики;
- Медленной генерацией динамического контента.
Для избежания проблем со статикой оптимальным решением будет использование CDN. Но, если в силу каких-то причин это неприемлемо, можно вынести статику на отдельный домен, что позволит скачивать её в несколько потоков. Либо перенести статику на отдельный сервер(ы) с быстрыми дисками.

На скорость генерации динамического контента в первую очередь влияет качество программирования. Сама по себе БД не тормозит. Тормозят запросы, которые задаются разработчиком.
При прогнозируемых больших объёмах данных рекомендуется познакомиться с теоремой CAP, NoSQL, изучить репликацию, изучить и использовать Galera.
Материалы по теме
- Обеспечение производительности при эксплуатации проекта
Типовые ошибки
Рассмотрим несколько типовых ошибок, которые совершают при проектировании больших проектов.
Ошибка "Вроде работает"
Частая ошибка начинающих студий.
За разработку берутся в общем профессиональные, но не знакомые с Bitrix Framework студии, в надежде освоить систему "по ходу". Слабое знание системы привело к тому, что написана часть функционала, которая, как потом оказалось, уже имеется в Bitrix Framework. Часть функционала показалась разработчикам "плохо" реализованной и её переписали "лучше чем в Битрикс". В последствии выяснилось, что переписанный функционал завязан на другие опции в системе. Кроме того функционал был переписан с модификацией ядра, прямыми обращениями к БД и другими стратегическими ошибками.
Результат: клиент не может управлять сайтом через стандартную админку, управление осуществляется через код, модифицированное ядро при обновлении затёрто, сайт "сломался". Уходит много времени на исправление, клиент "рвёт и мечет".
Ошибка "Информационный сайт. Много данных в каталогах"
Ошибка в постановке задачи. На этапе ТЗ не отмечен факт большого числа инфоблоков и данных в них. В результате при разработке реализована неоптимальная работа с инфоблоками через АПИ. При этом, не подумав, выбрали виртуальных хостинг.
Как следствие, после загрузки данных все стало тормозить. Попытались везде внедрить кэширование – время генерации кэша > 30 секунд. Сроки - сорваны.
Ошибка "Зачем делать просто, если можно сложно? Или горе от ума."
Одна из "ошибок роста" для веб-студии. После нескольких удачных проектов возникает ощущение, что "мы можем всё". В результате решили сделать значительно "сложнее", чем нужно по ТЗ. При этом Использовали свои таблицы в БД, а после запуска обнаружили многочисленные уязвимости типа SQL Injection.
В последствии пришел новый программист и не смог распутать решение - начал переписывать. Развивать проект получается дорого.
Ошибка "Не проектировали"
Ошибка самоуверенности. Возникает после продолжительной и успешной работы студии, когда научились обходить все вышеописанные ошибки.
Сложная предметная область при дефиците времени. Экономим на проектировании, надеясь на свой профессионализм. После 50% времени реализации, оказалось что нельзя добавить новое требование. Дальше возникают новые требования и новые проблемы. Проект переписывали раза 3, "Костыль на костыле" - сложно и дорого развивать.
Ошибка "Гипер-формализация"
Обжегшись на предыдущей ошибке некоторые веб-студии начинают перестраховываться.
Опять сложная предметная область, проектировали 3 недели. Получили: 10 диаграмм, 50 Use Cases, прототипы и так далее. Требования «немного» изменились и необходимо менять проекты. На внесение изменений в артефакты проектирования ушло 2 недели. Сроки летят.
Ошибка в работе с заказчиком: "Заказчик сам не знает чего хочет"
Будучи уже опытными разработчиками, отлично знающими систему и успешно научившись обходить ошибки, связанные с собственным ростом, когда-то всё равно встретятся с такими клиентами.
Как правило это клиент из специфической предметной области. Заказчик в ней слабо разбирается, экспертов нет. Времени на проектирование выделили мало. В результате приходится многократно переписывать части проекта и, как следствие взаимные претензии к клиенту и от клиента.
Ошибка "Запутались"
В больших проектах существует риск управленческих ошибок.
Объемное ТЗ - большая нагрузка на менеджера проекта. Он начал терять требования и запутываться, что порождает взаимные претензии с Заказчиком. Разработчики вынуждены переписывать части веб-системы, в результате получился – "костыль на костыле". Проект дорого и сложно развивать
Эксплуатация проекта
Эксплуатация проекта - это, как и разработка, процесс, который нужно организовывать. Но, в отличие от разработки, здесь встают совсем другие задачи и проблемы, поэтому нужны совсем другие бизнес-процессы. Соответственно, это требует создания иной команды, привлечения иных специалистов.
Кто будет заниматься эксплуатацией?
Варианта решения этого вопроса два: студия или сам клиент.
Мелкие клиенты с проектами, не требующими доработки, обычно уходят самостоятельно на какой-либо хостинг и доверяются его администраторам.
Вариант передачи проекта на эксплуатацию клиенту кажется предпочтительным для средних и крупных проектов. Действительно, в крупных компаниях работают, как правило, сильные системные администраторы, и кажется логичным довериться им. Но использование системных администраторов клиентов имеет свои сложности. Высококвалифицированный администратор может не знать не только Bitrix Framework, но и вообще не знать, что такое php-разработка и стек LAMP-технологий. Они могут не знать, как создать, настроить и сопровождать систему мониторинга и анализа. Это рождает свои проблемы: будут говорить, что студия написала "говнокод", мол надо переделать. Эти риски есть, и их надо учитывать.
Если проект находится на постоянной доработке студией, то возникает ещё одна проблема при эксплуатации проекта клиентом: внесение обновлений по собственно проекту, обновления Bitrix Framework и обновления серверного программного обеспечения. Необходимо выстраивать процесс выкладки изменений на сервере с тестового на боевой, процесс обновления ПО. Соответственно, встают проблемы взаимодействия с IT-службой клиента.
Если проект будет эксплуатироваться силами самой студии, то возникает другой спектр задач.
Большинство веб-студий не обладает, как правило, штатом квалифицированных системных администраторов. Имеющиеся администраторы знают понятие "хостинг", могут с правами root'а выгрузить проект на хостинг с настройками по умолчанию. На маленьких проектах это работает. Но на средних и больших проектах нужна профессиональная эксплуатация проекта: нужно разбираться в "железе", в Unix'ах. Крайне мало людей, которые могут одинаково хорошо писать код и разбираться в железе и ОС Unix.
В этом плане есть смысл максимально перенести низкоуровневое администрирование на хостера или облачного провайдера. Самое простое решение этой задачи: уйти в облако. Большая часть задач, которые нужно решать при эксплуатации проекта, уже решена облачным провайдером. Нет проблем с мониторингом сервера, нет работ по обслуживанию сервера (менять диски, мониторить температуру сервера и так далее). В дополнение предоставляются возможности, позволяющие полностью сосредоточиться на выполнении бизнес-задач: лёгкое выполнение бекапов, легко создавать репликацию, можно легко переносить машины и запускать проект на любых мощностях. В этих условиях качество услуг студии возрастает, сроки выпуска легче соблюдать и нет необходимости заниматься сложными настройками Linux'а.
Правда, возможны проблемы иного плана: заказчик российский и ему нужно обязательно, чтобы хостинг был российский. Да и заплатить за Amazon в России от юридического лица официально пока невозможно. Российские облачные провайдеры предоставляют не всегда действительно удобный сервис. В этом случае приходится решать задачу создания собственного облака и работать с ним через API.
И только в случае невозможности использования облачных технологий надо искать своего специалиста и влезать в дебри настроек веб-серверов, баз данных. В этом случае администратор должен быть в штате, а не приходящим.
Техническое задание на эксплуатацию
При запуске проекта необходимо понимать, какой класс проекта вы запускаете: визитка, интернет-магазин, промосайт и так далее. От этого зависят требования к сайту и его размещению. То есть должно быть сформировано не только ТЗ на разработку, но и ТЗ на запуск и эксплуатацию. Такое ТЗ будет гораздо проще, чем на разработку, и должно регламентировать:
- Количество хитов в сутки.
- Скорость загрузки главной страницы при указанном количестве хитов.
- Скорость загрузки критичных разделов.
- Среднее время загрузки всех страниц в сутки.
- Процент страниц с временем загрузки более n сек. (Исключения, которые допустимы.)
- Допустимый процент ошибок.
- Допустимое время простоя и когда и в каком масштабе оно допустимо. Например, SLA Amazon'а на его виртуальной машине - 99.85%. Что означает 13 часов простоя за год. Согласен ли Клиент на такой простой и при каких условиях? (Можно "лежать" полдня один раз за год, а можно по 2 минуты, но каждый день.)
Крайне редко заказчик может выдать такие цифры, тем более не ошибившись. Задача веб-студии – помочь ему в определении этих значений.
Надо также объяснить заказчику, зачем ему нужно определиться в этих цифрах:
- Лояльность клиентов. Если сайт часто "лежит", то клиент будет склонен к смене сервиса. Замедление загрузки страницы на 1 секунду снижает конверсию на 7%, а количество просмотров - на 11%.

- Если сайт часто "лежит", то поисковик, несколько раз наткнувшийся на неоткрывающиеся страницы, может просто исключить сайт из рейтинга, то есть на него не придут потенциальные клиенты с поисковых машин.
- В случае сбоя сайта при проведении рекламной кампании, на него не попадут те клиенты, которые кликали по баннерам, то есть вы заплатили за пустые клики.
- Все поисковые системы в рейтинговании учитывают как поведенческие, так и технические моменты: при прочих равных условиях поисковик ранжирует медленно грузящийся сайт ниже, чем быстро работающий.
Отдельно нужно обговорить условия проведения технических работ на сайте. Технические работы должны проходить незаметно для клиентов:
- Сервисные работы;
- Замена оборудования;
- Обновления системного ПО;
- Обновления приложений.
Если проект критичен для бизнеса, если он должен быть доступен всё время, то это значит, что он должен быть доступен всегда, даже если вы сами планируете какие-то работы на нём. Как минимум, это должны быть сообщения о проведении работ с точным указанием сроков выполнения этих работ и обязательным соблюдением этих сроков.
Основные задачи в процессе эксплуатации
- Обеспечение производительности
- Обеспечение отказоустойчивости
- Обеспечение безопасности
Большая часть задач решается за счёт постоянного мониторинга.
Дополнительно
|
Где размещать проект
Где размещать проект
Студия должна понимать сама и суметь объяснить клиентам какой вид размещения необходим конкретному проекту и почему. Неспособность объяснить это клиенту понятно, чётко и аргументировано - повод для серьёзного сомнения в компетенции студии.
Вариантов размещения немного:
- Виртуальный (shared) сервер - пришёл, установил и всё работает.
- VPS - можно самому "гаечки" покрутить.
- Dedicated/Colocation - своё карман не тянет.
- Облако - что-то новое и непонятное.
Частое заблуждение: что маленький проект надо размещать на виртуальном хостинге; большой - на VPS, совсем большой - на собственном "железе". На самом деле это далеко не всегда верно. Определяющим здесь должно быть не нагрузка, а ваши требования и предпочтения.
Риски при выборе площадки для размещения
- Взять слишком много и переплатить (не можем заранее спрогнозировать потребление ресурсов).
- Взять слишком мало и «просесть» по производительности.
- Безопасность (если в штате нет толкового системного администратора).
- Надежность (как резервировать доступность на уровне датацентра?).
- Сетевая доступность.
Виртуальный (shared) хостинг
Это - всегда "общежитие", но самый простой вариант. Хороший хостинг снимает практически всю головную боль (бэкапы, резервирование и тому подобное). Но на таком хостинге сайт всегда будет ограничен по ресурсам. Любые соседи при их повышенной активности так или иначе будут влиять на сайт. Например, на таком хостинге нет инструментов, позволяющих хорошо и аккуратно ограничить дисковую активность. В результате, если какой-то пользователь начнёт активно работать с диском, то при достаточности всех остальных ресурсов, вы всё равно ощутите "тормоза" на своём сайте.
У вас минимум возможностей по кастомизации серверной части. В случае аварии у вас нет средств по восстановлению, кроме забрасывания писем в ТП.
Собственное оборудование или "облако"?
Примечание: Под "облаком" будем понимать VPS и облачный сервис в силу довольно большой идентичности. В обоих случаях вы работаете с виртуальными машинами.
Экономика. Считается, что "облачное" решение - более дешёвое, чем собственный сервер. На самом деле, при прямом сравнении аналогичных конфигураций "облачное" решение будет дороже. Более того, есть платежи, которые изначально могут быть не учтены, например, стоимость трафика, которая, как правило, считается отдельно. Есть определённая сложность расчетов при оплате "по потреблению": при резком росте нагрузки (DDoS, «хабраэффект», ошибки в разработке) возможны значительные расходы (в разы больше запланированных).
Реальная экономия использования облака кроется в других местах:
- Нет инсталляционных платежей, есть только эксплуатационные.
- Если проект "не пошёл" то потери только в тех платах, которые уже совершены, для сворачивания не нужно выполнять ни каких дополнительных действий и нести какие-то затраты. В случае собственных серверов вы теряете гораздо больше.
- Экономия на времени обслуживания системы в целом. Если надо просто поменять диск, то для этого нужно тратить довольно много времени: поездка в дата центр, собственно замена, возможное переконфигурирование сервера и так далее.
Масштабируемость. Считается, что масштабируемость в облаке намного выше, чем в случае собственного сервера. С одной стороны это так, но не надо забывать про способность к масштабированию самого приложения. Например, если приложение сконфигурировано таким образом, что БД потребляет определённый объём памяти, веб-сервер потребляет определённый объём памяти, то увеличение памяти на виртуальной машине не даст прироста производительности. Требуется переконфигурирование приложения. Это возможно не для всех приложений.
Вертикальное масштабирование - это увеличение ресурсов на одной машине (или апгрейд физического сервера). С таким масштабированием может работать большинство приложений. Максимум, что может потребоваться - поменять настройки в конфигурационном файле (выделить больше памяти, например), перезапустить и продолжить работу.
Надёжность. Считается, что "облако" надёжнее. Тем не менее, VPS перегружается гораздо чаще, чем собственный сервер. При правильной конфигурации сервер может работать годами. И грамотный дата-центр всегда страхуется по электропитанию не только через UPS, но и дизельными генераторами.
Виртуальная машина может перегружаться достаточно часто, что всегда является неприятным моментом, особенно, если это касается машины, на которой работает База данных. Более того, перезапуск такой машины может оказаться процедурой не тривиальной, особенно, если бьются файлы или теряются данные.
Облачные провайдеры подвержены всё тем же рискам, что и обычные провайдеры: природные, человеческие факторы, катаклизмы.
Само по себе облако не надёжнее, но позволяет построить более надёжную инфраструктуру, так как ресурсов машин больше и можно заранее спроектировать и зарезервировать машины или сервисы и тем себя подстраховывать на случай каких-то аварий. В "облаке" эти машины можно конфигурировать произвольным образом, включать и отключать тогда, когда это необходимо не платя за ненужные мощности. В случае собственного сервера это означало бы покупку нового сервера со всеми вытекающими отсюда затратами и рисками.
Ресурсы. Распределение ресурсов в "облаке" так же не гарантировано. В лучшем случае провайдер будет обещать 95% времени выделять обещанные ресурсы, но 100% гарантии не даст никто.
Дополнительные сервисы. "Облако" предоставляет сервисы, которые, при размещении на собственных серверах пришлось бы реализовывать самостоятельно. Например, облачные хранилища для статической информации. Такие хранилища доступны (99.99%), надежны (99.999999999%), поддерживают версионность и шифрование. Благодаря ему снижается стоимость эксплуатации, оно может использоваться совместно с CDN, снижается нагрузка на web-узлы, сайту становится легко переезжать, его легко бэкапить, производится синхронизация контента между множественными web-узлами, ускоряется рендеринг страниц в браузере.
Кроме того доступны сервисы:
- Автомасштабирование
- Мониторинг
- Балансировщики
- Облачные базы данных
- Облачные NoSQL
- Облачный кэш
Плюсы и минусы размещения в "облаке"
Несмотря на все сложности и риски "облачное" размещение выбирать можно и нужно, если учитываются все риски. Сравните плюсы и минусы размещения в "облаке".
|
Настройка
Если вы решили размещать проект на собственном сервере и самим заниматься администрированием, то вам необходимо изучить Курс для хостеров. Этот курс даст основную информацию по правильной настройке сервера и базы данных.
В этой главе опишем некоторые моменты настроек, которые не всегда ясно освещаются в документации на веб-сервер и базу данных. Данная глава – «сын ошибок трудных» наших администраторов.
Настройка веб-сервера
Настройка веб-сервера
Настройки «по умолчанию» - это далеко не всегда хорошо. На них можно начать работать, но с ними трудно обеспечить нужную производительность и надёжность. Однако неграмотное изменение настроек по умолчанию может дать обратный результат: не ускорение, а замедление работы. Типовые ошибки конфигурации:
- PHP как CGI (не путать с FastCGI). В этом случае на каждый хит запускается собственный процесс, который делает какую-то обработку, а потом гасится. Ресурсоёмкая и долгая операция, проект при такой настройке будет работать непроизводительно.
- Использование параметра open_basedir в PHP, который призван изолировать клиентов на сервере друг от друга. Этот параметр не панацея в плане безопасности, и он существенно снижает производительность.
- Не установлен прекомпилятор PHP на хостинге. Часто его нужно включать самостоятельно. Прекомпилятор интерпретирует php скрипт в байткод, обрабатывается и сохраняет в кеше. В последующем интерпретация не требуется, байткод получается из кеша. Прекомпилятор снижает нагрузку на процессор и ускоряет исполнение php скриптов.
- Недостаточно памяти прекомпилятору, в результате кеш для прекомпилированных скриптов будет работать крайне неэффективно на больших проектах.
- Медленная файловая система и/или мало дискового кэша.
- Отсутствует FrontEnd (NGINX). Подробнее смотрите в курсе для хостеров
- NGINX есть, но всю статику запрашивает у Apache.
- Не отрегулировано значение MaxClients в Apache.
Прекомпиляторы
Их надо использовать. Один из самых быстрых - Zend Optimizer+, правда он и один из самых непрозрачных. APC на 5-10% медленнее, но надёжнее, реже падает, и работать с ним проще.
Подключая прекомпилятор, обязательно смотрите, сколько памяти ему выделяется, насколько полно она используется. У всех прекомпиляторов есть сторонние или внутренние средства диагностики и мониторинга, которые рисуют диаграммы, показывают скрипты, которые попали в кеш, как эффективно используется память. Это поможет вам использовать прекомпилятор максимально эффективно.
Можно ли без Apache? PHP-FPM
Возможно использование вместо Apache модуля PHP-FPM. Этот вариант обладает с одной стороны неудобством: если у вас много логики, завязанной на файл .htaccess , то эту логику надо перенести отдельно в конфиг NGINX. Это делается один раз, но потом останутся только удобства.
Пример конфига:
location ~ \.php$ {
root /var/www/chroot/var/www/html;
fastcgi_intercept_errors on;
fastcgi_pass backend;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param DOCUMENT_ROOT /var/www/html;
fastcgi_param SCRIPT_FILENAME /var/www/html/$fastcgi_script_name;
fastcgi_param SERVER_NAME $host;
fastcgi_split_path_info ^(.+\.php)(.*)$;
fastcgi_param PATH_INFO $fastcgi_path_info;
}
Apache при каких-то ошибках не умеет сам себя рестартовать, нужны внешние обработчики. А на больших нагрузках достаточно часто могут возникать ошибки вида segmentation fault. PHP-FPM может делать рестарт внутренними средствами:
; рестартовать при ошибках emergency_restart_threshold = 1 emergency_restart_interval = 10
Первое - количество ошибок за интервал времени, после которого надо перезапустить сервер;
второе - тот самый интервал.
Можно регулировать, сколько коннектов можно держать, пока основные процессы заняты обработкой каких-то данных. Можно установить фиксированное количество процессов в системе исходя из известного нам объёма памяти и данных о том, сколько занимает в ней один процесс.
Пример конфига:
pm = static pm.max_children = 30 pm.start_servers = 30 pm.min_spare_servers = 30 pm.max_spare_servers = 30
Ведение лога медленных запросов: автоматическое включение лога медленных запросов, выполняющихся больше заданного времени с указанием адреса страницы и функции PHP, на которой началось торможение.
request_slowlog_timeout = 5 slowlog = /opt/php/var/log/www.slow_access.log
Лог медленных запросов - самый простейший инструмент увидеть проблемные места быстро. В идеале лог должен быть пустым, либо в нём должны быть запросы, о которых вам известно и которые вы допускаете быть долгими.
PHP-FPM очень хорошо подходит для ограничения прав доступа, если на одном сервере работает несколько проектов. В этом случае для каждого проекта можно выделить свой пул, выделить свой chroot. В отличие от open_basedir, он никаким образом не снижает производительность, успешно разделяя пользователей.
; не open_basedir в php.ini chroot = /var/www/chroot
Более того, можно задать разные пулы, разные конфигурации под разные сервера.
Чек-лист по настройке
Примерный чек-лист, который должен быть выполнен при настройке веб-сервера:
- Стабилизировать систему по памяти.
- Обеспечить надёжность системы при возрастающей нагрузке - обслуживается максимум запросов, остальные ожидают в очереди.
- Использовать persistent connections для базы при установленном фиксированном числе процессов.
- Использовать frontend для отдачи статики.
- Не занимать backend медленными запросами клиентов.
- Использовать сжатие - быстрее отдавать на медленных каналах.
- Разгрузить процессор за счет прекомпиляции PHP.
Настройка базы данных
Настройка базы данных
Особенности работы с Базой данных заключается в том, что всегда приходится искать компромисс между быстротой и надёжностью. Либо будет быстро, но не надёжно, либо надёжно, но медленно, либо остановиться надо на каком-то среднем варианте.
Узкие места в работе с БД: CPU, RAM, Диск, то есть всё. Если чего-то не хватает, то их надо добавлять. В "облаке" используются медленные диски, однако так же как и на обычном сервере можно использовать программный RAID, что позволяет снимать все узкие места.
На платформе Amazon'а проводился эксперимент. Использовался одиночный диск, RAID10 из 4-х дисков и из 8-и дисков. При многопоточной загрузке больших файлов тесты sysbench показали что производительность RAID гораздо выше чем одиночного диска. На иллюстрации показана работа с одиночным файлом 16 Гб в режиме random read/write. При увеличении количества потоков единичный диск почти сразу достигает «потолка», производительность RAID растет.

Диагностировать проблемы можно стандартными инструментами: команды top (загрузка процессора и памяти), free (свободная память) и iostat –x 2 (что происходит с дисками, как они утилизированы, есть ли очередь из запросов и какое время обработки запросов).

Если памяти достаточно, то для временных таблиц MySQL лучше использовать именно память, создавая tmpfs, а для хранилища всех данных использовать RAID.
Использовать ли стандартный MySQL?
Можно использовать различные подсистемы хранения данных в СУБД MySQL, например Percona Server, который:
- Оптимизирован для работы с медленными дисками.
- Допускает быстрый рестарт базы (
Fast Shut-Down,Buffer Pool Pre-Load). - Обладает богатым инструментарием внутренней диагностики (счетчики и расширенные отчеты).
- Использует XtraDB Storage Engine, лучше чем InnoDB и при этом совместим с ним.
- Использует XtraBackup, который используется для быстрого бинарного бекапа.
Другие подсистемы (MariaDB и другие) имеют свои преимущества. Выбирайте подходящую вам (или более знакомую вам) подсистему.
Сбалансированность БД, так же как и в случае с веб-сервом, должна быть максимальной. Оставить параметры по умолчанию - одна из частых ошибок. Другая ошибка - выбор значений параметров "на глазок", когда администратор не достаточно квалифицирован.
MySQL использует глобальные буферы и буферы для одного коннекта:
- Размер глобальных буферов: key_buffer_size + tmp_table_size + innodb_buffer_pool_size + innodb_additional_mem_pool_size + innodb_log_buffer_size + query_cache_size.
- Размер буфера для одного коннекта: read_buffer_size + read_rnd_buffer_size + sort_buffer_size + thread_stack + join_buffer_size.
Максимально возможное использование памяти: глобальные буферы + буферы подключений * максимальное число коннектов. Для подсчёта вручную можно взять нужные цифры из конфигов MySQL, либо воспользоваться утилитой mysqltuner.
Основная ошибка при настройке: конфигурация настроена на потребление памяти больше, чем есть в распоряжении виртуальной машины (сервера). Это означает, что при возросшей нагрузке, когда вырастет число соединений, запросы от БД будут просто "убиты" операционной системой по превышению. Именно поэтому значения нужно подбирать исходя из ваших потребностей и возможностей виртуальной машины (сервера).
InnoDB или MyISAM ?
На малых и средних невысоконагруженных проектах над выбором типа можно не задумываться. MyISAM достаточно быстрая, в ряде случаев быстрее чем InnoDB, при этом работать с ней проще. Но если проект нагружен, большой или требователен к надёжности, то нужно использовать InnoDB:
- При update и insert не будут происходить блокировка всех таблиц, а только тех записей, с которыми идёт работа в данный момент.
- В InnoDB гораздо больше инструментов для безопасности, надёжности и сохранения данных, транзакций.
- При должной настройке работает быстрее.
Как хранить базы и таблицы в InnoDB
Как хранить базы и таблицы: в одном едином файле ib_data или в разных файлах. По умолчанию всё храниться в едином файле. Если проект такой, что объём данных у него постоянно меняется (таблички создаются/удаляются, базы создаются/удаляются), то эти операции при хранении в одном файле выполняться будут быстро, но при этом команда DROP DATABASE не будет реально освобождать место. В итоге база дорастает до лимитов диска и нужно заново делать импорт/экспорт базы, чтобы сбросить этот файл, либо увеличивать диск, либо куда-то переносить данные.
Если все таблички хранятся в разных файлах (параметр innodb_file_per_table равен 1), то работать с ними, с точки зрения администрирования проще, DROP DATABASE реально удаляет данные, но в MySQL, к сожалению, это дорогая и тяжелая операция в силу ряда внутренних причин. Узким местом в этом случае станет процессор.
Поэтому надо оценить часто ли на проекте будут создаваться/удаляться базы данных, делаться реорганизация таблиц, выполнение ALTER TABLE и других подобных вещей, если нет, то смело используйте единый файл.
Скорость работы БД
Временные таблички хранить в памяти, а размер временных таблиц, если память позволяет лучше делать больше. До этого лимита временные таблицы не будут создаваться на диске, а будут в памяти.
# временные таблицы – в памяти tmpdir = /dev/shm # размер временных таблиц в памяти max-heap-table-size = 64M tmp-table-size = 64M
Используйте параметр skip-name-resolve, который позволяет отправлять чуть меньше DNS запросов.
Многие, видя, что в Bitrix Framework join'ов много, увеличивают параметр join-buffer-size, считая что он будет эффективно использоваться. Увеличение этого параметр не всегда полезно, так как это количество памяти, которые сразу же будет выделяться на запрос, не смотря на то, используются ли в нём индексы. Соответственно, увеличивая этот буфер можно просто съесть всю память в системе без какого либо увеличения эффективности.
Аналогично с параметром query-cache-size. Полезный инструмент, когда выполняется один и тот же запрос на не изменяющемся наборе данных, то результат выполнения попадает в кеш и очень быстро отдаётся из кеша при аналогичном запросе. При превышении кешем размера более чем, по эмпирическим данным, 500 мегабайт, этот кеш работает только хуже. Так как в этом случае возникают уже внутренние блокировки в самом MySQL. Это покажет SHOW PROCESS LIST, который выведет список запросов в состоянии waiting for query cache log.
При грамотно настроенном сервере и грамотно спроектированном приложении query-cache-size можно не использовать, либо использовать с небольшими значениями: 64 или 128 Мб. Если данных столько, что они вытесняют всю память из query cache, то есть смысл перемотреть логику приложения и структуры данных уже в самих таблицах.
Основная сущность в InnoDB - это buffer pool, где хранятся все структуры данных с которыми мы работаем. Всегда нужно стараться установить такое значение параметра, чтобы все данные с которыми мы работаем (или хотя бы "горячие данные") помещались в buffer pool. При этом не забывать про сбалансированность по памяти, не допускать того, что бы произошёл уход в swap.
Если buffer pool получается у нас достаточно большим, то эффективнее с точки зрения производительности использовать такой параметр как innodb_buffer_pool_instances. Это запуск нескольких buffer pool'а в MySQL. В этом случае БД работает с ними эффективнее процентов на 5-10%.
# желательно – по объему таблиц innodb-buffer-pool-size = 4000M # если buffer pool > 1Gb innodb_buffer_pool_instances = 4 innodb_log_file_size = 512M innodb_log_buffer_size = 32M # на быстрых дисках; можно экспериментировать innodb_read_io_threads = 16 innodb_write_io_threads = 16 innodb_io_capacity = 800
Основные параметры, на которые надо обращать внимание при работе с базой. Нужно уметь пользоваться командой SHOW ENGINE INNODB STATUS. Это позволяет видеть, что у нас происходит с InnoDB и buffer pool, обращая особое внимание на секцию BUFFER POOL AND MEMORY, где Buffer pool hit rate должен стремиться к 1, то есть все запросы должны обрабатываться из buffer pool, а не браться с диска.
Так же значение имеет секция TRANSACTIONS, где отображаются транзакции, которые выполняются долго, или висят, или откатываются, всё это показывает что с ними что-то не так.
Нужно уметь пользоваться командой SHOW STATUS \G, которая показывает что происходит с query cache, с временными таблицами.
Нужно уметь пользоваться командой SHOW PROCESSLIST, которая показывает текущие запросы.
Нужно включать логирование медленных запросов, что бы не думать и не гадать что у нас происходит в системе, какая страница тормозит и на чём именно она тормозит. Его легко найти (команда slow.log) и легко изучать (EXPLAIN). Однако из EXPLAIN'а не всегда понятно что же медленного происходит в базе.
Профилирование в БД
Если долгих запросов нет, но всё равно не понятно как работает БД: быстро, не быстро. Тут прежде всего надо определить критерии оценки.
После нахождения медленного запроса включается mysql> SET PROFILING=1;, выполняется запрос. Сохраняете профиль этого запроса и вы смотрите таймингами, что у вас в этом запросе происходило и что тормозило: передача по сети, оптимизация, проблемы на уровне SQL.
mysql> SHOW PROFILES; +----------+------------+---------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------+ | 1 | 0.09104400 | SELECT COUNT(*) FROM mysql.user | +----------+------------+---------------------------------+ 1 row in set (0.00 sec)
В тестовом запросе самым долгим было Opening tables, дольше всего открывали таблицу с диска.
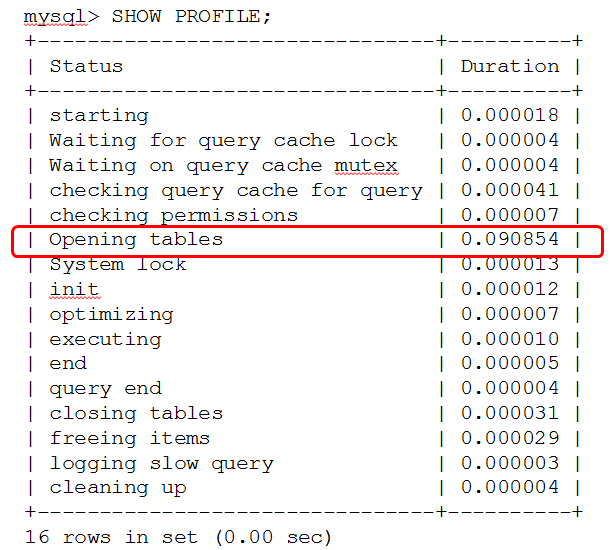
Профилирование - очень полезный инструмент, позволяющий понять что в базе может тормозить.
Если с базой всё хорошо (долгих одиночных запросов нет), то можно использовать mysql> SELECT * FROM INFORMATION_SCHEMA.QUERY_RESPONSE_TIME; (в стандартном MySQL такого нет, есть в расширениях, например в Percona Server). Это гистограмма времени запросов, которые выполняются с шагом в 1 порядок начиная с 0.000001 сек. Определите для себя критерии оценки. Например: соотношение быстрых и медленных запросов. Надо при этом определить что такое "быстрый" и что такое "медленный" запрос. Пусть быстрый будет тот, что выполняется быстрее, чем 0,01 секунды, а медленный - всё остальное. Если это соотношение - 2-3 %, то система функционирует нормально.
На больших проектах, где идёт большая работа с базой, где много обращений, такой инструмент очень удобен и показателен:
mysql> SELECT * FROM INFORMATION_SCHEMA.QUERY_RESPONSE_TIME; +----------------+-------+----------------+ | time | count | total | +----------------+-------+----------------+ | 0.000001 | 0 | 0.000000 | | 0.000010 | 2011 | 0.007438 | | 0.000100 | 12706 | 0.513395 | | 0.001000 | 4624 | 1.636106 | | 0.010000 | 2994 | 12.395174 | | 0.100000 | 200 | 6.225339 | | 1.000000 | 33 | 5.480764 | | 10.000000 | 1 | 2.374067 | | 100.000000 | 0 | 0.000000 | | 1000.000000 | 0 | 0.000000 | | 10000.000000 | 0 | 0.000000 | | 100000.000000 | 0 | 0.000000 | | 1000000.000000 | 0 | 0.000000 | | TOO LONG | 0 | TOO LONG | +----------------+-------+----------------+ 14 rows in set (0.00 sec)
Как жить с большим количеством баз и таблиц?
Если позволяет логика приложения можно разделить одну установку mysqld на несколько и разнести данные по ним. Этот способ имеет смысл только при достаточном количестве ресурсов на физическом сервере (многоядерные системы, гигабайты RAM). Несколько установок лучше используют ресурсы, это проверено тестами.
Два теста с помощью sysbench: первым тестом грузим в 100 потоков одну установку; вторым тестом грузим параллельно 50 потоков на один инстанс, 50 потоков на второй. Во втором тесте в среднем получаем на 15% больше запросов в секунду.
Минус такого метода - некоторая сложность администрирования.
Описанное разделение не всегда можно использовать. Оно возможно, если на одном сервере работает несколько проектов и возможно логическое разделение по разным базам.
Несколько полезных советов по настройке
Один из полезных параметров - sync_binlog (особенно, если используется репликация). Это запись всех изменений базы, записанные в бинарный лог. Если важно, что бы репликация была надёжной и в случае падения какой-то машины у нас никакие данные не потерялись, то этот параметр должен быть выставлен в 1 (то есть запись ведётся постоянно). В обычном окружении такой значение кардинально снизит производительность базы. Но если sync_binlog вынести на отдельный диск, то его можно смело включать, производительность базы падать не будет.
# самый надежный sync_binlog = 1 # hint: писать на отдельный раздел log-bin = /mnt/binlogs/mysql/mysqld-bin
Формат binlog-format чаще используется mixed. MIXED фактически является псевдоформатом. Этот формат по умолчанию работает как STATEMENT. Но если в SQL запросе встречается функция, которая корректно логгируется только в ROW, то формат временно (в это запросе) переводится в него и после выполнения возвращается назад. Такое решение позволяет использовать преимущества одновременно обоих форматов STATEMENT и ROW.
binlog-format = mixed
Сброс логов buffer_pool'а - innodb-flush-log-at-trx-commit можно выставить в значении 2. В этом случае логи будут сбрасываться достаточно часто, но не на каждый коммит.
# сбрасываем log buffer на каждый commit, flush на диск – # раз в секунду innodb-flush-log-at-trx-commit = 2
Параметры sync_master_info, sync_relay_log и sync_relay_log_info существенно влияют на производительность. Для надёжности их надо выставлять в значении 1, но производительность упадёт. Можно установить значение 0, но надо иметь в этом случае опыт восстановления данных, возможности диагностики проблем другими средствами и всё равно понимать, что вы идёте на определённый риск.
Параметр max-connect-errors влияет на надёжность косвенным образом. По умолчанию у него стоит не высокое значение (10). Это параметр означает, что если с определённого хоста пришло 10 коннектов с ошибками, то этот хост блокируется до перезагрузки базы, либо ручного выполнения команды flush-hosts. Другим и словами, если возникла какая-то сетевая проблема между веб-сервером и базой (проблема частичная, например, коннект проходит, но не проходит авторизация, пакеты или ещё что-то), то после 10 попыток обратиться к базе хост блокируется. То есть проект перестаёт работать. Если на проекте нет мониторинга, то возникшая ночью такая проблема до утра сделает сайт неработающим.
Это глупая и мелкая ошибка и можно смело ставить это значение больше, которое позволит обойти такие мелкие сетевые проблемы, и проект будет работать.
Резюме по работе с БД
На производительность БД влияют:
- Все внутренние ресурсы системы, их нехватка, либо достаточность.
- Блокировки (таблицы, строки), если выполняются INSERT и UPDATE при работе с MyISAM
- Прочие блокировки ("waiting for query cache lock")
Мониторинг "узких" мест:
- Внешними инструментами мониторинг системы (nagios - в реальном времени, munin - аналитика).
- Смотрим логи медленных запросов: slow.log.
- Используем SHOW PROCESSLIST, SHOW STATUS, SHOW ENGINE INNODB STATUS.
Рекомендации:
- Используем InnoDB, а не MyISAM.
- Для дисков - лучше RAID
- Нужно больше памяти (в идеале вся база должна помещаться в buffer pool), но не в ущерб системе в целом (нельзя допускать ухода в swap)
- Использовать репликации (чтение - со slave’ов, запись - на master’е)
Нагрузочное тестирование
Необходимость тестирования
Есть такой миф из XP/TDD, что можно полностью покрыть веб-приложение модульными и функциональными тестами, написать большое количество Selenium-тестов, кликающих по системе снаружи и без страха вносить в систему доработки и выкладывать на рабочий сервер через процесс непрерывной интеграции.
Вот несколько причин ошибочности данного суждения:
- Требования к веб-проекту будут постоянно меняться, до самого запуска. Теоретически, можно их зафиксировать, конечно, но перед запуском часто происходит такое, что нужно что-то в проекте срочно изменить.
- Если все покрывать тестами по совести, не хватит программистов и времени. Нередко встречаются отклонения от тестов, например написание mock-объектов к API Amazon.
- Если на веб-проекте часто меняется верстка будет очень сложно поддерживать Selenium-тесты в актуальном состоянии.
- Некоторые вещи, например устойчивость сайта под нагрузкой, непросто протестировать. Нужно придумать схему нагрузки, похожую на реальную, но она будет все равно другой.
- Разработчик интуитивно доверяет языку программирования, а он может содержать ошибки, которые могут появиться совершенно внезапно. Не будем же мы поэтому покрывать тестами PHP?
- и т.п.
Тем не менее, тесты нужны. Для ключевых вещей, для системных модулей тесты нужно писать и поддерживать в актуальном состоянии. Для остальных задач можно написать тест-планы и тестировать с помощью тестировщиков все страницы веб-решения перед каждым обновлением, тщательно наблюдая за появлением ошибок в логах и получая обратную связь от пользователей.
Таким образом, для поддержания работоспособности проекта в сети, необходимо использовать и unit-тесты, и функциональные тесты, и Selenium-тесты, и вариант процесса постоянной интеграции с системой контроля версий и труд тестировщиков. При этом вы понимаете, что ошибки обязательно будут просачиваться на боевые сервера и их нужно научиться быстро находить и устранять.
Нагрузочное тестирование
Нагрузочное тестирование - обязательный этап сдачи проекта, оно является важнейшей процедурой подготовки крупного проекта к открытию, а также позволяет определить предел работоспособности созданного проекта именно на выбранном оборудовании.
Зачастую, простые корректировки конфигурации могут ускорить проект в 5-10 раз и сделать его устойчивым к стрессовым нагрузкам, поэтому:
- Проводите нагрузочное тестирование на реальных данных с «боевых серверов»;
- Используйте монитор производительности;
- Эмулируйте действия пользователей на проекте;
- Эмулируйте импорты/экспорты/веб-сервисы.
Подходящими инструментами для нагрузочного тестирования являются:
В данной главе содержится информация, как на боевых серверах во время нагрузки эффективно отлавливать узкие места в производительности больших веб-приложений на PHP, а также искать и устранять «нестандартные» ошибки». Эта информация пригодится системным администраторам и разработчикам, обслуживающим сложные веб-проекты, а также менеджерам, которые хотят выстроить эффективный и быстрый процесс поиска и устранения узких мест и ошибок проектов на PHP.
Обзор инструментов нагрузочного тестирования
Зачем нужно тестирование
Нагрузочное тестирование – определение или сбор показателей производительности и времени отклика программно-технической системы или устройства в ответ на внешний запрос с целью установления соответствия требованиям, предъявляемым к данной системе (устройству). (Википедия)
Зачем производится нагрузочное тестирование:
- Проверка и оптимизация конфигурации оборудования, виртуальных машин, серверного программного обеспечения;
- Оценка максимальной производительности, которую способен выдерживать проект с типовыми сценариями нагрузки на доступных ресурсах;
- Влияние модулей проекта на производительность, сценарии обработки пиковой нагрузки;
- Оценка стабильности при максимальных нагрузках при проведении 24-часовых тестов с учетом внешних факторов (импорты, резервное копирование и т.п.);
- Выявление ограничений конфигурации, определение методов дальнейшего масштабирования и оптимизации.
Вообще, существует огромное количество инструментов для нагрузочного тестирования, как opensource, так и коммерческих. Остановимся на наиболее часто используемых и расскажем об их основных возможностях.
Apache HTTP server benchmarking tool
Бесплатный
Официальный сайтСамый часто используемый, т.к входит в состав Apache.
ab [options] [http[s]://]hostname[:port]/path
где основные необходимые options:
-c concurrency - количество одновременных запросов к серверу (по умолчанию 1); -n requests - общее количество запросов (по умолчанию 1).
В результате команды получаем такой отчет:
Concurrency Level: 10
Time taken for tests: 0.984 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 3725507 bytes
HTML transferred: 3664100 bytes
Requests per second: 101.60 [#/sec] (mean)
Time per request: 98.424 [ms] (mean)
Time per request: 9.842 [ms] (mean, across all concurrent requests)
Transfer rate: 3696.43 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 1 2 3.6 1 23
Processing: 63 94 21.5 90 173
Waiting: 57 89 21.6 84 166
Total: 64 96 21.5 92 174
Плюсы:
- Есть везде, где есть Apache;
- Не требует никакой дополнительной настройки;
- Очень простой инструмент.
Минусы:
- Очень простой инструмент;
- Тестирует только производительность веб-сервера: опрашивает только один URL, не поддерживает сценарии нагрузки, невозможно имитировать пользовательскую нагрузку и оценить работоспособность проекта со всех сторон - как с точки зрения инфраструктуры, так и с точки зрения разработки.
Joe Dog Siege
Бесплатный
Официальный сайт.Немного сложнее ab и необходимые задачи выполняет гораздо лучше.
В файле-сценарии задаются URL-ы и запросы тестирования. Если сценарий большой по объему, то можно вынести все запросы в отдельный файл и в команде указать этот файл при тестировании:
# cat urls.txt # URLS file for siege # -- http://www.bitrix24.ru/ http://www.bitrix24.ru/support/forum/forum1/topic3469/?PAGEN_1=2 http://www.bitrix24.ru/register/reg.php POST domain=test&login=login http://www.bitrix24.ru/search/ POST < /home/www/siege_post_data # siege -f urls.txt -c 10 -r 10 -d 3
В команде указывается количество пользователей -с, количество повторений -r и задержку между хитами -d.
Результат можно выводить в log-файл или сразу в консоль в режиме реального времени:
HTTP/1.1 200 0.44 secs: 12090 bytes ==> GET / HTTP/1.1 200 0.85 secs: 29316 bytes ==> GET /support/forum/forum1/ HTTP/1.1 200 0.85 secs: 29635 bytes ==> GET /support/forum/forum1/ HTTP/1.1 200 0.34 secs: 12087 bytes ==> GET / [...] done. Transactions: 100 hits Availability: 100.00 % Elapsed time: 12.66 secs Data transferred: 1.99 MB Response time: 0.64 secs Transaction rate: 7.90 trans/sec Throughput: 0.16 MB/sec Concurrency: 5.02 Successful transactions: 100 Failed transactions: 0 Longest transaction: 1.06 Shortest transaction: 0.31
Также можно взять из access-log веб-сервера URL-ы, по которым ходили реальные пользователи и эмулировать нагрузку реальных пользователей.
Плюсы:
- Многопоточный;
- Можно задавать как количество запросов, так и продолжительность (время) тестирования - т.е можно эмулировать пользовательскую нагрузку;
- Поддерживает простейшие сценарии
Минусы:
- Ресурсоемкий;
- Мало статистических данных и не очень хорошо эмулирует такие пользовательские сценарии, как ограничение скорости запросов пользователя;
- Не подходит для серьезного и масштабного тестирования в сотни и тысячи потоков, т.к он сам по себе ресурсоемкий, а на большом количестве запросов и потоков очень сильно нагружает систему.
Apache JMeter
Бесплатный
Официальный сайтОсновные возможности:
- Написан на Java;
- HTTP, HTTPS, SOAP, Database via JDBC, LDAP, SMTP(S), POP3(S), IMAP(S);
- Консоль и GUI;
- Распределенное тестирование;
- План тестирования – XML-файл;
- Может обрабатывать лог веб-сервера как план тестирования;
- Визуализация результатов в GUI.
Результаты выводятся в графическом виде:
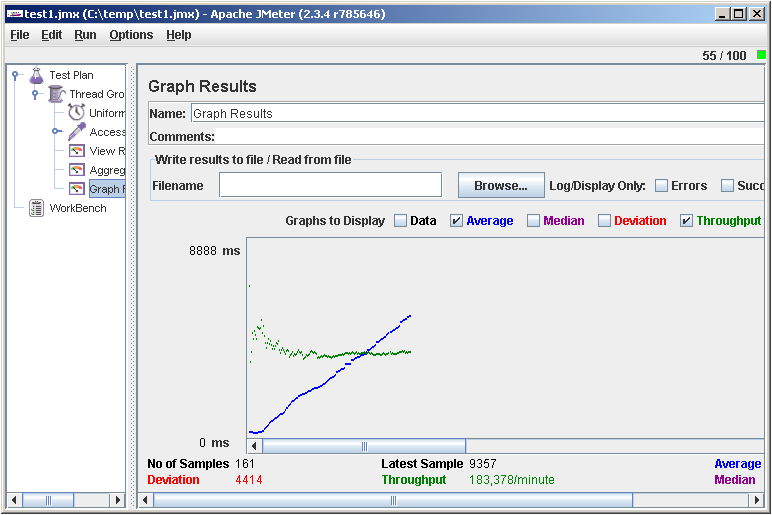
Плюсы:
- Кроссплатформенный, т.к написан на Java;
- Очень гибкий, используется много протоколов, не только веб-сервер, но и базы;
- Управляется через консоль и gui интерфейс;
- Использование напрямую логов веб-сервера Apache и Nginx в качестве сценария c возможностью варьирования нагрузки по этим профилям;
- Достаточно удобный и мощный инструмент.
Минусы:
- Ресурсоемкий;
- На длительных и тяжелых тестах часто падает по разным причинам;
- Стабильная работа зависит от окружения и конфигурации сервера.
Tsung
Бесплатный
Официальный сайтОсновные возможности:
- Написан на Erlang;
- HTTP, WebDAV, SOAP, PostgreSQL, MySQL, LDAP, Jabber/XMPP;
- Консоль (GUI через сторонний плагин);
- Распределенное тестирование (миллионы пользователей);
- Фазы тестирования;
- План тестирования – XML;
- Запись плана с помощью Tsung recorder’а;
- Мониторинг тестируемых серверов (Erlang, munin, SNMP);
- Инструменты для генерации статистики и графиков из логов работы.
С помощью собственных скриптов, которые обрабатывают логи работы, можно выводить различные отчеты по тестированию:
- tsung_stats.pl
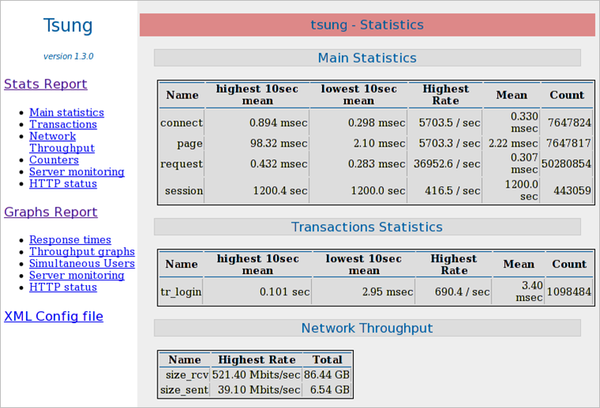
- tsung_stats.pl + Gnuplot:
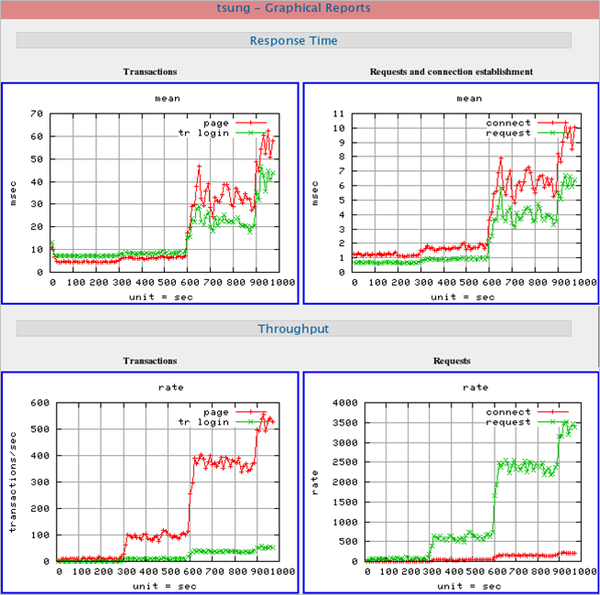
Плюсы:
- Т.к на писан на Erlang, то хорошо масштабируется, зависит от выделяемых ресурсов;
- Может выполнять роль распределенной системы, на большом количестве машин;
- Большое количество тестируемых систем - не только веб-серверы и БД, но и, к примеру, XMPP-сервер: может отправлять сообщения, тесты с авторизацией;
- Управление через консоль, но, благодаря поддержке плагинов, можно управлять и с помощью стороннего плагина с gui-интерфейсом;
- Наличие в комплекте инструмента Tsung Recorder - своего рода, proxy-сервер, через который можно ходить по тестируемому сайту и записывать сразу как профиль нагрузки;
- Генерация различных графиков тестирования с помощью скриптов.
Минусы:
- Нет gui-интерфейса;
- Только *nix системы.
WAPT
Платный
Официальный сайтОсновные возможности:
- Windows
- Платный (есть триал на 30 дней / 20 виртуальных пользователей);
- Запись плана тестирования из десктопных и мобильных браузеров;
- Зависимости в планах тестирования (последующий URL в зависимости от ответа сервера);
- Имитации реальных пользователей (задержки между соединениями, ограничение скорости соединений).
Отчет можно вывести как таблицей, так и графиком:

Плюсы:
- Очень гибкий, большое количество настроек и тестов;
- Эмуляция медленных каналов соединений пользователей;
- Подключение модулей;
- Запись сценариев тестирования прямо из браузера, как с десктопного, так и с мобильного;
- Генерация различных графиков тестирования с помощью скриптов.
Минусы:
- Доступен только для Windows;
- Платный.
Инструменты тестирования в продуктах «1С-Битрикс»
Входит в лицензию продукта
Официальный сайтОсновные возможности:
- Простой и понятный функционал, доступен сразу из административного интерфейса продукта «1С-Битрикс»;
- Задается количество потоков, можно изменять количество потоков в процессе теста;
- Удобен для быстрых сценариев по проверке текущей конфигурации сервера.
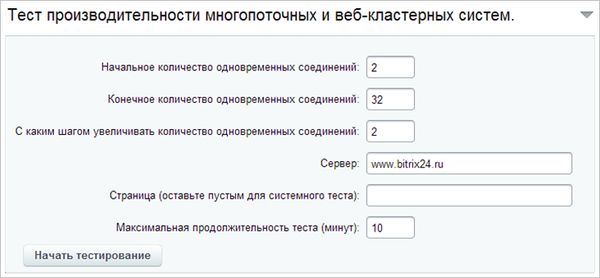
Отчет о тестировании выводится в виде таблицы и графиков:

Интерпретация результатов нагрузочного тестирования
Итак, в результате тестирования были получены логи и графики нагрузки. А дальше, используя эти логи и графики, нужно понять, где узкие места, все ли устраивает и какие существуют способы повышения эффективности работы проекта.
Частые ошибки
- Нет четкой цели, для чего нужно тестирование данного проекта.
- Нередко проводят неправильное нагрузочное тестирование и получают ошибочный вердикт по результатам тестирования.
- Получают большое количество результатов и не могут их растолковать, не знают, что с ними делать.
- Неправильное представление результатов нагрузочного тестирования клиенту.
Клиент может не знать всех терминов и инструментов тестирования. Нужно объяснить клиенту результаты тестирования понятным ему языком: «было столько-то, стало столько-то» и «хорошо стало или плохо», а также предложить ему решение проблемы, если она есть.
- DDOS тестируемой системы
- Очереди в NGNIX/PHP-FPM – не должны расти!
- Система должна "свободно дышать": с помощью команд top и iostat –xm 5 отслеживать использование дисков и CPU.
- Нагрузка только главной страницы при тестировании (а часто еще и с включенным кэшем).
В итоге пришли реальные пользователи на другие страницы сайта и … система перестала отвечать.
Поэтому при нагрузочном тестировании:
- Нужно обращаться к разным страницам веб-системы.
- Нужно загрузить демо-данные (реальный объем будущего проекта).
- Важно использовать авторизованные хиты.
- Также полезно проверять производительность загрузки статики (CSS, JS).
Здесь можно выявить различные ошибки. Например, верстальщик забыл добавить css-файл, NGINX отдает страницу с 404-й ошибкой через Apache средствами PHP (ошибка администратора). В итоге все слоты Apache заняты обработкой 404-й ошибки, попутно еще загружая сам сайт - получился типичный DDOS сайта. Решение этой проблемы - отдавать легкую статичную страницу с 404-й ошибкой сразу средствами NGINX.
Нагрузили систему, и через некоторое время она перестала отвечать. Причина – безнадежно «заDDOSили» инструментами тестирования.
Чтобы это не произошло, нужно создавать разумную, похожую на боевую нагрузку:
Подготовка
Логи
Одним из основных инструментов анализа тестирования являются логи:
- Лог jmeter – это логи основного инструмента тестирования: latency запроса, код http.
- Лог nginx – latency общее, latency к upstream.
- Лог apache/php-fpm – latency, код http, system/user time, memory.
- Лог ошибок php - в нем должно быть чисто при сдаче проекта. Если есть ошибки,то их нужно исправлять.
- Лог медленных запросов php-fpm - трейсы.
- А также пригодятся логи sar или atop, которые показывают, что происходило на сервере в конкретное время теста.
Графики
Также важная составляющая тестирования. Графики позволяют наглядно показать как вела себя система. Тестирование желательно проводить не менее суток.
Используя инструменты munin, cacti, pnp4nagios, просматриваем графики:- Apache – запросы.
- Nginx – запросы.
- MySQL – запросы, потоки.
- Процессор – user/system/iowait.
- Память – использование и распределение.
- Swap – использование.
- Диски – latency, %util.
- Сеть – tcp, трафик.
Cкрипты
Полезно написать несколько скриптов обработки логов:
- Гистограмма времени запросов - количество и время запросов.
- Гистограмма ошибок - какие ошибки и их частота.
- Гистограмма расхода памяти - скрипт и объем памяти на скрипт.
Инструментов для этого достаточно, например: awk, bash, php, а также можно воспользоваться готовыми скриптами из блога «Битрикс» на Хабрахабре или связаться с нами по e-mail: serbul@1c-bitrix.ru.
Пример скрипта обработки лога на awk:
cat /var/log/www.access.log | awk -F# '{ zone = int($10/100)*100; hits[zone]++; } \
END { for (z in hits) {printf("%8s ms: %8s,%6.2f% ",z,hits[z],hits[z]/total*100);{s="";a=0;while(a++<int(hits[z]/total*100)) s=s"*";print s} } }' \
total="$TOTAL" - | sort -n
Сценарий выполнения хита
Для правильного проведения теста и интерпретации результатов нужно знать, как работает система.
Очень важно понять, как проходит хит клиента к PHP:
- Браузер клиента делает HTTP-запрос к Nginx
- NGINX проксирует запрос к apache/php-fpm.
- PHP обращается к БД.
- PHP строит страницу и возвращает ее Nginx.
- NGINX в http-ответе возвращает ответ в браузер клиента.
Рассмотрим эти шаги подробнее:
- Браузер клиента делает HTTP-запрос к NGINX
Статика отдается, как правило, очень быстро. NGINX проксирует запрос (к upstream), ждет и возвращает статусы:
200 ОК 500 Internal Server Error 502 Bad Gateway 503 Service Unavailable 504 Gateway Timeout
Нужно понять, какие статусы ошибок и когда возвращаются:
- PHP выполнялся слишком долго (редактировать таймауты, смотреть трейс php-fpm slow log …).
- PHP остановился с fatal error - таких ошибок не должно быть!
Если программист ошибся в коде - это обычно находится легко. Но бывают ошибки, возникающие из-за превышения потребления памяти скриптом (memory-limit) - желательно не превышать потребление памяти больше 512Мб. Такие системные скрипты могут не только сами завершаться, но и вытеснять, например, MySQL или Apache в swap, а если сервисы начнут уходить в swap, то происходит общая деградация системы и уменьшение производительности в целом.
- NGINX не смог «достучаться» до apache/php.
Для отслеживания используются инструменты - Apache mod_status, php-fpm pm.status_path, ps/top.
- NGINX проксирует запрос к Apache/php-fpm
Apache не может принять запрос от NGINX, он занят запросами в БД, запрос уходит в swap.
Инструменты для отслеживания занятых очередей: apache mod_status, netstat, atop/sar.
Основной причиной часто являются задержки в БД или в коде разработчик обращается на внешний сокет, который недоступен, и из-за этого скапливаются очереди между NGINX и Apache/php-fpm. Одним из решений может являться установка таймаута на работу с сокетом.
- PHP обращается к БД
Способы отлавливания ошибок обращения с БД:
- Логгируем ошибки в БД:
define("ERROR_EMAIL", "admin@site.ru, support@site.ru"); - Лог и график медленных запросов к БД – анализируем, он не должен сильно расти.
- График числа потоков в БД – смотрим максимум на графике.
- Трафик к БД – график, большой трафик нельзя допускать, это, скорее всего, ошибка разработки.
- Логгируем ошибки в БД:
- PHP строит страницу и возвращает ее Nginx
На этом этапе идет уже чистая отладка PHP:
- Смотрим ошибки в логе PHP.
- Желательно использовать php-fpm, т.к в нем есть лог медленных запросов php-fpm, по которому видно, почему тормозит PHP.
Альтернативный логу медленных запросов php-fpm инструмент - Pinba, который рисует графики выполнения страницы или ее частей php.
- NGINX в http-ответе возвращает ответ в браузер клиента
На данном этапе:
- Проверяем размер и сжатие страниц в логах.
- Проверяем статику – идет через Nginx, в логах PHP – пусто.
- Если есть 404 ошибка – смотрим статика или динамика.
Запуск нагрузки
После запуска нагрузки важно проверить, чтобы система работала в штатном режиме. Не перегружена ли текущая веб-система:
- /server-status (Apache mod_status) - свободные apache есть, БД в норме. Число ошибок и таймаутов смотрим в логах.
- Nginx http_stub_status_module - убеждаемся, что Nginx не загружен.
apachetop –f <лог nginx>, <лог apache>- скорость запросов, есть ли проброс статики с Nginx на Apache - здесь в логе можно увидеть и поправить ошибки, если они есть.- Число потоков в БД – должно быть разумное:
- mysql:
show processlist– должно быть пусто или почти пусто. - Лог медленных запросов к БД – не растет.
- mysql:
- CPU – нагрузка должна быть адекватная (50% - норма, 80-90% - уже много, система должна дышать).
- Память – система не уходит в swap, swap не должен расти.
- Трафик к клиенту и БД.
- Нагрузка на диск.
Если все в норме, то оставляем тестироваться проект на сутки. Если есть какие-то ошибки, то не нужно тратить время на тест, а нужно выявлять ошибки и после устранения начать тест заново.
Трактуем результаты
Nginx
Считаем процент ошибок в логах NGINX:
- Ошибка 200 – 95%
- Ошибки 50x – 5%.
Нужно выяснить причины каждой ошибки. Очень важно исключить 50х ошибки.
Ошибки типа Segmentation fault (SIGSEGV) исправляются так:
- включаем сбор coredumps на сервере;
- компилируем PHP/httpd с включенной отладочной информацией (флаг
-g); - анализируем coredumps с помощью gdb;
- удаляем, перенастраиваем "сбойные" модули/конструкции.
- Latency (200 OK) для статики: среднее, 90%, 99%, распределение.
- Время соединения с upstream больше 1 сек - это означает, сколько Nginx ждал пока upstream ответит. Смотреть и увеличить число Apache.
Apache/php-fpm
- % ошибок в логах apache/php-fpm:
- segfaults – бывают редкие случаи. Ищем причины.
- fatal errors – не должно быть.
- warnings - не должно быть.
- php-fpm slow log.
- latency (200 OK): cреднее, 90%, 99%, распределение.
- Использование памяти скриптами нежелательно превышать порог в 512 Мб.
Связываем с логом NGINX.
База данных
- Число медленных запросов – ищем откуда и какие запросы в нагрузке, простые запросы выполняются 5-10сек - это значит, что БД ушла в swap, CPU-загрузка и базе не хватало ресурсов.
- Пики числа потоков в БД.
- Анализ медленных запросов и их оптимизация.
Связываем с логом NGINX.
Для клиента
Опираясь на технические результаты тестирования, важно правильно и понятно преподнести выводы теста клиенту.
- Число хитов (10 млн. хитов) - клиенту важно знать, что его проект выдерживает большое количество хитов в сутки.
- Продолжительность тестирования (сутки) - сюда входят также и обычная работа сайта во время теста - бекапы, cron-задачи, import\export каталога и т.д.
- Время построения страницы: 0.3, 0.4, 1.1... (0.3-0.4 сек - это норма).
Например, на основе данных построения страницы можно показать еще такой расчет:
90% хитов уложились в 2 сек, а 10% хитов - выполнялись более 2 сек при среднем времени всех хитов 0.3-0.4.
99% хитов уложились в 5 сек, 1% выполнялись более 5 сек и т.д. - Распределение запросов по времени - гистограмма.
- Процент ошибок (0.2%) – клиенты получили страницу об ошибке 50x.
- Красивые графики и цифры.
Создание тест-плана jmeter на 5-10 млн. хитов
В данной главе рассмотрим на примере, как готовить нагрузку в Jmeter-е и нагрузить систему до 10 миллионов и более хитов.
Независимо от типа проекта, всегда существует человеческий фактор и вероятность ошибок. Нагрузочное тестирование позволяет выявить и устранить потенциальные проблемы, что существенно снижает риски в будущем.
Учимся считать нагрузку
На что нужно обратить внимание при тестировании
- Уникальные посетители в сутки:
- Хиты к динамике в сутки;
- Хиты к статике в сутки.
- Производительность API в случае, если оно открыто для внешних пользователей, - это тоже создает нагрузку на систему.
- Экспорт/импорт данных.
Это важный момент. Например, запустили нагрузочное тестирование, оно прошло успешно, результатом остались довольны. Но не учли тот факт, что в проекте есть каталог с базой данных на 1 млн. объектов. Запустили проект, пошла реальная нагрузка, и системе понадобился экспорт/импорт каталога - и в итоге система может стать неустойчивой или вообще перестанет отвечать на запросы пользователей. Поэтому во время нагрузочного тестирования нужно учитывать подобные критические сценарии и включать их в тест.
- Пик и общая посещаемость за сутки
Важно различать пик посещаемости и общую посещаемость в сутки - пик будет всегда больше.
Рассмотрим пример графика посещаемости за неделю:
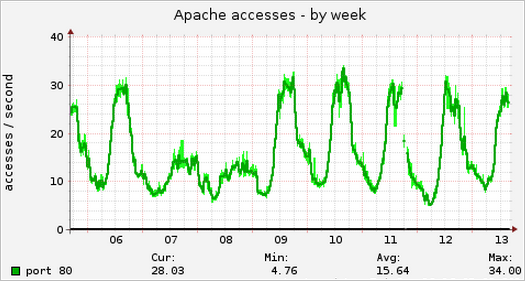
Получаем по логам сервера за сутки – 1,5 млн. хитов к динамическим данным. Среднее количество запросов в секунду высчитывается как 1,5 млн./86400 = 17 запросов/сек, но на графике в пике видим 34 запроса/сек.
Поэтому всегда нужно готовиться к пикам выше среднего в 2-3 раза, а точнее - смотреть по графикам и логам сервера, т.е брать для нагрузочного тестирования количество запросов в секунду, исходя из пикового значения нагрузки проекта, а не из среднего.
- Работает ли система в штатном режиме при тестировании
Важно знать, не перегружена ли текущая веб-система при нагрузочном тестировании. При тестировании, например, нужно следить, не заполнены ли все процессы Apache (mod_status), не допускать скопления очередей на NGINX, запросы к базе данных не должны «висеть» (
show processlist) - все это может привести к недостоверным результатам тестирования.Например, эта перегруженная веб-система может «отбрасывать» запросы:
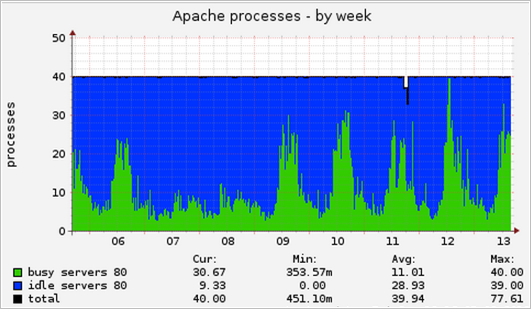
- Пользователи и хиты
Примерное количество хитов, которое создает пользователь в секунду - 10. Определить примерную величину можно также по веб-аналитике текущего сайта или с помощью данных внешних источников (например, Google Analytics).
Если тестируется портал компании, то общее количество хитов в сутки считается, исходя из количества сотрудников и продолжительности рабочего дня. Можно также добавить некоторое количество хитов «про запас».
- Цепочки
Цепочки - это, по сути, поведение клиентов на сайте, куда будут ходить пользователи/сотрудники. Варианты цепочек берутся из аналитики или придумываются самим (на основе типичного поведения пользователя на сайте данной тематики). Глубокое исследование не требуется, только лишь основное поведение.
Пример цепочки 1:
1.1 Главная 1.2 Список новостей 1.3 Детальная новости 1.4 Поиск по сайту
Пример цепочки 2:
2.1 Детальная каталога 2.2 Авторизация 2.3 Корзина 2.4 Мастер заказа 2.5 Личный кабинет
Далее нужно распределить потоки виртуальных пользователей по цепочкам (опять же не нужно глубокое исследование, только лишь основные крупные доли).
К примеру, получилось такое распределение путей следования посетителя по сайту:
70% - Главная 20% - Каталог – Корзина – Мастер заказа 5% - Результаты поиска – Описание товара – Корзина 5% - Новости – Новость детально
Важные моменты
- Клиенты должны уметь авторизовываться.
Во время авторизации работают БД, сети и т.д, таким образом, создается нагрузка, причем приближенная к боевой.
- Логины, пароли, ID элементов, поисковые слова лучше сделать разными.
Создание уникальных пользователей для тестирования также важно, и это также позволяет приблизиться к реальной работе проекта. Все эти данные можно хранить в CSV-файлах и подключать к Jmeter при тестировании. Количество создаваемых пользователей - примерно в 2-3 раза больше прогнозируемого количества посетителей.
- Случайные паузы между хитами создают приближение тестируемой нагрузки к реальной работе пользователей с сайтом.
- Обязательно нужны демо-данные (каталог, форум и т.п) - тестировать пустой сайт нет смысла.
Предварительные данные для сценария нагрузочного тестирования
Для сценария нагрузочного теста понадобится количество потоков в каждой цепочке. Для этого предварительно нужно рассчитать, сколько хитов в данной цепочке клиент сделает за сутки.
Пример распределения путей следования посетителя по сайту:
1.1 Главная Пауза ~ 30 сек + случайная пауза 1.2 Список новостей Пауза ~ 30 сек + случайная пауза 1.3 Детальная новости Пауза ~ 30 сек + случайная пауза 1.4 Поиск по сайту Пауза ~ 30 сек + случайная пауза -> в начало
В итоге получается, что один клиент, ходящий по цепочке, создаст нагрузку примерно 3000 хитов\сутки (86400/30).
Зная пропорции распределения путей следования посетителя по сайту (см. ранее) и имея для тестирования общее количество хитов в сутки (из технического задания), подбирается число нагрузочных потоков (виртуальных пользователей) в каждой цепочке.
Пример расчета:
Пусть за сутки нужно протестировать проект в 5 млн. хитов. В цепочке производится 3000 хитов в сутки одним пользователем.
Тогда получается примерное количество потоков в каждой цепочке
70% - Главная: 3500000 хитов \ 3000 = 1167 потоков. 20% - Каталог – Корзина – Мастер заказа: 1000000 хитов \ 3000 = 333 потока. 5% - Результаты поиска – Описание товара – Корзина: 250000 хитов \ 3000 = 84 потока. 5% - Новости – Новость детально: 250000 хитов \ 3000 = 84 потока.
Если нужно в тесте увеличить общее количество хитов в сутки (к примеру до 10 млн. в сутки), то также, зная пропорции, можно легко подобрать число нагрузочных потоков (виртуальных пользователей) в каждой цепочке.
Итак, зная составляющие нагрузочного тестирования, приступаем к созданию плана нагрузочного тестирования в Jmeter.
Создание сценария тестирования в Jmeter
Тестовый пакет Jmeter представляет собой модульную систему, он очень удобен и функционален. Документацию по работе с программой можно прочитать на сайте разработчика. Рассмотрим наиболее часто используемые элементы тест-плана Jmeter
Глобальные переменные
Использование глобальных переменных очень удобно - это позволяет управлять настройками всех цепочек централизованно.
Настройка числа нагрузочных потоков
Число потоков при создании цепочки как раз задается глобальной переменной CHAIN1_USERS, а общее время теста TOTAL_TIME.
Структура запроса в цепочке
Настройка запроса в цепочке проста - задается название цепочки, путь для запроса, метод GET\POST, редиректы, KeepALive и другие необходимые данные.
Случайная пауза
Для эмуляции реальной работы пользователя используется время паузы между хитами Constant Delay Offset и время случайной паузы (небольшое отклонение от постоянной паузы) Random Delay Maximum.
Случайная страница
Случайные страницы вносятся в цепочку для того, чтобы немного отклониться от предполагаемого пути следования посетителя по сайту. Для этого устнавливается в цепочке контрол Random Controller и в нем уже создаются варианты случайных запросов.
Очистка cookies в конце цепочки
Cookies играют важную роль, практически, на любом сайте. Они участвуют в авторизации и их использование необходимо включать в тест. Также желательно активировать опцию Clear cookies each iteration, что позволит после прохождения потока цепочки сбрасывать авторизацию.
Переменные данные из внешних файлов
Очень удобно хранить логины/пароли, поисковые фразы, ID элементов каталога в CSV-файлах, которые создаются заранее и подключаются в настройках цепочки выбором соответствующего пункта меню.
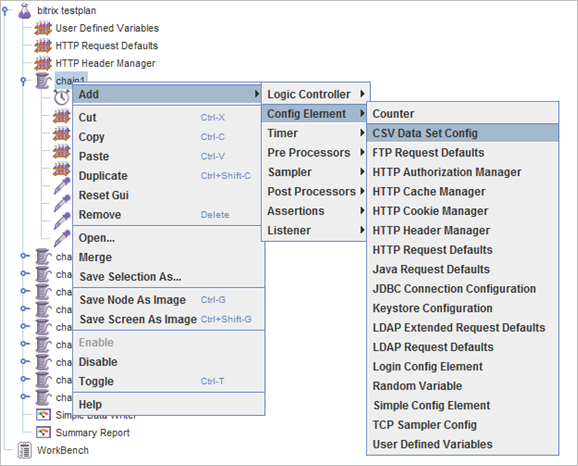
Далее задается имя файла с данными и название переменной.

Которая потом указываются при создании запроса цепочки.
Важной момент: желательно выставить опцию Recycle on EOF в значение True для того, чтобы при окончании значений переменных в файле начиналось чтение его заново и т.д.
Авторизация
Например, для задания авторизации при тестировании проектов на Bitrix Framework нужно использовать переменные:
USER_LOGIN = $(login);USER_PASSWORD = $(password);AUTH_FORM = Y.
Таким образом, с помощью Jmeter можно создавать как простые, так и сложные сценарии нагрузочного тестирования систем.
Распределенное тестирование
[ds]Jmeter[/ds][di]Это инструмент для проведения нагрузочного тестирования, разрабатываемый Apache Software Foundation.
Интересна возможность создания большого количества запросов с помощью нескольких компьютеров при управлении этим процессом с одного из них. Архитектура, поддерживающая плагины сторонних разработчиков, позволяет дополнять инструмент новыми функциями.
В программе реализованы механизмы авторизации виртуальных пользователей, поддерживаются пользовательские сеансы. Организовано логирование результатов теста и разнообразная визуализация результатов в виде диаграмм, таблиц и т. п.
Подробнее...[/di] умеет создавать огромную нагрузку в десятки миллионов хитов в сутки. Так как программа написана на Java, то узким местом для создания большой нагрузки на проект может быть как железо нагрузочной машины, так и пропускающая способность сетей передачи данных.
Поэтому для создания огромной нагрузки в десятки миллионов хитов можно использовать распределённую нагрузку, кластер из нескольких машин:
- Запускается на каждом сервере:
JMETER_HOME/bin/jmeter-server
- Создается remote port-forwarding c серверов кластера на управляющий сервер:

- На управляющей машине в
/bin/jmeter.propertiesуказываются «виртуальные» серверы кластера, которые получились после проброса портов с машин кластера, участвующих в распределенном тестировании:remote_hosts=127.0.0.1:60001, 127.0.0.1:60002, 127.0.0.1:60003
- Далее в Jmeter на управляющем сервере запускается удаленное тестирование (Run - Remote Start), при этом управляющий сервер передает план тестирования на остальные серверы кластера:

Также для запуска не через GUI-интерфейс Jmeter можно воспользоваться консольной командой:
jmeter -n -t script.jmx -R server1,server2...
где:
script.jmx – название файла с планом тестирования;
server1, server2 – адреса серверов кластера. - Результаты нагрузочного теста собираются в единый лог-файл для дальнейшего анализа.
т.е пробрасываются рабочие порты Jmeter, который запущен на машинах кластера, на порты управляющей машины (например 60001, 60002, 60003 и т.д.).
Примечание: Более подробную документацию по распределенной нагрузке с помощью Jmeter можно прочитать на сайте разработчика.
Мониторинг и аналитика
Мониторинг и аналитика
Разрабатывая проект, нужно сразу думать о том, как мониторить его состояние в период эксплуатации. Перезапуск Apache и MySQL помогает почти всегда, но не является "правильным" выходом, так как не диагностируется и не исправляется проблема. А о проблемах, при отсутствии системы мониторинга, узнаётся либо от клиента, либо от посетителей, либо от собственного руководства, что совсем не является признаком качественной работы студии.
Цель этой главы - понять, какой бизнес-процесс нужно выстроить, чтобы взять процесс эксплуатации под контроль. Высоконагруженные проекты имеют тенденцию со временем деградировать, подчиняясь закону энтропии. Тем не менее, проект можно поддерживать, делать его простым, прозрачным и удобным. Он будет развиваться, приносить и пользу и радость.
Почему у проекта возникают проблемы
- Проектирование. Не всегда достаточно выделяется времени на этот этап - это субъективный фактор. Требования меняются до самого конца - это объективный фактор, не зависящий ни от студии, ни от менеджера. В результате отсутствия или не должного проектирования бывают не предусмотрены многие аспекты, которые, как потом выясняется, можно было предусмотреть и предотвратить.
- Сжатые сроки на развертывание веб-проекта на хостинге. Это проблемы бизнеса, который требует запуска проекта "ещё вчера" или "раньше конкурентов", но реализовывать эти требования - разработчику. Работа в таких условиях требует немалого опыта.
- Мало кто проводит и умеет делать нагрузочное тестирование, так как главное тут - опыт.
- Не все задумываются над организацией: мониторинга, резервного копирования, обновления софта на серверах и подобных "второстепенных" задач.
Система запускается "как есть" и по инерции может поработать год-два без вмешательства. Но невыполнение (не полное выполнение) вышеописанных требований ведёт к деградации системы.
Деградация может быть остановлена, а может быть ускорена. К сожалению, достаточно часто происходит второе в силу:
- В случае торможения системы не ищутся причины, а принимаются меры приводящие к сиюминутному результату: перезапускается Apache или MySQL и подобные решения.
- Программисты что-то дописывают на "боевых" серверах, зачастую без тестирования: так быстрее.
- Меняются программисты и менеджеры проекта и при отсутствии документации теряется логика развития: никто не представляет себе систему в целом, как единый организм.
Важно! Если нет возможности/желания создавать полноценную систему мониторинга проекта, то хотя бы раз в несколько дней пробегайте глазами все логи.
Как должно быть: идеальная система
Создать идеальную систему не сложно. Сложно в условиях постоянного давления со стороны бизнеса её поддерживать в должном состоянии. (А давление заключается в постоянном внесении изменений в проект.) Но к этому надо стремиться, этого надо добиваться:
- Доступ на сервера строго ограничен кругом квалифицированных администраторов, занимающихся только эксплуатацией проекта. Разработчики могут их только консультировать.
- Вся система должна быть покрыта "датчиками" и мониторится. Уведомления должны идти на SMS, в крайнем случае на e-mail. Хорошо, если есть дежурные администраторы в режиме 24/7.
- Перед попаданием на рабочий сервер код должен обязательно пройти цепочку серверов (develop, testing, stage сервера) для функционального и нагрузочного тестирования.
- Рабочие сервера должны быть "стерильны", код выкладывается только через систему контроля версий.
- ПО на серверах постоянно обновляется, "дырки" закрываются, предварительно всё тестируется.
Если нет своего администратора
Если нет своего администратора, то придётся обращаться либо к услугам аутсорсинга, либо использовать внешние системы типа Яндекс.Метрики, которые смогут вам сообщить хотя бы о недоступности вашего сервиса.
Для стабильной эксплуатации системы нужно:
- Ввести строгий регламент работы для программистов и администраторов.
- Покрыть систему "датчиками". Это подскажет где что не так.
- Анализировать тенденции движения системы. Нужен прогноз того, что может случиться с системой завтра, через неделю, в течение месяца.
Организация системы мониторинга
Организация системы мониторинга
Несколько принципов организации системы мониторинга:
- Лучше использовать стандартные решения (Nagios, Zabbix и т.п.), а не самописные. Собственная система - это долго и дорого. Лучше потратить время на изучение какой-то стандартной системы и научиться писать к ней плагины, чем разрабатывать свою. Самописные системы тяжело развивать, особенно новым сотрудникам, не принимавшим участие в её создании. Такие системы сложно кастомизировать под возникающие новые ситуации.
- Система мониторинга не имеет смысла без организации дежурных смен (и/или мгновенных уведомлений администратору) для устранения проблем.
- Мониторить нужно по максимуму, в идеале: всё. Загрузку процессоров, дисков, памяти, а также какие-то специфичные метрики, которые вы определили для своего приложения. В том числе и нестандартные вещи: домены, сертификаты, баланс sms.
- Но мониторить нужно аккуратно. Тысячи уведомлений будут бесполезны, более того, в потоке некритичных уведомлений можно легко пропустить то единственное, от которого жизненно зависит работа проекта. Правило должно быть таким: пришло уведомление - значит серьёзная проблема или авария.
- Автоматизация типовых реакций. Например, кончается место, надо пойти очистить какую-то типовую папочку. Это можно автоматизировать и нужно стремиться автоматизировать такие некритичные рутинные операции. В Nagios, например, есть event handler, который по срабатыванию определённых уведомлений даёт команду на выполнение каких-то действий.
- Нужна распределённая система мониторинга, которая может мониторить и саму себя. Если сама система мониторинга отвалится, уведомлений нет, вы считаете что всё хорошо. А на самом деле проект - "лежит". Либо две системы мониторинга: одна мониторит одну часть проекта, вторая - другую, и каждая из них мониторит другую систему мониторинга.
Нужно научиться оценивать как проект работает. Есть много внешних инструментов мониторинга работы проекта в режиме реального времени. Они могут быть очень точными, они могут собирать много информации, но они все работают "снаружи" проекта и показывают симптомы, а не причины.
Полноценные данные с пониманием всех происходящих процессов может дать только само веб-приложение. Для этого нужно научиться мониторить процессы средствами ядра продукта и платформы, которая используется в приложении.
Примечание: В Bitrix Framework есть специальный модуль для мониторинга работы системы.
Мониторинг железа
Собственный сервер нуждается в постоянном контроле за его комплектующими. Можно разделить контроль по видам ресурсов: Критический и важный. Критический - это те, сбой которых гарантировано приведёт к отказу бизнес-приложения. Важные ресурсы - это те, наблюдение за которыми позволит предсказать возникновение проблем.
Критические ресурсы:
- CPU;
- Memory;
- Пропускная способность дисков и сами диски;
- Traffic к серверу.
Важные ресурсы:
- RAID status.
- S.M.A.R.T. - вероятность выхода дисков из строя.
- IOPS - анализ количества операция с дисками в секунду.
- Disk avio - среднее время ответа на запрос к нему. Если avio равно примерно 10 мс, то пора задуматься о замене дисков.
- Sockets - количество используемых сокетов на сервере.
- CPU temperature.
- CPU fan speed.
Чем мониторить?
- Рейды проверяются аппаратными или программными средствами.
- Жёсткие диски контролируются SMART-утилитами, которые не являются панацеей, но достаточно надёжное средство прогнозирования состояния диска.
- Для контроля остальных комплектующих есть аппаратные средства контроля от вендора сервера. Это, как правило, небольшая устанавливаемая на сервере плата позволяющая оценивать его состояние.
Мониторинг ПО
Мониторинг самой ОС выполняется по следующим параметрам:
- Место на дисках. Банально, но это реальная проблема отслеживания свободного места для высоконагруженного проекта, особенно при размещении в облаке. Проблема решается достаточно просто с помощью плагина от Nagios.
- Периодическая проверка файловой системы - fsck. Журналирование не всегда спасает.
- Периодическая проверка бекапов на читаемость.
- Нагрузка на диск. Рекомендуется использовать iostat. Полезные данные в колонке %util: показывает насколько устройство загружено. Если около 100%, то диск перегружен, либо выходит из строя. Кроме того можно посмотреть насколько хорошо файловая система работает с потоками. Можно ли одновременно работать с диском и с RAID. Если ОС стоит старая, то всё может работать в один поток, а вы не знаете.
- Очередь выполнения: число процессов, которые хотят быть выполненными центральным процессором. Если их много, то что-то не так: или сервер слабый или софта много запускается или что-то не так в настройках. Контролируется с помощью того же Nagios.
- Размер и использование swap. Надо проверять объём самого swap'а, количество свободного места на нём. Swap - это защитный механизм ОС, если система "вываливается" в swap (то есть из оперативной памяти программы выгружаются на жёсткий диск), то это плохо, так система начнёт тормозить. Контролируется это с помощью того же Nagios. Решение: увеличить объём оперативной памяти.
- Процессы. Рекомендуется использовать vmstat. С её помощью можно отследить число процессов работающих, число непрерываемых процессов (процессы, которые "зависли" на диске либо в сети). Если процессор свободен, а процессы висят, то это означает, что не хватает дисковой мощности.

Полезна представляемая vmstat'ом информация о памяти, которая в Unix системах устроена не просто. В этих системах просто нет свободной памяти, она вся занимается под буфер и кеш. То есть не стоит опасаться малых значений в колонке free. Но должны беспокоить малые значения в колонках buff и cache - это означает, что система не умещается в памяти., нужны изменения в конфигурации.
Полезно контролировать колонку st: наличие в ней значений, отличных от 0 говорит о том, что другая виртуальная машина потребляет время вашего процессора. Ваша виртуальная машина в этом случае будет тормозить. К сожалению, виртуализация может иногда "красть" ваши процессорные ресурсы. Это актуально для облачного размещения.
При мониторинге серверного ПО обратите внимание на:
- для NGINX: RPS (Read Per Seconds) - самая важная характеристика: количество запросов к сайту в секунду.
- для PHP-FPM: RPS, количество активных процессов, количество сообщений об достижении лимита процессов.
- для Sphinx: количество поступающих запросов, отслеживание Fatal Error
В мониторинге MySQL надо тестировать:
- Число работающих потоков (Mysql threads running). Каждый поток занимает какой-то объём оперативной памяти, ресурсы процессора. Если их слишком много, то система начнёт тормозить. Нужно следить чтобы процессор был не перегружен.
- Число медленных запросов (Mysql slow queries). Если БД тормозит, этот параметр нужно проверять в первую очередь. Медленные запросы могут возникать по разным причинам, но если они появляются - это, скорее всего, плохо и надо предпринимать меры.
- Долгие процессы (Mysql long procs). Программисты могут создавать и запускать для своих целей долгие процессы, которые длятся сутки и более. Это бывает причиной перегрузки процессора, а тесты позволяют выловить такие процессы.
- Состояние репликации. Может перезагрузился сервер, система ушла в swap, репликация отстаёт. Стандартный тест Mysql replica позволяет отслеживать отставание и прекращение репликации.
- Гистограмма времени обработки запросов по времени (на примере Percona) позволяет увидеть тормозит или нет сама БД. (В стандартном MySQL этой возможности нет.) Можно выполнить команду, которая строит гистограмму распределения хитов времени исполнения:
Если вы видите, что запросов больше 0,1 секунды много, то, значит, база тормозит. Для каждого проекта "правильный" график будет свой, в зависимости от задач проекта. В Munin можно создать свой плагин, который будет по базам данным выводить табличку запросов, например, запросов длительностью более 0,1 секунды:

При мониторинге сети очень удобна команда netstat. Она позволяет видеть что у вас в сети: кто висит на memcache, кто на php, кто на MySQL.
Можно также использовать утилиты:
- atop - позволяет сохранять снимки состояния системы с определённым интервалом. Завис сервер ночью. Вы можете с указанным интервалом отследить что присходило в системе (диск, процессор, память, процессы) и произвести "разбор полётов".
- ps - оценивает состояние процессов.
- pstree - команда позволяет увидеть дерево процессов, кто кого "родил".
- apachetop - консольная утилита, позволяющая построить гистограмму времени выполнения запросов (по путям) по логам Apache и NGINX. Без этой утилиты крайне сложно понять как нагрузка на проект распределяется по хитам. Позволяет также отследить ситуации, когда NGINX пропускает запросы статики на Apache.
- innotop - утилита для мониторинга MySQL. Позволяет сократить время для анализа работы БД.
Мониторинг веб-приложения
Для каждого бизнес-скрипта, который обязательно должен выполниться (и, если не выполниться, то сообщить об ошибке) нужно вести лог работы скрипта. Nagios при этом должен следить за обновлением этого лога с заданным интервалом. Если файл не обновился, значит скрипт не отработал.
Кроме лога работы можно вести лог ошибок. В Unix есть поток ошибок, который направляется в другой файл. Этот лог должен быть, в идеале, пустой. Однако в нём могут появляться самые непрогнозируемые данные: например, сторонняя программа убила процесс вашего приложения.
Примечание: При работе с логами обязательно нужно выполнять logrotate, иначе, если скриптов много, очень скоро ваш диск переполнится.
Необходимо так же мониторить:
- Число ошибок в хитах за 15 минут - меньше L (например, меньше 5).
- Макс. время хита (тэга) - меньше M сек (например, 10).
- Макс. использование памяти хитом - меньше N МБ. Возможны ошибки в приложении, когда скрипт начинает требовать много памяти (500 Мб и более). Если не контролировать расход памяти, система может уйти в swap.
Делается это с помощью Pinba. Если число ошибок превышает указанные значения в этих параметрах, то необходимо уведомлять администратора по SMS.
Для данных тестов полезно написать плагин для Munin, который будет формировать графики по этим параметрам. Например, среднее время выполнения скрипта:
Или, расход скриптами памяти:
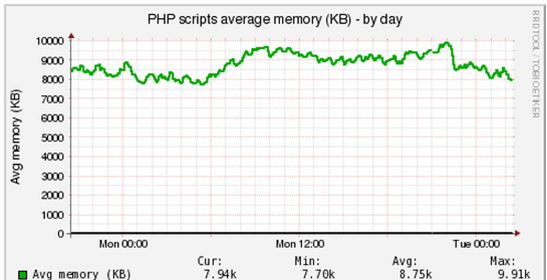
Гистограммы распределения времени хитов, памяти, кодам ответа по времени строятся из логов (awk-скрипт) или Pinba. Смысл этих графиков - визуальное представление состояния вашего приложения: тормозит оно или нет. Например, число запросов с продолжительностью с шагом в 100 ms:
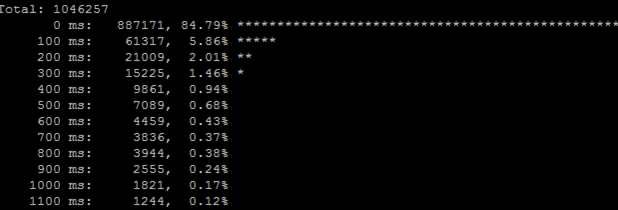
Аналитика
Аналитика
Помимо мониторинга рекомендуется использовать аналитику. Аналитика - это тенденции развития. По её данным можно прогнозировать развитие/деградацию системы. Самый простой пример: по тенденции роста данных вы можете прогнозировать срок, когда переполнится место на дисках и подготовиться к этой ситуации заранее, не доводя систему до остановки.
Для аналитики можно использовать собственные решения, но лучше всё же стандартные. Это лучше делать по тем же причинам, что и для систем мониторинга. Munin, например, кроме стандартных вещей (количество запросов, нагрузка на CPU), позволяет мониторить другие параметры, которые могут быть критичны: скорость генерации страниц, соотношение быстрых и медленных запросов к базе данных. Munin позволят выводить всё это в графики:
Далее рассмотрим, что необходимо анализировать.
Дисковая подсистема
В дисковой подсистеме один из ключевых параметров - Чтение и запись в секунду байт. 10 МБ/cек - это нормальная нагрузка, 100 МБ/cек - это уже повод для беспокойства. Графики за день и за неделю:
Гистограмма Утилизация дисков поможет увидеть когда происходит повышенная утилизация диска и попытаться разобраться в причинах.

Сеть
Можно использовать стандартные графики, не создавая собственных плагинов. Сеть - это обычный TCP\IP. График нормальной, текущей ситуации:
Если что-то пошло не так, то появляются другие кривые, syn_sent, например.
График трафика позволяет также увидеть тенденции изменений. Если, например, трафик обращений к БД за год растёт, то может разработчики чего-то недооптимизировали.
Память
На стандартном графике использования памяти можно увидеть тот самый swap, уход в который не желателен для системы, красный цвет:

На иллюстрации: запущенное приложение стало потреблять память - зелёное на графике - и выдавало всю память из операционной в swap, чем убило несколько приложений (белое на графике). Какой-то скрипт убил несколько MySQL серверов с репликацией. На графике видно почему это произошло.
График так же необходим для контроля за расходом памяти. Зелёную зону на графике желательно держать в районе 70%, не более. Операционой системе нужно оставлять какое-то место для буфера и файлов. Регулировать этот показатель можно с помощью, например, Apache MaxClients или MySQL buffers.
Swap
Своппинга надо избегать. На графике чётко видно, что система в какой-то момент ушла в swap, администратор что-то сделал не так. Либо, что-то случилось с системой. А что случилось можно понять по графику использования памяти.

Нагрузка
Графики нагрузки показывают запущенные процессы (зелёное) и "зависшие" либо в сети, либо на дисковых операциях ввода-вывода (синие).

Чем ниже зелёный график, тем меньше система нагружена. С параметром Load average сложно сказать о конкретных параметрах. 20 или 40? Это сильно зависит от числа процессоров. (20 на 8-и ядерной системе - это нормально, по опыту.) Какое значение параметра показательно для вас вы почувствуете сами по поведению вашей системы. Когда ей "плохо" - она "тупит", значит вы не должны допускать превышения того значения, когда это происходит.
Переключение контекстов и прерываний
Если эти параметры постоянно "скачут", то значит есть ошибки в настройке софта, слишком много процессов запущено. Процессы запускают потоки. Проще начинать оценку с числа потоков, а потом переходить к числу процессов. Если не поставлена верхняя граница потоков для Apache или MySQL, то со временем система "зависает". Рекомендуется ставить в Nagios тесты, которые ограничивают это число.
Memcached
Memcached мониторится бесплатным плагином. Зелёное - место в memcached занятое приложением, оранжевое - число элементов (ключей кеша) которое хранится. Видно сколько живёт кеш и какой размер он занимает.
График команд показывает число запросов memcached в секунду - интенсивность использования. Можно судить насколько memcached востребован.
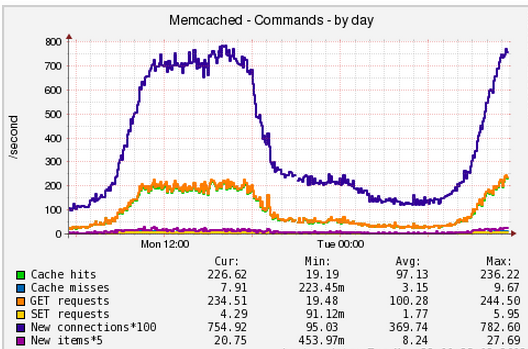
MySQL
Важно смотреть какие типы запросов идут в Базу данных. Это позволяет выбирать настройки MySQL. Например, если много select, то можно попытаться использовать Query Cache, а если много update, то его нет смысла использовать.

Потоки в MySQL. Явный всплеск - это перегрузка для системы. Надо следить за такими моментами, уметь их анализировать и недопускать: конфигурировать число серверов или PHP-FM.
Query Cache вызывает много споров когда он нужен, а когда - нет. Чтобы понять нужен он или нет вашему приложению, лучше всего настроить мониторинг и анализировать. Сколько запросов идёт из кеша, а сколько в кеш. И по соотношению этих запросов можно принять решение нужен этот вид кеша или нет. Без аналитики сделать такой вывод сложно.

График заполнения Query Cache данными показывает насколько используется память.
График медленных запросов показывает когда возникли эти запросы. Это позволяет локализовать проблему и решить её.
График сортировки позволяет судить о качестве разработки. Если разработка не качественная, то возникают в большом количестве scan, merge passes, range. Если работа идёт по индексам, то всего этого не будет в таком объеме.
Машинное обучение для анализа и прогнозирования аварий веб-проекта
Машинное обучение
Predictive maintenance - проактивная стратегия мониторинга. В рамках темы курса - это техническое обслуживание по текущему состоянию, основанное на прогнозировании запаса надежности.
Теория Predictive maintenance достаточно сложна, требует для понимания серьёзной теоретической математической подготовки. Сложна ещё и потому, что с этими сферами математики большинство не сталкивается в обычной жизни. Одновременно с этим Predictive maintenance - это просто, не смотря на обилие кажущейся сложной информации. Это тот случай, когда практика позволяет компенсировать недостаток знаний.
Покрыть веб-проект сеткой тестов недостаточно для предотвращения аварий, выявления атак и превентивного реагирования на изменение условий эксплуатации. Новый подход - анализ метрик и предотвращение аварий (выявление угроз) с помощью алгоритмов машинного обучения. Это позволит не только сократить расходы на обеспечение отказоустойчивости, но и реагировать раньше возникновения проблем.
Считается, что с помощью машинного обучения можно работать эффективнее, чем по классическим алгоритмам. Но не везде и не всегда. Машинное обучение лучше в случаях очень сложных задач, решение которых классическими методами либо крайне сложно, затратно, либо невозможно вообще.
Машинное обучение имеет достаточно высокий уровень вхождения: надо достаточно хорошо понимать много дисциплин: высшую математику, матстатистику, теорию вероятности и так далее.
При этом описание информации зачастую крайне научное, для специалистов по математике и совершенно не приспособлено для ответов на простые вопросы. Например, стоит вопрос классификации: как понять спам - не спам? Прямого и простого описания алгоритма модели для такой классификации не найти.
Тем не менее, несмотря на сложность вхождения, решение есть. Для этого достаточно понимать не так много, это:
- целые числа;
- числа с плавающей точкой;
- полиномиальные значения (одно из значений)
- биномиальные значения;
- даты;
- графы;
- выбросы (данные, которые нужно отбрасывать);
- элементарная статистика.
Аналитик
Анализ и интерпретацию результатов Predictive maintenance желательно поручить выделенному сотруднику или роли. Обязанности аналитика:
- Организовать сбор данных.
- Создать модель. (Минимум программирования, предпочтительнее работа в готовых инструментах.)
- Bigdata - доступ организован как к SQL
Далее рассмотрим основные шаги по внедрению.
Сбор данных
Сбор данных
Изначально сложно сказать какая информация будет вам нужна, какая нет. Поэтому рекомендуем собирать всё.
Где собирать информацию? Хиты на сайте - логи, события, привязанные к cookie (человеку) через "счетчик". Использовать логи работы, мультиканальность, если надо понять как люди движутся между вашими системами.
Допустим, собираем данные о покупателе магазина, всё что есть: пол, возраст, статус, пути на сайте, обращения в техподдержку, счетчики (клики, звонки, обращения), средние данные по счётчикам за квартал, месяц, день. То есть нужно собрать информацию о том, что в динамике делает пользователь.
В контексте системного администрирования, эксплуатации, нужно собирать метрики системы, падение которой будет предсказываться:
- Загрузка процессора user/system (top).
- Скорость позиционирования диска, % утилизации (iostat –xm 5).
- Расход ОЗУ, кэш, своп.
- Время загрузки тестовой страницы API.
- Входящий, исходящий трафик.
- LA, число переключений контекстов (vmstat).
- Другие технические параметры.
Какие метрики критически необходимы? Гарантированной ответ дать крайне сложно, если вообще возможно. Как правило собирается всё, чтобы потом из имеющегося набора получить что-то нужное. Однако последние исследования в области нейронных сетей позволяют решить эту проблему - нейронная сеть сама выделит необходимые метрики для анализа автоматически.
Пример: что собирает Битрикс в магазине
|  |
Анализ данных
Инструменты для анализа
Для анализа собранных данных нужен инструмент. Можно написать своё, а можно использовать готовые решения для создания моделей: Rapidminer, SAS, SPSS и другие. Свои инструменты можно создать на готовых библиотеках: Spark MLlib (scala/java/python) если много данных или scikit-learn.org (python) если мало данных.
Rapidminer - очень удобный инструмент. Модель в нём собирается из "кубиков", есть несколько сот операторов для обучения и статистики. Инструмент позволяет изменять диапазоны параметров, может строить графики. Типовые трудозатраты создания модели в нём - 1-2 часа.
Примерные сроки программирования если выбрано создание собственного инструмента, при достаточном опыте, - небольшие. Модель вообще не должна быть большой. Создание модели в коде из 5 строк - это 10 минут.
Обучение модели - минуты, десятки минут. Очень редко (использование опорных векторов, нейронные модели) и при необходимости - часы, дни, особенно при использовании DeepLearning.
Оценка качества модели - десятки минут с использованием метрик AUC (area under curve), Recall/Precision, Cross-validation. Методика оценки проста: делается бинарный классификатор и доказывается что он работает точнее обычного гадания Да/Нет. Если работает на 10-15% лучше, то модель годна, можно опробовать её "в бою". Данного результата достаточно в 80% случаев.
Если данных много, то обработка происходит долго. Для ускорения можно использовать векторизацию текста, LSH (locality sensetive hashing), word2vec.
Визуализация
Первое что нужно сделать - научиться визуализировать полученные данные: строить графики, гистограммы и так далее. Визуализация позволяет понять как у вас распределены данные и что у вас с ними происходит.
Как правило инструменты для этого есть у всех. Это Munin, Cacti, InfluxDB. Если размерностей много, то можно их сжать (PCA, SVD). Перед началом использования сложных инструментов всегда надо попробовать решить задачу простыми средствами.
Простейшие и первейшие это гистограммы: время загрузки страницы, вызов метода API, время жизни ключей в redis.
Кластерный анализ
Если рассыпать много шариков по полу, то где-то они будут в одиночестве, а где-то соберутся в кучи. Это в двухмерной плоскости. Если плоскость трёхмерная, то получатся "облачка". Вот эти "облачка" и кучи и есть кластеры.
Кластерный анализ нужен когда есть несколько (больше чем три) векторов измерений. Например:
- частота процессора - загрузка за 5 минут, 10 минут, 15 минут;
- load everage - загрузка за 5 минут, 10 минут, 15 минут;
- нагрузка на диск за 5 минут, 10 минут, 15 минут;
- и так далее.
Эти данные кластеризуются, то есть ищутся "облачка" и получается типизация нагрузки на серверы.
Виды кластерного анализа:
- Иерархическая
- K-means
- C-means
- Spectral
- Density-based (DBSCAN)
- Вероятностные
- Для "больших данных"
Для нашей задачи вполне достаточно использовать K-means.
Кейсы кластерного анализа:
- Основные типы нагрузки на сервер (высокая нагрузка базы, большая нагрузка на CPU, низкая нагрузка на сеть).
- Типы клиентов API (позволяет адаптироваться к самым востребованным клиентам API).
- Виды нагрузки на БД из веб-приложения.
- Виды DDOS.
- Нагрузка, создаваемая страницами веб-приложения.
Кластерный анализ – оценки на программирование:
- Анализ в Rapidminer (0.1-2 часа)
- Анализ в Spark Mllib (1-2 дня, много данных)
- Анализ в scikit-learn – аналогично (мало данных)
На выходе нужно получить список кластерных групп, лучше с визуализацией.
Метрики качества кластеризации достаточно просты: кластера должны быть явно видны. Есть строгие математические понятия: плотность и прочие, но в нашем случае достаточно простой визуализации с явным выделением кластеров.
Классификация
Классификация и кластеризация - разные вещи. Кластеризация - автоматическая группировка данных в многомерном пространстве. Классификация - обучение компьютера распределять сущности по классам.
Два вида классификации:
|
|
Собраны метрики с серверов (например, 50 плоскостей), раскидываем точки в 50-имерном пространстве. С помощью машинного обучения строим гиперплоскость (плоскость в 50-имерном пространстве). Далее системе говорится, что если вектор попадет в какое-то место этой плоскости, то сервер упадёт через час. И это сбывается в 70% случаев.
В рамках задачи безопасной и эффективной эксплуатации можно предложить такие кейсы:
- Когда начнут появляться 500-е ответы клиенту.
- Когда страницы будут выдавать ошибки соединения с БД.
- Увеличится время ответа API: да/нет
- Сервер будет перегружен: да/нет
- БД начнет «тормозить»: да/нет
- Apache забьется запросами: да/нет
- Начинается DDOS: да/нет
- Кэширование не везде включено: да/нет
- Сжатие не включено: да/нет
В чём разница между человеческим реагированием и машинным? Машина предотвращает эти ошибки, человек реагирует на уже совершённые ошибки. Есть специалисты, которые могут отслеживать работу и квалифицировано предотвращать проблему. Но такие люди редки и дороги. Машинное обучение - замена таким дорогим специалистам.
Советы и секреты
Не усложняйте себе работу. Начинать всегда лучше с самой простой модели, например, Naive Bayes - простейшего байесовского классификатора, который работает хорошо в 80% случаев. В случае неудовлетворительной работы этой модели можно попробовать Метод опорных векторов (support vector machine), которая обучается медленнее, но работает точнее.
Если и в этом случае не получился приемлемый результат, то можно попробовать поменять ядро и, в самом крайнем случае, попробовать нейронные сети, но это не очень-то приветствуется в силу сложности, трудозатратности и других трудностей.
Как оценивать качество работы?
- Для бинарного классификатора лучше всего - ROC-кривая (area under ROC curve, площадь под ROC-кривой), которая должна быть больше 0.5: 0.6, 0.75, 0.8 - это уже отличный результат. Так же можно оценить с помощью параметров Recall (полнота) и Precision (Точность).
- Для мультиклассового классификатора удобна Confusion matrix.
Всё в целом выглядит просто: есть данные, есть оттренированная модель, которая научилась решать вашу задачу (когда зависнет сервер), определили качество модели, можно выходить "в бой".
Модель нужно ставить на самое критичное место в вашей эксплуатации.
Данные нужно периодически обновлять: раз в неделю, раз в месяц - частота зависит от ваших задач. После смены данных нужно тестировать модель заново.
Другие полезные алгоритмы
То, что мы получили в ходе анализа, нужно перевести в практическую плоскость
Регрессия
Регрессия - попытка предсказать некоторую величину. Например, расходы на "железо", объём траффика, число запросов к API и так далее. На вход подаются вектора, на выходе получается значение.
Принцип работы - аналогичный: выявление атрибутов, далее выбор алгоритма (Spark MLlib может не сработать в этой задаче, на scikit-learn требуется 1-2 дня).
Дерево решений
Это попытка объяснить суть принятых решений. В нашем случае: почему сервер повиснет через 3 часа? Дерево решений поможет понять какие именно атрибуты из собираемых влияют на решаемую проблему. Например: одновременно, увеличивается нагрузка на процессор, уменьшается нагрузка на диск и зигзагообразно скачет трафик - предвестники того, что сервис выйдет из строя.
На основании собранных данных (хиты, логи, анкетирование) строится дерево решений. В Rapidminer полчаса уйдёт на это, в Spark MLlib чуть больше.
Стратегии
Когда приходится "чинить" - это плохо. Это кроме всего прочего - большой удар по репутации. Реактивный подход - это первый, начальный шаг в вашей работе и чем раньше вы закончите с ним и перейдёте к предупреждению проблем - тем лучше.
Проактивный подход - это когда вы на основе построенной модели начинаете принимать решения задолго до проявления их последствий. Это существенно снижает стоимость поддержки. Далее необходимо найти причину проблемы и исправить её.
Стратегия расходов. Тратите мало денег - система падает, тратите много - система не падает. А где оптимум? Оптимум -это место на графике где денег тратиться не много по отношению к уровню получаемой стабильности работы системы.

Правильно сделанные и настроенные модели экономят вам не только деньги, но и людей.
Пример решения проблемы блокировки сессий
В последнее время все чаще проявляется проблема блокировки сессий во время эксплуатации проектов на PHP. По умолчанию PHP создает файл для сессии, и процесс его блокирует. Остальные процессы, пытающиеся открыть сессию, выстраиваются в очередь. Логика приложения, особенно, если она сложная, не всегда позволяет эффективно ограничить время блокировки конкурирующих за сессию процессов. Ситуация усугубляется еще тем, что 3-5 подобных клиентов способны быстро забить зависшими и простаивающими в ожидании процессами PHP worker'ы и веб-проект «зависает».
В качестве решения проблемы можно использовать достаточно простой скрипт на AWK. Скрипт выбирает процесс, вызвавший коллапс PHP worker'ов из группы висящих блокировок, и прерывает его:
lsof | awk ' /sess/ {
load_sessions[$9]++;
if (load_sessions[$9]>max_sess_link_count){
max_sess_link_count = load_sessions[$9];
max_sess_link_name = $9;
};
if ($4 ~ /.*uW$/ ){locked_id[$9]=$2};
}
END {
print max_sess_link_count, max_sess_link_name,locked_id[max_sess_link_name];
if (locked_id[max_sess_link_name] && max_sess_link_count>10) {
r=system("kill "locked_id[max_sess_link_name]);
if (!r) print "Locking process "locked_id[max_sess_link_name]" killed"
}
}'
Обеспечение отказоустойчивости
Обеспечение отказоустойчивости
При переносе бизнеса в интернет каждый час простоя несет в себе потерю заказов и репутации, неэффективность рекламных кампаний и переиндексаций поисковыми роботами, т.е. стоит зачастую немалых денег.
Сайт должен работать стабильно, без ошибок и задержек. По результатам исследования компании GoMez, занижение скорости загрузки страниц на 1 секунду снижает конверсию на 7%, а количество просмотров - на 11%.
Примечание: исследование Strategic Research Institute показало, что 60% предпринимателей после утраты всех данных прекращают свою предпринимательскую деятельность в течении полугода.
Обеспечение отказоустойчивости критично для проектов, ключевым моментом деятельности которых является высокий уровень доверия со стороны пользователей, Business critical application: веб-сервисы, использующиеся в работе, CRM, бухучет, таск-менеджмент, почта, Битрикс24 и так далее.
Ключевым моментом отказоустойчиваости является система мониторинга.
В контексте отказоустойчивости техническое задание на сайт должно включать в себя:
- количество хитов в сутки;
- скорость загрузки главной страницы сайта при указанном количестве хитов;
- среднее время загрузки всех страниц в сутки;
- процент страниц с временем загрузки более n сек;
- допустимый процент ошибок;
- допустимое время простоя;
- время реакции;
- перечень возможных отказов с приоритетами;
- прогноз объема и характера нагрузки;
- способы реакции на отказы и аварии
Основные принципы
Основные принципы разработки и эксплуатации, обеспечивающие высокую отказоустойчивость:
- отказ от синхронного использования в коде внешних ресурсов;
- не оперировать в памяти большими массивами данных;
- контроль памяти при работе с картинками;
- анализ логов NGINX, Apache: awk, grep;
- ведение дополнительных логов - CPU user/system%, memory usage, логи приложения и компонентов;
- фиксирование в логах NGINX время отработки upstream -
$upstream_response_time; - исследование причин медленной работы PHP – php-fpm slowlog;
Важно! Актуально для работы PHP в режиме PHP-FPM.
- считывание трейсов страниц, помогающих обнаружить медленно отрабатывающие скрипты:
ini_set('xdebug.collect_params', 3); xdebug_start_trace(); … xdebug_stop_trace(); TRACE START [2013-01-29 14:37:13] 0.0003 114112 -> {main}() ../trace.php:0 0.0004 114272 -> str_split('Xdebug') ../trace.php:8 0.0007 117424 -> ret_ord('X') ../trace.php:10 0.0007 117584 -> ord('X') ../trace.php:5 0.0009 117584 -> ret_ord('d') ../trace.php:10 …XDebug - свободная библиотека, призванная максимально упростить отладку php-скриптов. Следует иметь в виду, что его использование, в отличие от XHProf, снижает производительность. Не рекомендуется применять на "боевых" серверах.Также о причинах и способах устранения медленной загрузки страниц вы можете прочитать в блоге.
- сбор и анализ ошибок SQL:
define("LOG_FILENAME", "/var/log/db_error.log"); - наблюдение за запросами в БД (лог медленных запросов MySQL, innotop);
- резервные копии файлов и базы данных и умение быстро из них восстанавливаться;
- real-time мониторинг;
- резервирование критичных узлов.
- при разработке на Bitrix Framework использование стандартных возможностей Монитора Производительности:
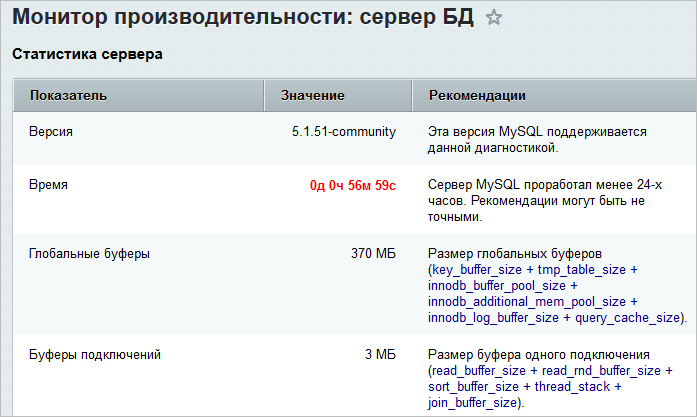
Отладка сложных веб-приложений
Отладка сложных веб-приложений
Многие проекты обходятся командами var_dump и echo. Однако, по мере усложнения проектов, разработчики скорее всего установят на локальных серверах что-то типа XDebug или Zend Debugger, что разумно и действительно упрощает отладку веб-приложения, если научиться этими штуками грамотно пользоваться.
Очень часто оказывается полезным XDebug в режиме сбора трейса. Иногда без трейса отловить ошибку или узкое место в производительности просто невозможно. Тем не менее, есть одно весомое "Но" - эти инструменты создают серьезную нагрузку на веб-проект и включать их на боевых серверах - опасно. Инструменты помогут вам «вылизать» код на локальных серверах, но «выжить на бою», к сожалению, не помогут.
Логирование
Очень полезно, если нагрузка позволяет, включить на боевых серверах лог-файлы nginx, apache, php-fpm, вести свои лог-файлы бизнес-операций (создание особенных заказов, экспорт из 1С-Битрикс в SAP и т.п.).
Если у вас веб-кластер или просто много серверов с PHP - попробуйте собирать логи с этих машин на одну машину, где их централизованно мониторить. Используйте для этого, например, syslog-ng. Имея лог ошибок PHP со всех серверов кластера на одной машине, вам не придется бегать при аварии искать их по машинам.
xhprof
Существует отличный и полезный "боевой" профилировщик xhprof. Он практически не создает на нагрузку на PHP (проценты).
Он позволяет увидеть профиль выполнения хита:
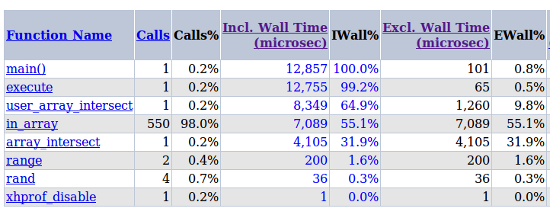
А также критический путь, что же тормозило-то на бою:

Причем он хорошо сочетается с встроенным инструментом отладки платформы Bitrix Framework (если у вас веб-решение на этой платформе): xhprof можно запускать на бою в пиках нагрузки, а Монитор производительности - когда нагрузка не зашкаливает или на серверах разработки/тестирования.
Динамическая трассировка
Если у вас веб-кластер, нередко удобно автоматизировать процесс динамической профилировки. Суть проста: профилировщик постоянно включен, после исполнения страницы мы проверяем время хита и если оно больше, к примеру, 2 секунд, сохраняем трейс в файл. Да, это добавляет лишних 50-100 мс, поэтому можно включать систему при необходимости либо включать по каждому, например, десятому хиту.
Файл auto_prepend_file.php://Включаем профайлер по переменной или куке, хотя можно включать сразу
if (isset($_GET['profile']) && $_GET['profile']=='Y') {
setcookie("my_profile", "Y");
}
if (isset($_GET['profile']) && $_GET['profile']=='N') {
setcookie("my_profile", "",time() - 3600);
}
if ( !( isset($_GET['profile']) && $_GET['profile']=='N') && ( $_COOKIE['my_profile']=='Y' || ( isset($_GET['profile']) && $_GET['profile']=='Y') ) && extension_loaded('xhprof') ) {
xhprof_enable();
}
Файл dbconn.php:
//Время выполнения хита получаем из пинбы, но можно в принципе напрямую из PHP (http://php.net/manual/ru/function.microtime.php)
//Forcing storing trace, if req.time > N secs
$profile_force_store = false;
$ar_pinba = pinba_get_info();
if ($ar_pinba['req_time']>2) $profile_force_store=true;
...
if ($profile_force_store || ( !(isset($_GET['profile']) && $_GET['profile']=='N') &&
( $_COOKIE['my_profile']=='Y' || ( isset($_GET['profile']) && $_GET['profile']=='Y' )) && extension_loaded('xhprof') ) {
$xhprof_data = xhprof_disable();
$XHPROF_ROOT = realpath(dirname(__FILE__)."/perf_stat");
include_once $XHPROF_ROOT . "/xhprof_lib/utils/xhprof_lib.php";
include_once $XHPROF_ROOT . "/xhprof_lib/utils/xhprof_runs.php";
// save raw data for this profiler run using default
// implementation of iXHProfRuns.
$xhprof_runs = new XHProfRuns_Default();
// save the run under a namespace "xhprof_foo"
$run_id = $xhprof_runs->save_run($xhprof_data, "xhprof_${_SERVER["HTTP_HOST"]}_".str_replace('/','_',$_SERVER["REQUEST_URI"]));
Таким образом, если хит оказался дольше 2 секунд, мы его сохраняем во временную папку на сервере. Затем, на машине мониторинга можно обойти сервера и забрать с них трейсы для централизованного анализа (пример для виртуальных хостов в амазоне):
#!/bin/bash
HOSTS=`as-describe-auto-scaling-groups mygroup | grep -i 'INSTANCE' | awk '{ print $2}' | xargs ec2-describe-instances | grep 'INSTANCE' | awk '{print $4}'`
for HOST in $HOSTS ; do
scp -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -p -i /home/trace_loader/.ssh/id_rsa "trace_loader@${HOST}:/tmp/*xhprof*" /my_profiles
done
Теперь у вас есть собранные в одном месте трейсы запросов более 2 секунд. Напишите веб-интерфейс для их просмотра в отсортированном по дате порядке, что займет минут 30. Часть бизнес-процесса готова - каждый трейс является фактически ТЗ на оптимизацию веб-приложения, можно подключать к ним специалистов из разработки.
strace
Иногда профилировщик и лог-файлы не позволяют определить причину проблемы. И на серверах разработки при отладке (XDebug) воспроизвести эту же проблему не получается. Остается одно - понять, что происходит в момент наступления события на боевом сервере. Тут часто неоценимую помощь оказывает трассировщик системных вызовов, например strace. Только не нужно впадать в ступор при виде системных вызовов Linux. Немного усилий и вы поймете идею и сможете отлавливать на боевых серверах самые трудноуловимые ошибки и узкие места.
Примечание: Не стоит смущаться системных вызовов unix, они просты и прямолинейны. Многие объекты в системе представляются в виде файлов и сокетов. По любому вызову можно быстро получить встроенную информацию:
man 2 open man 2 sendto man 2 nanosleep
Если у вас нет этих мануалов, их можно поставить так (на CentOS6):
&yum install man-pages
Посмотреть последнюю документацию по системным вызовам можно также в Интернете или из консоли:
man syscallsПотратив немного времени на понимание как работает PHP на уровне операционной системы, вы получите в руки секретное оружие, позволяющее быстро найти и устранить практически любое узкое место высоконагруженного веб-проекта.
Нужно правильно «прицепить» трассировщик к процессам PHP. Процессов часто запущено много, в разных пулах, они постоянно гасятся и поднимаются (нередко для защиты от утечек памяти задают время жизни процесса например в 100 хитов):
ps aux | grep php root 24166 0.0 0.0 391512 4128 ? Ss 11:47 0:00 php-fpm: master process (/etc/php-fpm.conf) nobody 24167 0.0 0.6 409076 48168 ? S 11:47 0:00 php-fpm: pool www1 nobody 24168 0.0 0.4 401736 30780 ? S 11:47 0:00 php-fpm: pool www1 nobody 24169 0.0 0.5 403276 39816 ? S 11:47 0:00 php-fpm: pool www1 nobody 24170 0.0 1.0 420504 83376 ? S 11:47 0:01 php-fpm: pool www1 nobody 24171 0.0 0.6 408396 49884 ? S 11:47 0:00 php-fpm: pool www1 nobody 24172 0.0 0.5 404476 40348 ? S 11:47 0:00 php-fpm: pool www2 nobody 24173 0.0 0.4 404124 35992 ? S 11:47 0:00 php-fpm: pool www2 nobody 24174 0.0 0.5 404852 42400 ? S 11:47 0:00 php-fpm: pool www2 nobody 24175 0.0 0.4 402400 35576 ? S 11:47 0:00 php-fpm: pool www2 nobody 24176 0.0 0.4 403576 35804 ? S 11:47 0:00 php-fpm: pool www2 nobody 24177 0.0 0.7 410676 55488 ? S 11:47 0:00 php-fpm: pool www3 nobody 24178 0.0 0.6 409912 53432 ? S 11:47 0:00 php-fpm: pool www3 nobody 24179 0.1 1.3 435216 106892 ? S 11:47 0:02 php-fpm: pool www3 nobody 24180 0.0 0.7 413492 59956 ? S 11:47 0:00 php-fpm: pool www3 nobody 24181 0.0 0.4 402760 35852 ? S 11:47 0:00 php-fpm: pool www3 nobody 24182 0.0 0.4 401464 37040 ? S 11:47 0:00 php-fpm: pool www4 nobody 24183 0.0 0.5 404476 40268 ? S 11:47 0:00 php-fpm: pool www4 nobody 24184 0.0 0.9 409564 72888 ? S 11:47 0:01 php-fpm: pool www4 nobody 24185 0.0 0.5 404048 40504 ? S 11:47 0:00 php-fpm: pool www4 nobody 24186 0.0 0.5 403004 40296 ? S 11:47 0:00 php-fpm: pool www4
Чтобы не гоняться за меняющимися ID процессов PHP, можно поставить им временно короткое время жизни:
pm.max_children = 5 pm.start_servers = 5 pm.min_spare_servers = 5 pm.max_spare_servers = 5 pm.max_requests = 100
Затем запустить strace так:
strace -p 24166 -f -s 128 -tt -o trace.log
То есть trace запускается как рутовый процесс и при появлении новых потомков он автоматически начнет отслеживать их тоже.
Теперь желательно в лог файлы PHP начать писать PID процесса, чтобы можно было быстро сопоставить долгий хит из лога с конкретным процессом трейса:
access.log = /opt/php/var/log/www.access.log
access.format = "%R # %{HTTP_HOST}e # %{HTTP_USER_AGENT}e # %t # %m # %r # %Q%q # %s # %f # %{mili}d # %{kilo}M # %{user}C+%{system}C # %p"
Дождёмся когда появится жертва, например долгий хит:
[24-May-2012 11:43:49] WARNING: [pool www1] child 22722, script '/var/www/html/myfile.php' (request: "POST /var/www/html/myfile.php") executing too slow (38.064443 sec), logging - # mysite.ru # Mozilla/5.0 (Windows NT 6.1; WOW64; rv:12.0) Gecko/20100101 Firefox/12.0 # 24/May/2012:11:43:11 +0400 # POST # /var/www/html/myfile.php # # 200 # /var/www/html/myfile.php # 61131.784 # 6656 # 0.03+0.03 # 22722
Трактуем системные вызовы
Системные вызовы - это низкоуровневые «элементарные» операции, которыми программа общается с операционной системой. На них зиждется все IT-мироздание с разными языками программирования и технологиями. Системных вызовов не очень много (аналогично небольшому числу команд процессора и бесчисленному количеству языков и диалектов выше по стеку).
Команды PHP веб-проекта выполняются строго друг за другом в рамках одного процесса. Поэтому в трейсе нужно отфильтровать процесс подозрительного хита - 22722 из примера выше:
cat trace.log | grep '22722' | less
Время хита известно из лога, осталось посмотреть что творилось при построении страницы и почему висело так долго (трейс немного отредактирован). Видны запросы к БД и ответы:
24167 12:47:50.252654 write(6, "u\0\0\0\3select name, name, password ...", 121) = 121 24167 12:47:50.252915 read(6, "pupkin, 123456"..., 16384) = 458
Обращения к файлам:
24167 12:47:50.255299 open("/var/www/html/myfile.php", O_RDONLY) = 7
Взаимодействие с memcached:
24167 12:47:50.262654 sendto(9, "add mykey 0 55 1\r\n1\r\n", 65, MSG_DONTWAIT, NULL, 0) = 65 24167 12:47:50.263151 recvfrom(9, "STORED\r\n", 8192, MSG_DONTWAIT, NULL, NULL) = 8 ... 24167 12:47:50.282681 sendto(9, "delete mykey 0\r\n", 60, MSG_DONTWAIT, NULL, 0) = 60 24167 12:47:50.283998 recvfrom(9, "DELETED\r\n", 8192, MSG_DONTWAIT, NULL, NULL) = 9
И вот видим, например, почему хит завис:
22722 11:43:11.487757 sendto(10, "delete mykey 0\r\n", 55, MSG_DONTWAIT, NULL, 0) = 55
22722 11:43:11.487899 poll([{fd=10, events=POLLIN|POLLERR|POLLHUP}], 1, 1000) = 1 ([{fd=10, revents=POLLIN}])
22722 11:43:11.488420 recvfrom(10, "DELETED\r\n", 8192, MSG_DONTWAIT, NULL, NULL) = 9
22722 11:43:11.488569 sendto(10, "delete mykey2 0\r\n", 60, MSG_DONTWAIT, NULL, 0) = 60
22722 11:43:11.488714 poll([{fd=10, events=POLLIN|POLLERR|POLLHUP}], 1, 1000) = 1 ([{fd=10, revents=POLLIN}])
22722 11:43:11.489215 recvfrom(10, "DELETED\r\n", 8192, MSG_DONTWAIT, NULL, NULL) = 9
22722 11:43:11.489351 close(10) = 0
22722 11:43:11.489552 gettimeofday({1337845391, 489591}, NULL) = 0
22722 11:43:11.489695 gettimeofday({1337845391, 489727}, NULL) = 0
22722 11:43:11.489855 nanosleep({0, 100000}, NULL) = 0
22722 11:43:11.490155 nanosleep({0, 200000}, NULL) = 0
22722 11:43:11.490540 nanosleep({0, 400000}, NULL) = 0
22722 11:43:11.491121 nanosleep({0, 800000}, NULL) = 0
22722 11:43:11.492103 nanosleep({0, 1600000}, NULL) = 0
22722 11:43:11.493887 nanosleep({0, 3200000}, NULL) = 0
22722 11:43:11.497269 nanosleep({0, 6400000}, NULL) = 0
22722 11:43:11.503852 nanosleep({0, 12800000}, NULL) = 0
22722 11:43:11.516836 nanosleep({0, 25600000}, NULL) = 0
22722 11:43:11.542620 nanosleep({0, 51200000}, NULL) = 0
22722 11:43:11.594019 nanosleep({0, 102400000}, NULL) = 0
22722 11:43:11.696619 nanosleep({0, 204800000}, NULL) = 0
22722 11:43:11.901622 nanosleep({0, 409600000}, NULL) = 0
22722 11:43:12.311430 nanosleep({0, 819200000},
22722 11:43:13.130867 <... nanosleep resumed> NULL) = 0
22722 11:43:13.131025 nanosleep({1, 638400000},
22722 11:43:14.769688 <... nanosleep resumed> NULL) = 0
22722 11:43:14.770104 nanosleep({1, 638400000},
22722 11:43:16.408860 <... nanosleep resumed> NULL) = 0
22722 11:43:16.409048 nanosleep({1, 638400000},
22722 11:43:18.047808 <... nanosleep resumed> NULL) = 0
22722 11:43:18.048103 nanosleep({1, 638400000},
22722 11:43:19.686947 <... nanosleep resumed> NULL) = 0
22722 11:43:19.687085 nanosleep({1, 638400000},
22724 11:43:20.227224 <... lstat resumed> 0x7fff00adb080) = -1 ENOENT (No such file or directory)
22722 11:43:21.325824 <... nanosleep resumed> NULL) = 0
22722 11:43:21.326219 nanosleep({1, 638400000},
22722 11:43:22.964830 <... nanosleep resumed> NULL) = 0
22722 11:43:22.965126 nanosleep({1, 638400000},
22722 11:43:24.603692 <... nanosleep resumed> NULL) = 0
22722 11:43:24.604117 nanosleep({1, 638400000},
22722 11:43:26.250371 <... nanosleep resumed> NULL) = 0
22722 11:43:26.250580 nanosleep({1, 638400000},
22722 11:43:27.889372 <... nanosleep resumed> NULL) = 0
22722 11:43:27.889614 nanosleep({1, 638400000},
22722 11:43:29.534127 <... nanosleep resumed> NULL) = 0
22722 11:43:29.534313 nanosleep({1, 638400000},
22722 11:43:31.173004 <... nanosleep resumed> NULL) = 0
22722 11:43:31.173273 nanosleep({1, 638400000},
22722 11:43:32.812113 <... nanosleep resumed> NULL) = 0
22722 11:43:32.812531 nanosleep({1, 638400000},
22722 11:43:34.451236 <... nanosleep resumed> NULL) = 0
22722 11:43:34.451554 nanosleep({1, 638400000},
22722 11:43:36.090229 <... nanosleep resumed> NULL) = 0
22722 11:43:36.090317 nanosleep({1, 638400000},
22724 11:43:36.522722 fstat(12,
22723 11:43:36.622833 <... gettimeofday resumed> {1337845416, 622722}, NULL) = 0
22722 11:43:37.729696 <... nanosleep resumed> NULL) = 0
22722 11:43:37.730033 nanosleep({1, 638400000},
22724 11:43:39.322722 gettimeofday(
22722 11:43:39.368671 <... nanosleep resumed> NULL) = 0
22722 11:43:39.368930 nanosleep({1, 638400000},
22722 11:43:41.007574 <... nanosleep resumed> NULL) = 0
22722 11:43:41.007998 nanosleep({1, 638400000},
22722 11:43:42.646895 <... nanosleep resumed> NULL) = 0
22722 11:43:42.647140 nanosleep({1, 638400000},
22720 11:43:43.022722 fstat(12,
22720 11:43:43.622722 munmap(0x7fa1e736a000, 646) = 0
22722 11:43:44.285702 <... nanosleep resumed> NULL) = 0
22722 11:43:44.285973 nanosleep({1, 638400000},
22722 11:43:45.926593 <... nanosleep resumed> NULL) = 0
22722 11:43:45.926793 nanosleep({1, 638400000},
22722 11:43:47.566124 <... nanosleep resumed> NULL) = 0
22722 11:43:47.566344 nanosleep({1, 638400000},
22722 11:43:49.205103 <... nanosleep resumed> NULL) = 0
22722 11:43:49.205311 nanosleep({1, 638400000},
22719 11:43:49.440580 ptrace(PTRACE_ATTACH, 22722, 0, 0
Сначала шли обращения к memcached: запись/чтение сокета 10, затем сокет был успешно закрыт (22722 11:43:11.489351 close(10) = 0), затем в коде был вызов nanosleep в цикле и условие выхода из цикла не срабатывало по причине предварительно закрытого сокета. В результате причину удалось быстро определить и поправить код.
Стабилизируем PHP на бою
Введение
Веб-проект на PHP, добавляются фичи, клиенты довольны. Но нагрузка постоянно растет. В один прекрасный день начинают появляться загадочные ошибки, которые программисты не знают как исправить. "Ломается" серверный софт, например связка Apache-PHP - а клиент получает в ответ на запрос страницу о регламентных работах.
Достаточно часто встречаются проекты, которые сталкиваются с подобным классом "ошибок" серверного софта, и в команде не всегда знают, что делать. В логе Apache часто появляются сообщения о нарушении сегментации (segmentation fault). Клиенты получают страницу об ошибке, а веб-разработчик с сисадмином ломают себе голову, играются с разными версиями PHP/Apache/прекомпилятора, собирают PHP из исходников с разными опциями снова и снова. А это баги не PHP, а их кода.
Лог ошибок веб-сервера
[Mon Oct 01 12:32:09 2012] [notice] child pid 27120 exit signal Segmentation fault (11)
В данном случае бесполезно искать подробную информацию в логе ошибок PHP - ведь "упал" сам процесс, а не скрипт. Если заранее не сделать на NGINX симпатичную страничку о регламентных работах, то клиенты увидят аскетичную ошибку 50*.
Вспомним теорию. Что такое signal? Это средство, которое операционная система использует, чтобы сказать процессу, что он не прав. Например, берет и, нарушая законы математики, делит на 0, или насильственными действиями вызывает переполнение стека. В данном случае мы видим сигнал с номером 11 и названием SIGSEGV. Список сигналов можно посмотреть, выполнив kill -l.
В чём причина?
Теперь найдем причину, за что же убили процесс PHP? Для этого нужно настроить создание дампа памяти процесса в момент "убийства" или coredump. Как только в следующий раз процесс будет убит операционной системой, ядром будет создан файл. Место размещение и название файла можно настроить. Если вы в консоли, просто наберите man 5 core.
Например, можно складывать файлы в папочку так:
echo "/tmp/httpd-core.%p" > /proc/sys/kernel/core_pattern
Примечание: Если ничего не задать, система создаст файл с именем core.#process_number# в рабочей директории процесса. Только проследите, чтобы процесс apache-PHP имел туда право записи.
Однако, скорее всего, в вашей системе отключена генерация coredump-файлов. Ее можно включить, вставив в начало скрипта запуска веб-сервера строку:
ulimit -с unlimited
Или, чтобы сделать настройку постоянной, отредактировать файлик /etc/security/limits.conf. Туда можно вставить:
apache - core -1
Примечание: Подробности по формату файла: man limits.conf.
Необходимо также для Apache настроить папку для coredump-файлов (/etc/httpd/conf/httpd.conf):
CoreDumpDirectory /tmp
Перезапустите Apache:
service httpd restart
Тестируем и вручную завершаем процесс:
ps aux | grep httpd … kill -11 12345
Проверка: в файле /var/log/httpd/error_log должно быть что-то вроде такого:
[Mon Oct 01 16:12:08 2012] [notice] child pid 22596 exit signal Segmentation fault (11), possible coredump in /tmp
В /tmp теперь видим файл с названием типа /tmp/httpd-core.22596. Вы научились получать дамп памяти завершившегося процесса. Теперь ждем, когда процесс будет завершён естественным образом.
Как толковать coredump?
Примечание: Ошибочно думать, что:
- если PHP собрана без отладочных символов (ключик
--enable-debug, -gдля gcc при компиляции), то потеряется много полезной информации. Даже если PHP собран из исходников без этой опции, но исходники лежат рядом, этого может хватить для анализа. - отладочная сборка влияет на производительность и потребляемую процессом память (memory footprint). Не влияет, а лишь увеличивается размер исполняемого файла. Поэтому, если не сможете разобраться в причине ошибки без отладочной сборки - попросите сисадмина собрать модуль PHP с отладочными символами.
Открыть coredump можно утилитой gdb. Обычно открывают coredump так:
gdb путь_к_выполняемому_файлу_веб-сервера путь_к_coredump
Разобраться, как работает отладчик, не займет много времени. Можно за пару часиков поглотить один из самых занимательных учебников, а можно попросить это сделать сисадмина. Все уважающие себя разработчики на C в unix умеют пользоваться этим отладчиком. Но, к сожалению, их может не быть в вашей команде. И есть еще одно неприятное "НО".
Отладка PHP в gdb
Компилированный в байткод скрипт PHP это не совсем программа на C. Нужно, правда совсем немного, разобраться во внутренностях движка Zend. А именно - нужно найти в трейсе последний вызов функции execute, перейти в этот frame стека и исследовать локальные переменные (op_array), а также заглянуть в глобальные переменные движка Zend:
(gdb) frame 3 #3 0x080f1cc4 in execute (op_array=0x816c670) at ./zend_execute.c:1605 (gdb) print (char *)(executor_globals.function_state_ptr->function)->common.function_name $14 = 0x80fa6fa "pg_result_error" (gdb) print (char *)executor_globals.active_op_array->function_name $15 = 0x816cfc4 "result_error" (gdb) print (char *)executor_globals.active_op_array->filename $16 = 0x816afbc "/home/yohgaki/php/DEV/segfault.php"
В op_array можно запутаться, поэтому полезна команда просмотра типа этой структуры:
(gdb) ptype op_array
type = struct _zend_op_array {
zend_uchar type;
char *function_name;
zend_class_entry *scope;
zend_uint fn_flags;
union _zend_function *prototype;
zend_uint num_args;
zend_uint required_num_args;
zend_arg_info *arg_info;
zend_bool pass_rest_by_reference;
unsigned char return_reference;
zend_uint *refcount;
zend_op *opcodes;
zend_uint last;
zend_uint size;
zend_compiled_variable *vars;
int last_var;
int size_var;
zend_uint T;
zend_brk_cont_element *brk_cont_array;
zend_uint last_brk_cont;
zend_uint current_brk_cont;
zend_try_catch_element *try_catch_array;
int last_try_catch;
HashTable *static_variables;
zend_op *start_op;
int backpatch_count;
zend_bool done_pass_two;
zend_bool uses_this;
char *filename;
zend_uint line_start;
zend_uint line_end;
char *doc_comment;
zend_uint doc_comment_len;
void *reserved[4];
} *
Процесс отладки заключается в хождении между фреймами стека (frame N), переходе в каждый вызов функции execute и исследовании ее локальных аргументов (print name, ptype name). Чем меньше номер фрейма, тем вы глубже. Иногда полезно зайти в гости в экстеншн PHP и посмотреть, где произошла ошибка и почему (хотя бы попытаться понять причину).
(gdb) frame #номер# (gdb) print op_array.function_name $1 = 0x2aaab7ca0c10 "myFunction" (gdb) print op_array.filename $2 = 0x2aaab7ca0c20 "/var/www/file.php"
Если разбираться во внутренностях движка Zend особого времени нет, то просто запомните, что переходя между фреймами стека вызовов с помощью команды frame #N#, нужно смотреть только определенные элементы этой структуры, и вы точно сможете установить в каком файле PHP была вызвана функция PHP, какую функцию она вызвала и т.п. Так можно добираться до причины Segmentation Fault или другой ошибки, "убившей" процесс. И объясните программистам в чем причина, и они ее поправят.
Частые причины ошибок
Ошибки можно свести в группы:
- Проблемы в расширениях PHP. В этом случае либо отключите расширение, либо попробуйте поиграть его настройками. Вы точно знаете, что проблема в нем, дело за малым.
- Проблема с рекурсией, стеком. Ошибки, при которых функция библиотеки, например,
pcre, входит в рекурсию и вызывает себя несколько тысяч раз. Можно либо настроить параметры библиотеки или добавить процессу побольше стека (/etc/init.d/httpd):ulimit -s «ставим значение больше»
А текущее значение можно посмотреть командой:ulimit -a
Справка по командеman ulimit, далее ищем ulimit. - Проблемы в ядре PHP - сообщите разработчикам PHP.
Отладка запущенного процесса
Если вы не можете получить coredump, то можно подключиться к запущенному процессу и изучить его. Пока вы внутри процесса, его выполнение приостанавливается (ps aux | grep apache | grep 'T ', Он будет в состоянии трейсинга.). Когда покинете его, он снова продолжит выполняться. Подключиться можно так:
gdb -p ид_процесса
Чеклист
Составим чеклист для менеджера для борьбы с загадочными серверными ошибками, в которых не могут разобраться ни веб-разработчики, ни сисадмины:
- Включить сбор coredump-файлов на сервере (сисадмин)
- При необходимости пересобрать Apache-PHP с отладочными символами (сисадмин)
- С помощью gdb исследовать причину появления ошибки (сисадмин с веб-разработчиком)
- Принять меры по ее устранению или снижению частоты появления: поменять настройки, обновить софт, написать в багтрекер, отключить расширение PHP и т.п.
Конфигурации веб-кластера для решения практических задач
Конфигурации веб-кластера
Использование веб-кластерных технологий позволяет иметь несколько серверов веб-приложений, несколько баз данных, несколько memcached-серверов (на примере 1С-Битрикс: Веб-кластер):
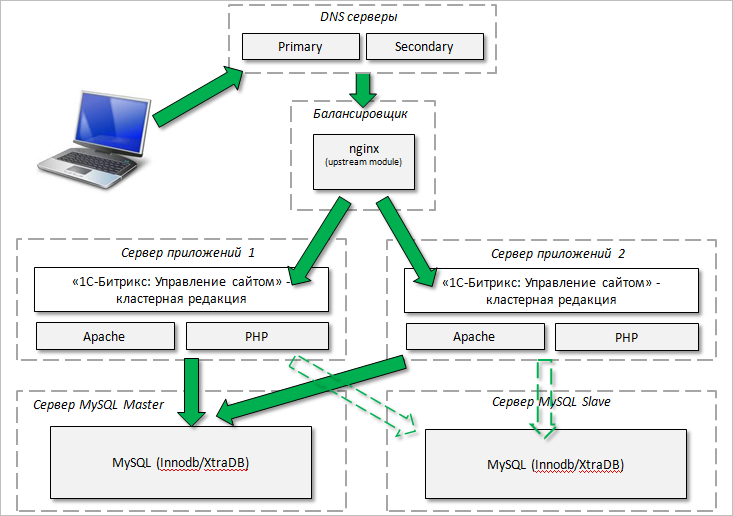
Кластеризация составляющих сайта, благодаря балансировке нагрузки между нодами кластера, позволяет минимизировать время простоя системы. Кроме того, веб-кластер позволяет подключить одну из нод в качестве бэкап-сервера и отменить использование данной ноды для распределения нагрузки от посещений сайта.
Помимо аппаратных, существуют и программные решения балансировки нагрузки между серверами:
- Load Balancer (Amazon Web Services)
- механизм round robin DNS
- http-сервер nginx
Для определения наиболее подходящей конфигурации необходимо проанализировать характер нагрузки на веб-приложение с помощью различных инструментов мониторинга (munin, zabbix, apache server-status).
Высокая нагрузка на процессоры
Высокая нагрузка на процессоры, невысокая/средняя нагрузка на СУБД, редкая смена контента.
Подключенные к веб-кластеру ноды заводятся под балансировщик нагрузки, в результате чего по ним будет распределена нагрузка на процессоры.
Примечание: если в веб-кластере подключен кэш, то для дополнительного снижения нагрузки на процессоры рекомендуется на каждой ноде запустить сервер memcached, за счет чего единожды созданный на одной ноде кэш будет использоваться другими нодами.
Для синхронизации контента подойдет csync2, nfs/cifs-сервер на одной из нод веб-кластера.
Высокая растущая нагрузка на СУБД
Снизить нагрузку на master-базу путем добавления slave-нод. С учетом их мощности распределить между ними нагрузку с помощью параметра Процент распределения нагрузки.
При дальнейшем увеличении нагрузки на СУБД:
- т.к. master-сервер будет использоваться преимущественно для записи, путем настройки параметров его нужно оптимизировать для записи, а slave-ноды - для чтения;
- Добавлять slave-ноды.
Большой объем часто перестраиваемого кэша
Большой объем часто перестраиваемого кэша, контент постоянно обновляется.
Для эффективной работы с кэшем запускаем на каждой ноде сервер memcached и выделяем каждому по несколько GB памяти (в зависимости от требований приложения).
Для синхронизации контента рекомендуется использовать выделенный nfs/cifs-сервер, либо ocfs/gfs или аналоги.
Модуль Веб-кластер в Bitrix Framework
Возможности
Веб-кластер от 1С-Битрикс позволяет использовать:
- вертикальный шардинг (вынесение модулей на отдельные серверы MySQL):

- репликацию MySQL и балансирование нагрузки между серверами:
- распределенный кеш данных (memcached). Для запуска сервера memcached на 1С-Битрикс: Веб-окружение (Linux) необходимо выполнить команды:
# chkconfig memcached on # service memcached start
- централизованное хранение сессий в базе данных (Настройки > Веб-кластер > Сессии):
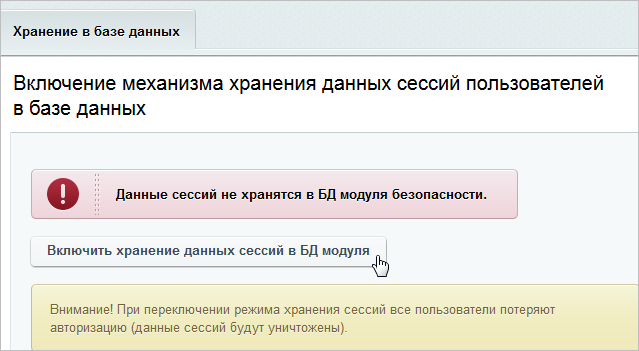
Список веб-серверов
Каждый веб-сервер кластера можно добавить в общий веб-кластер для мониторинга в административном разделе Настройки > Веб-кластер > Группа серверов > Веб-сервера:
На каждом из серверов необходимо настроить страницу, на которой будет отображаться статистика веб-сервера Apache (с помощью модуля mod_status). Если используется 1С-Битрикс: Веб-окружение, необходимо:
- добавить в конфигурационный файл Apache (/etc/httpd/conf/httpd.conf):
ExtendedStatus On SetHandler server-status Order allow,deny Allow from 10.0.0.1 Allow from 10.0.0.2 Deny from All Location- адрес, по которому будет доступна статистика;- директивы
Allow fromопределяют, с каких ip-адресов статистика будет доступна для просмотра.
- перечитать конфигурационные файлы
Apacheс помощью команды:# service httpd reload
- в первой секции server конфигурационного файла /etc/nginx/nginx.conf добавить:
Location~ ^/server-status$ { proxy_pass http://127.0.0.1:8888; } - Перечитать конфигурационные файлы nginx с помощью команды:
# service nginx reload
- в файл /home/bitrix/www/.htaccess после строки:
RewriteCond %{REQUEST_FILENAME} !/bitrix/urlrewrite.php$добавьте:RewriteCond %{REQUEST_URI} !/server-status$
После внесения всех необходимых изменений, адрес server-status'а можно добавить в конфигурацию кластера.
Обеспечение производительности
Обеспечение производительности проекта в период его эксплуатации требует постоянного внимания. Проблемы могут возникать разные, но в любом случае их можно отнести к проблемам на клиентской или серверной стороне.
Проблемы на клиентской стороне
Тестирование локально, проведённое при разработке проекта, - это хорошо, но далеко не всё. Нужны замеры в реальных условиях. Можно собирать статистику: по скорости рендеринга javascript в браузере клиента, DNS резолвингу, TCP соединениям и вообще, всё, что можно собрать внутри браузера клиента. С помощью Pinba эта статистика может выводиться в удобном виде для анализа. Pinba сохраняет данные по онлайн агрегации хитов за последние 15 минут (по умолчанию).
|
Пример регистрации в pinba браузерной статистики из Navigation Timing API
|
|---|
pinba_timer_add(
array(
'jstimer'=>'responseEnd-responseStart',
'jshost'=>$jshost,
'jsip'=>$_SERVER["REMOTE_ADDR"],
'jsua'=>$_SERVER["HTTP_USER_AGENT"],
),
(intval($_REQUEST["responseEnd"]) - intval($_REQUEST["responseStart"]))/1000
);
pinba_hostname_set( strval(substr($_REQUEST["host"],0,128)) );
pinba_script_name_set( strval(substr($script,0,128)) );
pinba_request_time_set($timef);
|
Все эти данные можно получить средствами js внутри браузера клиента и передать в MySQL хранилище Pinba:

Одним запросом в Pinba можно увидеть у каких клиентов сейчас, в каких подсетках тормозит DNS, тормозит TCP или рендер тормозит и так далее. Разработчик одним взглядом видит то, что видят сейчас видит обобщённый клиент его проекта.
Далее из Pinba можно можно выбрать данные:
Рендер у Клиентов:
select avg(round(timer_value/req_count,3)) from bx24_cps_js_performance_host where tag2_value='domContentLoadedEventStart-responseStart';
Рендер в браузерах:
select substring(tag2_value,1,100) as ua, avg(round(timer_value/req_count,3)) as avg_time,count(*) from bx24_cps_js_performance_jstimer_ua where tag1_value='domContentLoadedEventStart-responseStart' group by ua order by count(*) desc limit 10;
DNS-скорость:
&select tag2_value, avg(round(timer_value/req_count,3)) as avg_ip_time, count(*) from bx24_cps_js_performance_jstimer_ip where tag1_value='domainLookupEnd-domainLookupStart' group by tag2_value order by count(*) desc limit 20;
Топ коннектов:
mysql> select tag2_value, avg(round(timer_value/req_count,3)) as avg_ip_time from bx24_cps_js_performance_jstimer_ip where tag1_value='connectEnd-connectStart' group by tag2_value order by avg_ip_time desc limit 20; +-----------------+-----------+ | 176.60.226.9 | 7.6150000 | | 119.32.156.237 | 3.9420000 | | 79.133.133.97 | 3.2835000 | | 78.138.133.2 | 2.4352500 | | 195.38.55.178 | 1.9980000 |
Примечание: Аналогично можно мерить отдачу из CDN.
Информация, получаемая таким образом должна приводить к выводам. Такому анализу и нужно научиться. Можно анализировать данные вручную, а можно написать тесты и получать смс по критичным результатам этих тестов. Такие уведомления позволят реагировать на проблемы быстрее. Ставьте тесты на определённые пороговые значения, рисуйте графики и вы осчастливите клиента.
Научитесь быстро локализовывать источник проблем, это могут быть:
- Проблемы провайдера (анализ TCP коннекта, DNS)
- Проблемы сети: временные «тормоза» (congestion) сети
- Проблемы клиента: тормозит браузер клиента (играет в WOT в соседнем окне)
- Проблема в проекте
Проблемы на серверной стороне
Если на клиентской стороне все в порядке, то реальная проблема на серверной стороне. Тут возможны две группы причин:
- Медленная отдача статики;
- Медленная генерация динамического контента.
Диагностика проблем со статикой - самое простое. Возможно:
- Завис сервер (смотрим логи).
- Резервное копирование запущено не вовремя.
- Канал забит до сайта (редкая ситуация). Смотреть логи, графики.
- Проблемы с машиной: память/диски - объем и нагрузка. Мерять iostat и другими утилитами.
- Использование local storage, на котором есть еще 50 проектов.
Решение проблем статики
Оптимально - использование CDN. Не, если в силу каких-то причин это неприемлемо, можно вынести статику на отдельный домен, что позволит скачивать статику в несколько потоков. Либо перенести статику на отдельный сервер(ы) с быстрыми дисками.
И обязательный мониторинг, позволяющий ловить проблемы сразу по их возникновению.
Очень редко, но бывает, что статика "пробивается" через двухуровневую конфигурацию на Apache/PHP-FPM, то есть NGNIX вместо того, чтобы отдавать статику, начинает передавать запросы на Apache. Возможные причины такого явления - неправильная вёрстка, неправильная настройка NGNIX. Для локализации проблемы можно использовать тесты (apachetop). Также проблему можно увидеть на странице /server-status сервера Apache.
500-ые ошибки
Эти ошибки берутся из-за back-end'а. Такие ошибки нужно по возможности прятать от клиента. Поэтому сделайте красивую страницу с уведомлением пользователей и разбирайтесь с проблемой: смотрите логи.
База данных
При проблемах с Базой данных основной инструмент диагностики - логи. Постоянный мониторинг тестами Percona XtraDB, например:

Данные выводятся в виде общей статистики, сразу видно когда начались проблемы:

При больших объёмах данных рекомендуется познакомиться с CAP, NoSQL, изучить репликацию, посмотрите про Galera.
Сама по себе БД не тормозит. Тормозят запросы, которые задаются разработчиком. Ищите решение в них.
PHP
Если тормозит PHP, для выявления проблем используйте:
- Графики Pinba (скорость выполнения страницы, время system time, user time, PHP)
- php-fpm slow log
- gdb, strace
- XHProf
- Анализ логов приложения, распределения.
Полезно измерять не только среднее значение показателя, но и оценивать распределение значений. На гистограмме времени отработки или использования памяти можно увидеть много интересного: например 95% быстрых хитов и 5% очень очень медленных. Не менее полезен анализ распределения по процентилям.
Материалы по теме
- Профилирование нагрузки на файловую систему с помощью iostat и gnuplot Статья на habrahabr.ru
Блокировки сессий в веб-проектах
Введение
В связи с бурным ростом и усложнением Front-End аяксами, табами в браузере и тому подобным, все чаще проявляется проблема блокировки сессий во время эксплуатации сайтов на PHP. PHP по умолчанию создает для сессии файл и процесс эксклюзивно его блокирует. Остальные процессы, пытающиеся открыть сессию - выстраиваются в очередь. Не всегда логика приложения, особенно если она сложная, позволяет эффективно ограничить время блокировки конкурирующих за сессию процессов. Ситуация усугубляется еще тем, что 3-5 подобных клиентов способны быстро забить зависшими и простаивающими в ожидании процессами PHP-worker'ы и сайт "повисает".
К сожалению, разработчики/сисадмины не всегда могут сразу понять, что дело в блокировке сессии — и ищут проблемы в других частях проекта, теряя время.
Диагностика
Рассмотрим, что происходит внутри операционной системы, если одновременно попытаться открыть в браузере (можно в разных вкладках) один засыпающий файл и несколько просто стартующих сессию скриптов:
<?php session_start(); sleep(30);// только для одного скрипта ?>
Страницы будут дожидаться освобождения сессии (30 секунд) и займет это много времени, при этом будут забиты слоты веб-сервера. Примерно то же самое случается, когда AJAX запускает в сессии веб-клиента тяжелую задачу и остальные AJAX и другие элементы интерфейса зависают в ожидании (либо когда открывается несколько вкладок под одной авторизацией).
Процессы веб-сервера, в данном случае httpd, но то же самое происходит и с PHP-FPM — пытаются эксклюзивно заблокировать файл сессии, что видим с помощью lsof:
lsof -n | awk '/sess_/' httpd 7079 nobody 52uW REG 8,1 2216 809832 /tmp/sess_f629a13b4b0920a21042c86d17f4a6a6 httpd 10406 nobody 52u REG 8,1 2216 809832 /tmp/sess_f629a13b4b0920a21042c86d17f4a6a6 httpd 10477 nobody 52u REG 8,1 2216 809832 /tmp/sess_f629a13b4b0920a21042c86d17f4a6a6 httpd 10552 nobody 52u REG 8,1 2216 809832 /tmp/sess_f629a13b4b0920a21042c86d17f4a6a6 httpd 11550 nobody 52u REG 8,1 2216 809832 /tmp/sess_f629a13b4b0920a21042c86d17f4a6a6 httpd 11576 nobody 52u REG 8,1 2216 809832 /tmp/sess_f629a13b4b0920a21042c86d17f4a6a6
Обратите внимание на 4 колонку. Число - это номер дескриптора файла в процессе, а дальше - тип блокировки. "uW" - веб-сервер заблокировал файл эксклюзивно для записи. Остальные - в ожидании. Как только процесс 7079 закончит свою работу, блокировку "uW" возьмет другой процесс. В это время, понятно, выстраивается очередь и веб-интерфейс заметно тормозит. Если несколько процессов заблокируют сессию на единицы секунды - интерфейс вообще "замрёт".
Посмотрим теперь с другой стороны, чем занимаются процессы:
ps -e -o pid,comm,wchan=WIDE-WCHAN-COLUMN | grep httpd 7079 httpd - 10406 httpd flock_lock_file_wait 10477 httpd flock_lock_file_wait 10552 httpd flock_lock_file_wait 11550 httpd flock_lock_file_wait 11576 httpd flock_lock_file_wait
Во второй колонке видим, что все, кроме одного, заняты в функции flock_lock_file_wait.
strace -p 10406 Process 10406 attached - interrupt to quit flock(52, LOCK_EX)
Они заняты в системном вызове c запросом эксклюзивной блокировки.
LOCK_EX Place an exclusive lock. Only one process may hold an
exclusive lock for a given file at a given time.
Практика
Чтобы постоянно отслеживать на веб-серверах появление такого "паровозика", забивающего PHP-воркеры, можно использовать скрипт, написанный на AWK:
/sess_/ {
load_sessions[$9]++;
if (load_sessions[$9]>max_sess_link_count){
max_sess_link_count = load_sessions[$9];
max_sess_link_name = $9;
};
if ($4 ~ /.*uW$/ ){ locked_id[$9]=$2 };
}
END {
print max_sess_link_count, max_sess_link_name,locked_id[max_sess_link_name];
if (locked_id[max_sess_link_name] && max_sess_link_count>3) {
# r=system("kill "locked_id[max_sess_link_name]);
# if (!r) print "Locking process "locked_id[max_sess_link_name]" killed"
system("ls -al "max_sess_link_name);
}
}
Запускается так:
lsof -n | awk -f sess_view.awk 5 /tmp/sess_f629a13b4b0920a21042c86d17f4a6a6 24830
Скрипт отображает длину "паровозика" и процесс — создающий затор.
Понятно, что на реальном сайте не должно быть подобных проблем - нужно сделать все (переделать логику работы с сессией, написать кастомные хандлеры PHP, принять другие меры), чтобы у клиента по возможности ничего не тормозило, а вы как системный администратор - спали крепко и долго.
Если по каким-либо причинам переделка логики и прочие меры предпринять сложно (невозможно), то можно раскомментировать kill и уничтожать процессы веб-сервера, создающие коллапс. Но правильнее с собранной подобным образом через cron в файлик статистикой обратиться к разработчикам и договориться о рефакторинге.
Как можно хранить и раздавать большие объёмы контента
Введение
Объем данных многих популярных сайтов быстро растет. Кроме проблемы резервного копирования возникает и проблема быстрой раздачи контента клиентам, чтобы все могли его, контент, качать на высокой скорости. Для системного администратора задача даже редкого, ежедневного резервного копирования такого объема файлов крайне сложна, а менеджер веб-проекта просыпается в холодном поту от мысли о предстоящей профилактике дата-центра на 6 часов.
В статье хочу разобрать частые кейсы дешевого и дорогого решения данной задачи — от простого к сложному. В конце статьи расскажу как задача решена в нашем флагманском продукте — всегда полезно сравнивать opensource-решения с коммерческими, мозгам нужна гимнастика.Двухуровневая конфигурация Front-End и Back-End
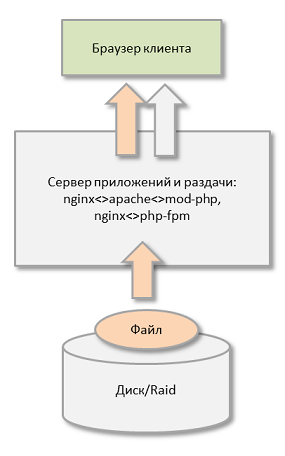 | NGINX или аналогичный обратный прокси в режиме двухуровневой конфигурации позволяет эффективно раздавать файлы, особенно по медленным каналам. При этом серьезно снижается нагрузка на сервер и повышается в целом производительность веб-приложения: NGINX раздает кучу файлов, Apache или PHP-fpm обрабатывают запросы к серверу приложений. Такие веб-приложения живут хорошо, пока объем файлов не увеличивается до, скажем десятков гигабайт. Когда несколько сотен клиентов начинают одновременно скачивать файлы с сервера, а памяти для кэширования файлов в ОЗУ недостаточно: диск, а потом и RAID просто умрёт. |
Сервер статики
Примерно на этом этапе умирания первого RAID нередко начинают сначала фиктивно, затем физически раздавать статические файлы с другого, желательно не отдающего много лишних cookies, домена. Всем известно, что браузер клиента имеет ограничение на число коннектов в одному домену сайта, и когда сайт вдруг начинает отдавать себя с двух и более доменов, то скорость его загрузки в браузер клиента существенно возрастает.
Чтобы более эффективно раздавать статику с разных доменов, ее выносят на отдельный сервер(а) статики. Полезно на этом сервере использовать режим кэширования NGINX и "быстрый" RAID (чтобы побольше клиентов требовалось для постановки диска «на колени»).
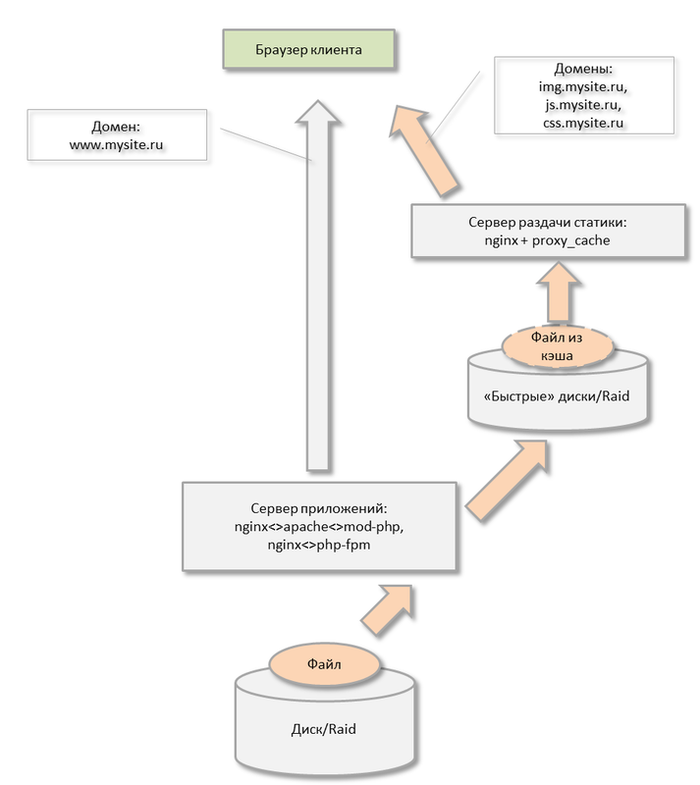
Делают домены что-то типа:
www.mysite.ru
img.mysite.ru
js.mysite.ru
css.mysite.ru
download.mysite.ru
и т.п.
CDN
При дальнейшей работе веб-проекта организаторы начинают понимать, что раздавать из своего дата-центра даже с очень быстрых дисков или даже SAN - не всегда эффективно:
- Ценный клиент начал качать файл с московского сервера из Владивостока по узкому каналу.
- Случилась беда, обрыв питания прервал связь 10000 клиентов, качающих новый дистрибутив.
- Наоборот, мог случиться такой наплыв клиентов, что стало не хватать серверной мощности раздавать одновременно столько статики, либо уже каналы загружены до предела.
Становится понятно, что нужно быть как можно ближе к клиенту и отдавать клиенту столько статики, сколько он хочет, на максимально возможной быстрой скорости, а не сколько мы можем отдавать со своего сервера(ов). Эти задачи в последнее время начала эффективно решать технология CDN.

"Вертикальное" масштабирование раздачи статики
Веб-проект постепенно распухает. Копится все больше и больше файлов для раздачи. Они хранятся централизованно в одном ДЦ на одном или группе серверов. Делать резервную копию такого количества файлов становится все дороже, дольше и сложнее. Полный бэкап делается неделю, приходится делать снепшоты, инкременты и прочие вещи, увеличивающие риск потери данных.
Что будет, если:
- Рассыпятся диски на файловом хранилище (рейд10 может умереть, забрав с собой сразу пару зеркальных дисков и это - случается не очень редко) и придется доставать файлы из резервной копии в течении двух-трех недель.
- В дата-центре вас с утра обрадовали сообщением, что диски рассыпались, а ваши бэкапы в результате ошибки софта - безвозвратно повреждены (такое в Амазоне с "1С-Битрикс" один раз произошло).
- Пройдет рекламная акция и начнется наплыв клиентов из Дальнего Востока или из Европы - и вы не справитесь с эффективной раздачей такого количества статики.

В инфраструктуру вложено уже столько денег, а риски, причем немалые, всё ещё остаются.
Распределенная файловая система
Для проекта с большим бюджетом есть вариант развернуть в нескольких дата-центрах свою распределенную файловую систему. Вариант достаточно сложный для реализации и администрирования, но если есть профессионалы, то вполне реализуем.

Виртуальная файловая система
Одним из наиболее эффективных решений является использование возможностей известных облачных провайдеров. Они дают возможность хранить неограниченный объем ваших файлов в облаке с очень высокой надежностью по очень привлекательным, особенно при большом объеме данных, ценам. Провайдеры организовали на своих мощностях описанные выше распределенные файловые системы. Эти системы - высоконадежные и размещенные в нескольких дата-центрах, разделенных территориально. Более того, эти сервисы, как правило, тесно интегрированы в сеть CDN данного провайдера. Т.е. вы будете не просто удобно и дешево хранить свои файлы, но и их максимально удобно для клиента раздавать.
Для этого нужно настроить на своем веб-проекте прослойку или виртуальную файловую систему (или аналог облачного диска). Среди бесплатных решений можно выделить FUSE-инструменты (для linux) типа s3fs.

Чтобы перевести текущее веб-приложение на эту дешевую и очень эффективную с точки зрения бизнеса технологию, нужно внести ряд изменений в существующий код и логику приложения.
Модуль "Облачные хранилища"
Последний вариант реализован "из коробки" в модуле Облачные хранилища, который позволяет перенести хранение файлов вместо локального сервера веб-сайта в "облака". Модуль позволяет хранить данные отдельных модулей системы в разных облачных хранилищах. Это реально диверсифицирует файловое хранилище. Можно распределить файлы в зависимости от адреса или типа клиента. Можно распределить файлы в зависимости от типа информации: кто-то эффективно отдает легкую статику, кто-то тяжелый контент.

Примечание: Не важно, на чем вы пишите веб-проект. Рано или поздно вы обязательно столкнетесь с проблемой лавинообразного увеличения объема файлов для хранения и раздачи и должны будете принять верное архитектурное решение. Подумайте об этом заранее.
CDN
CDN
Сеть доставки (и дистрибуции) контента - (англ. Content Delivery Network или Content Distribution Network, CDN) - географически распределённая сетевая инфраструктура, позволяющая оптимизировать доставку и дистрибуцию контента конечным пользователям в сети Интернет. Использование контент-провайдерами CDN способствует увеличению скорости загрузки интернет-пользователями аудио-, видео-, программного, игрового и других видов цифрового контента.
Считается, что не так уж много в Рунете проектов, которым требуется CDN: новостные агентства, сайты с видео контентом и подобные им проекты с большими файлами. Считается, что сайты поменьше (которых подавляющее большинство: интернет-магазины, блоги, корпоративные сайты и т.д.) вполне могут обойтись и без этого сервиса, так как это дорого и сложно.
Например, в компании CDNvideo тарифы начинаются от 3000 руб. в месяц с трафиком от 1 Тб. Для большинства проектов такая дополнительная нагрузка - чрезмерна.
Само подключение, вроде бы, не должно вызвать сложностей (настроить DNS, заменить локальные ссылки на новые). Но надо не забыть заменить все ссылки (они могут генерироваться динамически приложением, быть жестко прописаны на страницах, могут указываться в файлах стилей (css) и скриптов (js)). Надо сохранить удобство разработки и отладки, работая на девелоперских серверах с локальными копиями. Надо обновлять кэш CDN при обновлении файлов. В общем, технически все не слишком однозначно.
Нужен ли CDN обычному сайту?
На обычном сайте нет "тяжелого" контента, который достоин CDN. Даже самые прогрессивные интернет-магазины, размещающие на сайте, например, видео-отзывы от клиентов, скорее всего просто ставят ссылки на YouTube, а не хранят все у себя.
Тем не менее, «подвинуть» поближе к посетителю можно весьма многое: все картинки, файлы стилей (css), javascript (js) и т.п. — по сути, практически весь статический контент можно вынести в CDN. А это, в среднем, до 80% объема трафика.
Помимо ускорения собственно сетью CDN за счет раздачи контента с ближайших к посетителям серверов, сайт, включивший CDN, получает дополнительное ускорение на клиентской стороне (во время рендеринга страницы браузером) за счет распределения запросов по разным доменам.
Все современные браузеры имеют лимит на количество одновременных соединений к одному домену (обычно - не более 6). Таким образом, даже если сервер может отдавать страницы с максимальной скоростью, а скорость клиентского подключения достаточно высока, то все равно загрузка всех элементов страницы (картинок, скриптов, файлов стилей) будет осуществляться максимум в 6 потоков.

При подключении CDN локальные ссылки заменяются на разные домены, и уже лишь каждый отдельный домен имеет ограничение на число соединений. Их же реальное максимальное число становится в несколько раз больше (по числу доменов, с которых осуществляется загрузка файлов).
Какая практическая польза от выигранных секунд? Например, для интернет-магазина?
На быстром сайте выше конверсия и больше просмотров страниц. Чем дольше загружается страница сайта, тем больше вероятность того, что самые нетерпеливые посетители не дождутся ее загрузки, уйдут с сайта и больше на него не вернутся.
Есть разные исследования, в которых предпринимаются попытки посчитать таких потенциальных клиентов, которых «недополучает» сайт. Например, инфографика от 5coins говорит о том, что 25% посетителей сайта покидают страницу, загрузка которой занимает более 4 секунд:

Специалисты компании GoMez, проанализировав 150 миллионов хитов на 150 сайтах, получили такие цифры: замедление загрузки страницы на 1 секунду снижает конверсию на 7%, а количество просмотров - на 11%.
Все эти исследования, конечно, не бесспорны, вызывают вопросы и методики исследования, и полученные цифры. Но главный вывод - "быстрее сайт - больше просмотров" - кажется абсолютно справедливым.
- В поисковых системах позиции быстрого сайта выше. Поисковые алгоритмы и формулы ранжирования результатов каждая поисковая система держит в секрете. Однако абсолютно очевидно то, что поисковые роботы, индексирующие сайты в интернете, не дождавшись загрузки страницы, не будут учитывать ее в общем поисковом индексе. Кроме того, все большее значение на результаты поиска оказывают поведенческие факторы. А это значит, что посетитель, ушедший с «медленной» страницы, автоматически понизит ее вес для поисковой системы. Ну и наконец, представители практически всех популярных поисковых систем так или иначе говорят о том, что напрямую учитывают скорость загрузки страниц в формулах ранжирования.
- Медленный сайт приносит прямые финансовые потери во время рекламных кампаний. Вы хотите активно продвигать свой проект. Заказываете для него контекстную, баннерную рекламу. Каждый клик стоит вполне определенных денег. Если посетитель вашего сайта пришел к вам по рекламному объявлению, но не дождался загрузки страницы, то за его клик вы просто заплатили впустую. Подключение CDN снижает нагрузку на основные серверы сайта. Так как весь статический контент загружается посетителями вашего сайта не напрямую с ваших серверов, а с узлов CDN, которые умеют очень эффективно кэшировать контент, снижается количество обращений непосредственно к вашим серверам. В среднем для статического контента соотношение числа запросов к самому сайту от серверов CDN к числу запросов от живых посетителей сайта составляет 1:50.
Взаимодействие с IT-службой клиента
Непосредственно эксплуатацией проекта должна заниматься IT-служба клиента, но на основе ваших рекомендаций и инструкций по настройке проекта, его обновления и мониторингу. Таким образом, вам необходимо грамотно выстроить процесс взаимодействия с IT-службой.
Построение эффективного процесса
Построение эффективного процесса
В данном уроке мы рассмотрим как выстроить эффективный процесс взаимодействия партнера с IT-службой клиента, объясним какие могут быть политические и технические риски и как с ними правильно работать, объясним какие бывают IT-службы и как с ними взаимодействовать.
Для начала рассмотрим какие могут быть преграды для построения эффективного взаимодействия в зависимости от представителей клиента:
- Если это менеджер, то основной сложностью может стать то, что зачастую у менеджера крупных компаний несколько высокомерное отношение к веб-студиям.
- Если приходится работать с аналитиком, то это может быть очень опытный человек, который имеет железную логику, отлично все просчитывает и формализует требования, знаком с IT-background'ом. Вам следует учитывать, что его будут интересовать вопросы на тему проектирования, UML, моделей сущностей и данных.
- Отношения с разработчиком могут складываться в выяснении кто же сильней и умней.
- Если представителем является человек, который занимается производством, то он обычно привык работать по некоторому бизнес-плану. Поэтому он будет смотреть налажен ли у вас техпроцесс, будет интересоваться постоянные ли у вас сотрудники, проводится ли инспекция кода, как обстоят дела с аудитом безопасности и с тестированием.
Обычно IT-служба клиента представляет из себя:
- либо полноценный отдел разработки,
- либо это опытные системные администраторы и люди, занимающиеся эксплуатацией проекта,
- либо это IT-менеджеры и просто люди с небольшим опытом.
Но нашим наблюдениям на деле чаще всего приходится работать со вторым типом: сисадминистраторами и людьми, которые занимаются эксплуатацией.
Поведение IT-служб может быть достаточно разнообразным: одни пытаются показать, что им никто не нужен, что они могут все сами сделать, другие - это сплошная бюрократия, но есть и адекватные службы. Такие IT-службы ориентируются на результат, хотят сделать все быстро и просто. Они не стремятся создавать огромные ТЗ, доверяют партнеру. В таких службах работают опытные и грамотные специалисты, в случае необходимости готовые даже подсказать решения и вместе обсудить поставленную задачу.
Как правильно вам поступать и действовать?
- Обязательно обладать очень хорошими знаниями в ваших областях, поскольку ваша деятельность очень узконаправленная.
- Писать код внимательно, модульно (клиент будет смотреть ваш код).
- Обязательно проверять, что пишут ваши программисты.
- Брать идеи и технологии от "1С-Битрикс".
- Использовать виртуальную машину "1С-Битрикс".
- Вести инструкции в Wiki и собирать базу знаний, если вам приходится заниматься системным администрированием.
- Не говорить того, в чем не уверены.
- Посещать семинары, выступать на IT-конференциях и, если есть возможность, то обучать сотрудников.
Действия для каждого конкретного типа сотрудника
Рассмотрим более детально ваши действия для каждого конкретного типа сотрудника IT-службы:
- Аналитик
- Формализуйте все имеющиеся в проекте сложные алгоритмы (например, используйте диаграммы UML state, activity, sequence diagram).
- Нарисуйте алгоритм и покажите клиенту.
- Опишите сценарий использования сложного алгоритма, для этого можете использовать UML Use Cases или просто тексты.
- Если в проекте есть сложные зависимости данных, то нарисуйте модель (ER-диаграмма, просто квадраты со связями между ними).
- В техническом задании должны быть только формализованные требования.
- При работе используйте API Bitrix Framework.
- Программист
- Пишете код в едином стиле: он должен быть понятным и читабельным всем.
- Комментируйте код аккуратно, если к нему требуются комментарии.
- Обязательно проверяйте, что пишут программисты.
- Максимально используйте API Bitrix Framework, делайте аналогично в своих модулях.
- Работайте только с опытными программистами.
-
Системный администратор
- Ведите контроль версий.
- Составьте инструкции по разворачиванию серверов разработки, тестирования и «боевые» сервера.
- Предоставьте рекомендации по «железу» и проведению нагрузочного тестирования.
- Составьте руководство по настройке и эксплуатации проекта, его мониторингу.
- Составьте инструкции по обновлению самого проекта и обновлению ПО.
- Предложите пройти обучающие курсы по Bitrix Framework.
Таким образом, для эффективного взаимодействия с IT-службой необходимо наладить открытый процесс работы. Если вы вступите на тропу войну, то проект будет скорее всего «завален». Старайтесь чаще встречаться, работать на позитиве, идите на контакт с клиентом и выстраивайте с ним рабочий диалог. Очень полезно обмениваться своим опытом работы. Даже если имеются какие-либо проблемы, то их нельзя скрывать, наоборот, нужно их поднять и совместно разрешить.
Обновление и изменение боевого проекта
Обновление и изменение боевого проекта
Введенный в эксплуатацию проект необходимо развивать вместе с клиентом. Чтобы правильно выстроить процесс работы, необходимо знать как должны передаваться изменения на «боевой» проект, как при этом избежать ошибок и как же правильнее обновлять проект.
Полезно иметь несколько тестовых серверов, причем тестовая конфигурация должна быть точной копией «боевого» сервера: версии Bitrix Framework, PHP, СУБД и другого ПО проекта должны совпадать. При наличии некоторых различий могут возникать ошибки в работе проекта, которые будет находить клиент.
Рассмотрим схему процесса эксплуатации и развития проекта:
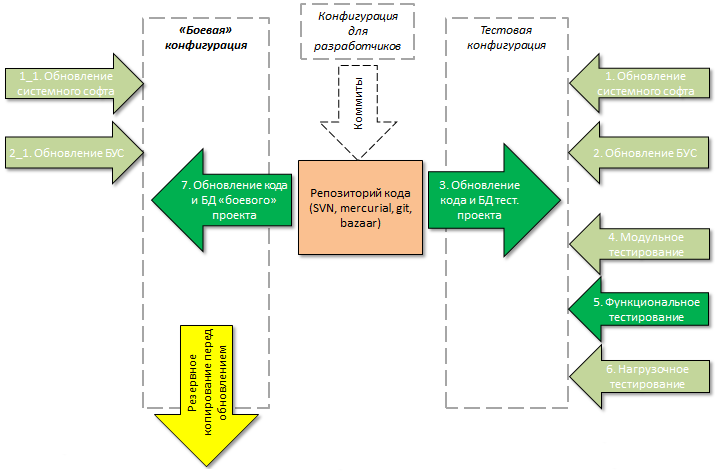
На схеме кратко показано, что в первую очередь на тестовом сервере необходимо выполнить обновление (при наличии) системного ПО и системы Bitrix Framewok. Затем из системы контроля версий (репозитария) мы передаем обновление кода и базы данных тестового проекта на сервер тестирования. После чего выполняем модульное, функциональное и нагрузочное тестирование.
На «боевом» сервере обязательно выполняем резервное копирование. Затем ставим те же обновления системного ПО и Bitrix Framewok, что и на тестовый сервер. После чего из системы контроля версии передаем обновления кода и базы данных «боевого» проекта.
Обновление системного ПО
Для хорошей работы вашего проекта необходимо использовать дистрибутивы только стабильных версий. Кроме того, их следует выбирать с увеличенным сроком поддержки, поскольку при смене ПО могут возникнуть ошибки и сбои в работе проекта.
Не следует использовать «левые» репозитории пакетов и кастомные сборки, которые могут сломать систему при обновлении. Программное обеспечение не следует собирать и из исходников, если не собираетесь его поддерживать.
Доступ на сервер не должно быть ни у кого, кроме администратора. Программное обеспечение не должны устанавливать несколько человек. Должен быть наведен порядок с правами доступа к серверам.
Перед тем, как установить обновления программного обеспечения на «боевой» сервер, необходимо установить и проверить их на тестовом сервере. При этом полезно изучить логи пакетов обновлений, поскольку всегда нужно быть готовым к тому, что при обновлениях может сломаться проект. Для подстраховки можно сделать LVM shapshot. Конфигурации серверов необходимо держать под контролем версий (например, использовать пакет etckeeper).
Обновление Bitrix Framework
Прежде чем приступать к обновлению системы Bitrix Framework, обязательно сделайте «горячий» бекап «боевого» проекта. Для максимально быстрого восстановления проекта можно сделать бекап через LVM shapshot файлов и базы данных. Сперва обновляем Bitrix Framework на тестовом проекте, проводим тестирование (см. схему выше) и только после удачного его завершения обновляем Bitrix Framework на «боевом» проекте при минимальной посещаемости.
В крайне маловероятном, но возможном случае нарушения работоспособности проекта после обновления по технологии SiteUpdate, постарайтесь как можно быстрее обратиться в техническую поддержку компании "1С-Битрикс" и предоставить доступ для восстановления, либо откатитесь к предыдущему состоянию, восстановив данные из бекапа.
Обновление кода проекта
При обновлении кода проекта всегда следите за тем, чтобы в стабильную ветку попадал только тщательно протестированный на тестовом сервере код. Нужно предусмотреть, чтобы в скриптах создания объектов Bitrix Framework не использовались внешние ключи, атрибут AUTO_INCREMENT. Кроме того, нужно следить за синхронностью систем, иначе при отсутствии зависимостей объекты Bitrix Framework будут некорректно создаваться на «боевом» сервере. Все изменения файлов должны быть залогированы, а также для скриптов создания объектов Bitrix Framework должны вестись подробные логи работы и ошибок. Все скрипты обновлений должны быть привязаны к релизам и храниться в системе контроля версий.
Тестирование
Для выполнения модульного тестирования на крупном проекте, работающего на системе Bitrix Framework, желательно иметь Unit-тесты для своих модулей, классов, библиотек. Компоненты проще тестировать руками либо частично использовать программу Selenium. Но при этом не нужно целиком и полностью покрывать веб-проект модульными тестами, необходимо найти баланс между разными видами тестирования.
При проведении функционального тестирования нарисуйте графики зависимостей: укажите что от чего зависит и где искать. Это необходимо, чтобы не приходилось после любого изменения перетестировать весь проект полностью. Для сложного функционала пишите и актуализируйте подробные варианты тестирования («test cases») либо проводите тестирование вместе с аналитиком. Простые задачи по функциональному тестированию можно выполнить с помощью Selenium.
Для проведения нагрузочного тестирования на тестовом сервере следует держать большой набор данных, приближенный к «боевому». Нагрузочное тестирование необходимо выполнять для измененных компонентов, страниц, сервисов. Тестовые планы сохраняйте в системе контроля версий. Автоматически проверяйте настройки кеширования компонентов, автокеширования и другие параметры, сильно влияющие на производительность. Используйте на проекте программы Munin, Cacti и анализируйте их графики, чтобы иметь возможность корректировать конфигурации серверов.
Безопасность крупного проекта
Безопасность крупного проекта
Важной задачей для владельцев веб-проектов является качественная и надежная защита от хакерских атак, взлома и кражи хранящейся на сайте информации.
Само по себе API системы Bitrix Framework взломоустойчиво. Потенциально опасный код возникает при интеграции, в кастомных страницах, компонентах и модулях. Обычно разработчику не хватает опыта аудита и взлома кода. Написание устойчивого к взлому кода требует не только глубоких теоретических знаний, но и многолетней практики.
Комплекс защитных мероприятий проектов, работающих на системе Bitrix Framework, реализуется с помощью модуля Проактивная защита. Модуль имеет следующие инструменты для обеспечения безопасности:
- Проактивный фильтр (WAF) и веб-антивирус, которые защищают снаружи от имеющихся уязвимостей в коде, допущенных интегратором.
- Панель безопасности, журнал вторжений, одноразовые пароли, защита сессий и контроль активности, которые позволяют выстроить инфраструктуру защиты.
- Защиту административной части и шифрование данных, которые позволяют строго регламентировать сети, считающиеся безопасными, и исключить целый класс потенциальных рисков, связанных с возможностью перехвата информации в канале передачи.
Данные инструменты страхуют разработчика, значительно снижают последствия ошибок и усложняют взлом. Но, несмотря на это, они не всегда позволяют устранить сам источник уязвимости. Для этого необходимо использовать инструмент аудита безопасности PHP-кода, который доступен в разделе Безопасность на странице Монитор качества:

В основе теста по проверке безопасности кода лежит статический taint-анализ. Запустив данный тест, вы сможете просмотреть в отчете найденные потенциальные уязвимости (при наличии) и тем самым усилить защиту проекта от взлома.
Инструмент идентифицирует следующие возможные уязвимости:
- XSS-атаки (Cross-site scripting);
- SQL-инъекции;
- выполнение произвольного php кода;
- выполнение произвольных системных команд;
- инъекции в заголовок ответа (HTTP Response Splitting);
- File Inclusion.
Проводить мониторинг состояния проекта с точки зрения безопасности помогает сканер безопасности. С его помощью вы можете выполнить внешнее сканирование окружения проекта, найти потенциальные уязвимости в коде, проверить настройки сайта и убедиться в правильности настроек всех систем безопасности.
Также для обеспечения высокого уровня безопасности вашего проекта следует придерживаться следующих правил:
- закрыть и постоянно мониторить закрытость снаружи критически важных портов всех серверов;
- проверять контрольные суммы файлов серверов;
- проверять настройки PHP;
- проверять все, что посетитель загружает к вам на сайт.
Организация резервного копирования
На любом проекте хранится большое количество важных данных. Особую ценность представляют данные пользователей: заказы, персональная информация, документы и т.п. Потеря части данных может нанести сильный удар по репутации клиента, а потеря всех данных пользователей может обернуться закрытием бизнеса клиента. При этом пострадает ваша репутация партнера и ваш бизнес. Чтобы избежать таких плачевных последствий, необходимо грамотно организовать систему резервного копирования.
Чем крупнее и важнее проект, тем чаще должно выполняться это копирование и не нужно надеяться на хостера. При этом нужно иметь стратегию копирования.
Облачные структуры предоставляют свое API, позволяющее выполнять копирование быстро и надежно (например, бекап файловой системы в 500 Гб в течение нескольких минут), делать snapshot виртуальной машины. Snapshot - это самое современное, самое мощное на данный момент средство копирования. Без «облака» настройка такого резервирования - задача непростая даже для высококвалифицированного персонала.
Бекап файлов и базы данных
Общие принципы и требования
Рассмотрим общие принципы, которыми вы должны руководствоваться при организации резервного копирования для крупного проекта:
- для разных сценариев сбоев должны быть созданы разные резервные копии (бекапы);
- необходимо делать резервные копии файлов и базы данных;
- резервное копирование должно выполняться постоянно;
- нужно делать бекапы конфигурации и настроек сервера и программного обеспечения;
- полезно проводить учения по восстановлению системы;
- нужно уметь восстанавливаться быстро;
- восстановление системы можно частично автоматизировать.
Бекап должен отвечать следующим требованиям:
- изолированность;
- целостность;
- версионность;
- безопасность.
Если вы будете следовать данным принципам и иметь отлаженные процессы работы с резервными копиями, то вы всегда сможете быстро восстановить работоспособность проекта или отдельных его элементов, даже в случае критических сбоев, в том числе с потерей данных.
Бекап файлов
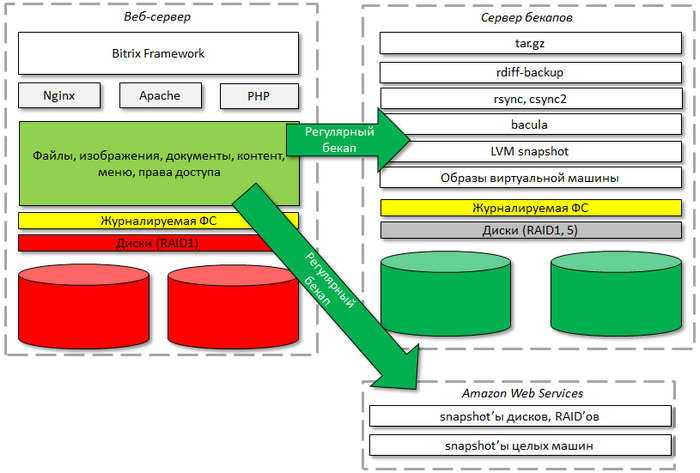
Бекап файлов должен храниться на отдельном сервере. Если проект небольшой, то обычно бекап файлов делается с помощью программы tar (плюс утилита gz или bz2). Альтернативой могут быть rsync, csync2, rdiff-backup.
Если на проекте очень много файлов, то для создания бекапа файлов следует использовать LVM snapshot, облачный механизм snapshot'ов для Amazon (см. пример), snapshot в хранилище типа NetApp и т.п. При этом обратите внимание, что для создания snapshot'ов подходят только те файловые системы, которые поддерживают возможность "замораживания" (fsfreeze).
Кроме того, иногда бывает полезным вынести редко меняющиеся файлы в облако (например, Amazon S3, Google Cloud Storage) и время от времени делать бекап самого облака.
Если на сервере хранится большое количество бекапов, то для удобной работы с ними целесообразно иногда пользоваться пакетом bacula.
Внимание! Не забывайте периодически тестировать восстанавливаемость бекапов файлов.
Бекап базы данных
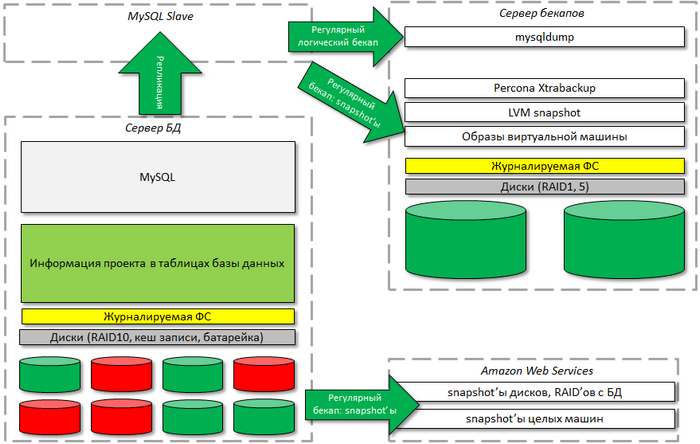
Репликация – это не бекап, но может выполнить некоторые его функции, например, при использовании pt-slave-delay.
Логические (mysqldump) и бинарные (Percona Xtrabackup или MySQL Enterprise Backup) бекапы используются для восстановления отдельных баз или таблиц, поврежденных в случае некорректных операций в системе или ошибок пользователей.
Логический бекап MySQL должен быть всегда и его лучше делать со slave-сервера, чтобы не нагружать сервер с «боевой» базой данных. При этом необходимо отслеживать синхронность его данных (mixed mode replication, --sync-binlog, pt-table-checksum). Используя опцию --single-transaction, можно сделать целостный бекап без блокировки таблиц, причем иногда прямо с «боевой» базы данных. Кроме того, рекомендуется сохранять позицию бинарного лога в бекапе (опция --master-data=2). Сами бинарные логи полезно хранить на отдельном диске, поскольку они очень важны при восстановлении.
Бинарный бекап можно делать и с «боевого», и со slave-сервера (делается он не очень быстро, но гораздо быстрее логического). Кроме того, он позволяет сохранять инкременты, т.е. его можно делать чаще одного раза в сутки. Восстановление из бинарного бекапа достаточно долгое, зачастую удобно пользоваться инкрементальными snapshot'ами дисков базы данных. Но все-таки такой бекап позволяет довольно быстро поднять новый slave-сервер (значительно быстрее, чем из логического бекапа).
Кроме того, можно удобно и быстро сделать копию базы данных, используя механизм snapshot'ов (LVM snapshot'ы, snapshot'ы в Amazon и NetApp). Общая схема действий такова: блокируются все таблицы базы, сбрасываются изменения и делается freeze файловой системы, затем снимается snapshot, «размораживается» файловая система и снимается блокировка с таблиц. Снимать snapshot'ы с базы данных можно достаточно часто: хоть каждые полчаса и даже чаще. Но обязательно необходимо проверять, что база восстанавливается из такого snapshot'а. Время восстановления обычно быстрее, чем для логического бекапа, может составлять от нескольких минут до часов (в зависимости от ситуации). Кроме того, используя, например, сервис Amazon, можно делать snapshot'ы всего сервера целиком и разворачиваться очень быстро в случае сбоя.
Полезные советы
- Для файлов желательно делать раз в сутки обычный бекап и несколько раз в сутки снимать snapshot'ы.
- Для базы данных полезно делать раз в сутки логический бекап, несколько раз в сутки делать snapshot'ы или бинарный (можно инкрементальный) бекап с помощью Xtrabackup.
- Необходимо иметь как минимум один slave-сервер базы данных.
- Периодически проверяйте, что файлы и база данных восстанавливаются из бекапов.
- Бекапы храните на отдельном сервере.
- Обсудите с клиентом длительность хранения бекапов и snapshot'ов (разумный срок - неделя).
Проблемы при восстановлении БД и их решения
В этом уроке рассмотрим возможные проблемы и их решения.
Проблема: разрушились диски или файловая система на master-сервере БД (при этом fsck не помогает).
Решение. Делаем slave-сервер master-сервером. Редактируем необходимым образом файл dbconn.php (можно скриптом или переключаем IP). Далее выполняем одно из перечисленных ниже действий:
- или клонируем master-сервер (Xtrabackup);
- или поднимаем slave-сервер и «переливаем» (mysqldump) в него данные из нового master-серверa;
- или восстанавливаем базу данных из snapshot'а и «догоняем» по бинарным логам;
- или разворачиваем последний логический бекап со slave-сервера и «догоняем» его по бинарным логам нового master-серверa (
CHANGE MASTER TO MASTER_LOG_FILE=…, MASTER_LOG_POS=…).
Таким образом, всегда полезно иметь рядом «горячую» копию БД, на которую можно быстро переключиться.
Проблема: случайно испорчена часть данных на master-сервере БД.
Например, в результате ошибки администратора или разработчика удалены поля в таблице заказов посетителей. Конечно, испорченные данные уже есть и на slave-сервере.
Решение. В приложении необходимо заблокировать часть функционала. Написать, что в ближайшее время всё будет починено, и выполнить следующие действия:
- Развернуть рядом БД из snapshot'а (делается это достаточно быстро) или из логического бекапа (будет медленнее);
- «Догнать» таблицу заказов до ошибочного запроса по бинарным логам master-серверa (man mysqlbinlog);
- Перенести восстановленную таблицу заказов на «боевую» БД (можно через Xtrabackup);
- Восстановить функционал приложения в полном объеме.
Проблема: случайно испорчена большая часть данных на master-сервере БД.
Например, в результате ошибки администратора или разработчика испортилось большое количество данных (заказы, счета, каталог). Конечно, на slave-сервер изменения уже ушли.
Решение. Необходимо заблокировать сайт. Написать, что в ближайшее время всё будет восстановлено, и выполнить следующие действия:
- Развернуть рядом БД из последнего snapshot'а либо из бинарного инкрементального бекапа (Xtrabackup);
- «Догнать» базу до ошибочного запроса по бинарным логам «испорченного« master-серверa (man mysqlbinlog);
- Открыть сайт (обычно максимальный простой занимает несколько часов);
Иногда использование логического бекапа и бинарных логов позволяет быстрее развернуть БД. Желательно проводить учения по восстановлению системы.
Бекапим серверы в Amazon
В уроке будут рассмотрены архитектурные решения на EBS-дисках для обеспечения надежности и производительности веб-проектов и конкретные техники резервного копирования, которые используются в повседневной работе
Надежность EBS-дисков - RAID1 или "хуже"?
Из официальной документации Amazon по EBS-дискам до конца не ясно, надежнее ли они RAID1 или нет - всякие разговоры про функциональную зависимость объема диска и времени последнего снапшота диска - не внушают оптимизм:
«The durability of your volume depends both on the size of your volume and the percentage of the data that has changed since your last snapshot. As an example, volumes that operate with 20 GB or less of modified data since their most recent Amazon EBS snapshot can expect an annual failure rate (AFR) of between 0.1% – 0.5%, where failure refers to a complete loss of the volume»
Во время аварии в европейском ДЦ Amazon у нас из софтварного RAID10 вылетели сразу 2 диска из-за отключения питания в датацентре. В сети также иногда появляются жутковатые сообщения о том, что диск EBS внезапно "сломался", клиенту прислали письмо на тему "ваши данные потерялись, к сожалению" и официально рекомендуется сделать снапшот как раз за минуту перед отказом диска. Такое впечатление, что механизм снапшотов появился именно для "подстраховки" от выхода из строя не очень надежных EBS-дисков.
Публичные виртуальные машины, которые используются для создания собственных приватных образов, имеют только один EBS-диск, не состоящий в рейде и на котором находится корневой раздел. А загрузить машину с корневым разделом на софтварном рейде - мягко сказать, непросто и требует времени.
Тем не менее, за полгода в Amazon у нас не вылетел ни один диск (у нас их около 50), не считая отключения питания после удара молнии, что позволяет относиться к ним как к более-менее надежным RAID1 дискам (репликация на одно устройство, расположенное в том же датацентре), уступающим в надежности s3 (реплицируется дополнительно на 2 устройства в разных датацентрах, и вообще это не блочное устройство), но в 10 раз более надежным, чем обычные жесткие диски.
Софтварный рейд и невысокая производительность EBS-дисков
После миграции в Amazon можно столкнуться с достаточно невысокой производительностью EBS-дисков, что особенно заметно на машинах с MySQL.
"Подсмотрев" идею в RDS (Amazon автоматически, в зависимости от суммарного объема EBS-дисков, размещают информацию базы данных на софтварном рейде) и, использовав смекалку, можно перенести данные на созданный из EBS-дисков софтварный RAID10 (mdadm в Linux):
cat /proc/mdstat Personalities : [raid10] md0 : active raid10 sdo[0] sdj[8](S) sdi[7] sdh[6] sdg[5] sdn[4] sdm[3] sdl[2] sdk[1] 629145344 blocks 64K chunks 2 near-copies [8/8] [UUUUUUUU]
Для увеличения уровня отказоустойчивости используются софтварные рейды.
После миграции данных на рейды проблемы с производительностью дисковых подсистем на машинах перестали беспокоить.
Стоит упомянуть, что относительно недавно появились более быстрые SSD-backed диски, которые интересно потестировать на производительность.
Кластерные файловые системы и EBS-диски
EBS-диски, как оказалось, нельзя одновременно смонтировать на несколько виртуальных машин для использования кластерной файловой системы типа OCFS2 или GFS2. Поэтому для кластеризации контента можно использовать утилиту csync2, форсированную надстройкой для "быстрой" синхронизации часто обновляемых тяжелых папок на базе inotify.
Бекап EBS-дисков
Диски виртуальной машины совсем несложно бекапить, т.к. именно для этого создан инструмент создания снапшотов блочного устройства:
ec2-create-snapshot vol-a5rtbvwe
Операция стартует очень быстро (секунды), а загрузка снапшота в s3 продолжается определенное время, в зависимости от объема диска и загруженности Amazon - до десятков минут.
Мы взрослые люди и понимаем, что целостный снапшот диска может быть если:
- Диск предварительно отмонтирован:
umount -d /dev/sdh
- Сервер предварительно остановлен.
- Файловая система "заморожена". Хотя в этом случае нужно еще приложениям сказать, чтобы сбросили данные на диск.
Иначе мы получаем снапшот диска "как бы после внезапного выключения питания" и диск нужно будет полечить (fsck) при загрузке машины - что, благодаря, современным журналируемым файловым системам (ext3, ext4, xfs и др.) происходит незаметно и часто быстро за счет проигрывания журнала.
Мы тестировали создание снапшота диска с "живой" (без размонтирования) ext3 и xfs - после некоторой паузы для проигрывания журнала диск (созданный из снапшота) монтируется и работает.
"Замораживание" файловой системы
В качестве файловой системы, поддерживающей "приостановку", мы выбрали xfs. Эта файловая система рекомендуется Amazon и используется утилитами создания целостного снапшота типа ec2-consistent-backup:
xfs_freeze (-f | -u) mount-point
Действительно, если после xfs_freeze -f сделать снапшот диска, то он монтируется без проигрывания журнала очень быстро.
В CentOS 6 (и видимо в других дистрибутивах с "обновленным" ядром) стало возможным "фризить" также дефолтные файловые системы типа ext3/ext4 командой fsfreeze.
Бекап софтварного рейда
Если мыслить логически, то нужно:
- "остановить" файловую систему рейда,
- запустить создание снапшота для каждого физического диска рейда,
- "отпустить" файловую систему рейда.
К сожалению, в документации к API Amazon нет информации, сколько времени должно пройти между 2) и 3). Однако опытным путем было найдено (и аналогично делается в данной утилите), что достаточно получить идентификаторы снапшотов из вызова API для каждого диска рейда и файловую систему рейда можно "разморозить" - и при сборке рейда он подхватится без ребилдинга. Иначе - начнет ребилдиться.
Вот так сделали мы:
bxc_exec("/usr/bin/ssh remote_xfs_freezer@hostname".escapeshellarg("sudo /usr/sbin/xfs_freeze -f /xfs_raid_path"));
...
ec2-create-snapshot - для каждого диска рейда
...
bxc_exec("/usr/bin/ssh remote_xfs_freezer@hostname".escapeshellarg("sudo /usr/sbin/xfs_freeze -u /xfs_raid_path"));
...
ec2-create-volume --snapshot id_of_snapshot
...
ec2-attach-volume volume_id -i instance_id -d device
...
mdadm --assemble /dev/mdN /dev/sd[a-z]
Снапшот MySQL?
Можно сбросить данные MySQL на диск: FLUSH TABLES WITH READ LOCK, зафризить файловую систему: xfs_freeze -f /path, затем выполнить API вызов снятия с дисков снапшота ec2-create-snapshot, но есть и другой, полностью устраивающий вариант - асинхронная репликация MySQL в другой ДЦ. Интересным предоставляется создание снапшотов базы с использованием xtrabackup - без вышеописанных "танцев с бубнами".
Бекапим всю машину сразу
Если отдельно бекапить диски, группы дисков в рейдах, то, при наличии конфига - процесс работает стабильно и прозрачно. Однако, если вам нужно иногда (например, в ДЦ ударила на выходных молния) переезжать между AZ Amazon (датацентрами) - проще ввести уровень абстракции выше ID инстансов, снапшотов и дисков и оперировать категориями ролей и образов (AMI - Amazon Machine Image) машин. Через API можно назначать объектам Amazon тэги и фильтровать по ним выборки.
Мы определили роли: веб-машина, СУБД, балансировщик, машина мониторинга и наши скрипты бекапов работают примерно так:
- Найти машину с тегом "СУБД" и получить ее ID,
- "Заморозить" диски машины,
- Сделать снапшот дисков. Задать снапшоту тэг "СУБД",
- "Разморозить" диски машины,
- Для очистки устаревших снапшотов можно сделать выборку по тэгу и времени и удалить лишние.
Однако, гораздо проще бекапить работающую виртуальную машину в образ (AMI image). При этом в образе сохраняются ее настройки и пути к создаваемым снапшотам, из которых будут созданы диски машины, присоединяемые к ней при старте:
ec2-create-image id_of_instance [--no-reboot] ... ec2-run-instances ami_image_id
Как говорится, почувствуйте разницу! Можно создать образ с машины с RAID10 из 9 дисков - одной командой, не отвлекаясь на ID ее дисков и снапшотов - вся необходимая для воссоздания машины информация записывается в образ AMI автоматически.
Единственный минус - неясно, на какое время нужно лочить диски/рейды работающей машины, чтобы создать из нее образ AMI. Опытным путем было установлено, что достаточно 2-5 секунд - если меньше, то диски/рейды начинают восстанавливаться при создании новой машины. Также очень удобно то, что поднять машину из бекапа в образ (AMI) можно в другом датацентре (AZ).
У себя мы создаем бекап всех машин нашей кластерной конфигурации (сотни гигабайт) в образ AMI два раза в сутки.
|
Очистка "устаревших" образов, вместе с их снапшотами производится скриптом:
|
|---|
function bxc_delete_old_instance_backups( AmazonEC2 $ec2, $instanceRole = '', $bkpsMaxCount = 3) {
if (!$instanceRole || !is_object($ec2) || $bkpsMaxCount<1 ) {
bxc_log_error("Bad input params: ".__FUNCTION__);
return false;
}
$response = $ec2->describe_images(array(
'Filter' => array(
array('Name' => 'tag:Role', 'Value' => 'Image:'.$instanceRole),
array('Name' => 'state', 'Value' => 'available'),
)
));
if ( !$response->isOK() ) {
bxc_log_amazon_error($response, __FUNCTION__.":".__LINE__);
return false;
}
if ( isset($response->body->imagesSet->item) ) {
$images = array();
$snaps = array();
foreach ( $response->body->imagesSet->item as $image ) {
$images[ (string) $image->name ] = (string) $image->imageId;
if ( isset($image->blockDeviceMapping->item) ) {
foreach ( $image->blockDeviceMapping->item as $disk ) {
$snaps[ (string) $image->name ][] = $disk->ebs->snapshotId;
}
}
}
if ($images) {
krsort($images);
} else {
bxc_log("No images with tag:Role=Image:$instanceRole");
return true;
}
if ( count($images) <= $bkpsMaxCount ) {
bxc_log("Nothing to delete");
return true;
}
$imagesToDelete = array_slice($images, $bkpsMaxCount, count($images)-$bkpsMaxCount, true);
foreach ($imagesToDelete as $imageName=>$imageId ) {
$r = $ec2->deregister_image($imageId);
if ( $r->isOK() ) {
bxc_log("Image deleted ok: ".$imageId);
sleep(5);//Important. Wait to ami really be deleted ;-)
foreach ( $snaps[$imageName] as $snapId ) {
$rr = $ec2->delete_snapshot( $snapId );
if ( $rr->isOK() ) {
bxc_log("Snapshot deleted ok: ".$snapId);
} else {
bxc_log_amazon_error($rr, __FUNCTION__);
bxc_log_error("Cannot delete snapshot: ".$snapId);
}
}
} else {
bxc_log_amazon_error($r, __FUNCTION__);
bxc_log_error("Cannot delete image: ".$imageId);
}
}
return true;
} else {
bxc_log("No images with tag:Role=Image:$instanceRole");
return true;
}
return false;
}
|
Админка, консоль или API
Amazon AWS имеют неплохую админку, однако многие вещи можно сделать только через API. Для Linux можно установить инструменты командной строки для работы с API Amazon, которые довольно хорошо документированы. Мы используем такие инструменты:
ls /opt/aws/ AutoScaling-1.0.39.0 ElasticLoadBalancing-1.0.14.3 ec2-api-tools-1.4.4.1 env-set.sh
Последний скрипт устанавливает переменные окружения для работы инструментов. Обратите внимание, практически каждый веб-сервис Amazon имеет свой набор утилит, которые нужно скачать и установить отдельно. Для управления машинами, например, документация находится тут, а утилиты командной строки - тут.
Пока неплохо себя показывает в работе официальный SDK для работы с API Amazon для PHP (вышеприведенный скрипт использует именно эту библиотеку).
Выводы
С EBS-дисками Amazon можно эффективно работать, объединив их в софтварный рейд. К сожалению, нельзя замонтировать EBS-диск к нескольким виртуальным машинам, для работы с кластерной файловой системой типа OCFS2, GFS2. Бекапы как дисков, так и рейдов EBS делаются несложно, необходимо только понять основные принципы и обойти подводные камни. Удобно бекапить машины целиком, а не по отдельному диску - это позволит быстро развернуть конфигурацию в соседнем датацентре, если в ваш ДЦ ударит молния или врежется самолет.
Резервное копирование в Amazon Web Services
Техника настройки
Рассмотрим технику настройки резервного копирования файлов и MySQL/InnoDB/XtraDB в приложениях, развернутых в облаке, на примере Amazon Web Services.
Представим себе крупный интернет-магазин, который хранит бизнес-информацию как в базе данных, так и на дисках. Новые файлы появляются ежеминутно, а общий размер контента составляет сотни гигабайт. Как делать резервные копии в таком случае?
Прежде всего разберемся в технологиях хранения данных. Для хранения данных виртуальных машин сервис Amazon предлагает виртуальные блочные устройства EBS. Такие диски очень просто создаются и подключаются к серверу в 2 клика, максимальный размер диска - 1ТБ (по умолчанию есть ограничение на 5000 дисков и 20ТБ, но его увеличивают по первой просьбе). Что же касается производительности EBS-дисков, то сразу можно сказать, что они медленнее «железных» дисков (это видно даже на простых операциях типа копирования папок с диска на диск, распаковке архивов и т.д.).
Для успешной работы с дисками сервиса Amazon полезно создать программный RAID (делается это довольно просто, работает долго и практически не ломается). RAID может особенно пригодится, если EBS-диск внезапно выйдет из строя. Кроме того, миграция данных с EBS-дисков на программный RAID решает проблемы с производительностью.
Для резервного копирования Amazon предлагает нам LVM и snapshot'ы в режиме "copy-on-write". Snapshot'ы блочного устройства можно делать столько раз, сколько необходимо. При этом:
- В очередной snapshot EBS-диска попадают только изменения.
- Удалять snapshot'ы можно и нужно для сохранения баланса между размером окна резервирования и стоимостью хранения данных. При этом можно удалять любой лишний snapshot - Amazon автоматически консолидирует данные нужным образом.
- Snapshot'ы дисков сохраняются в Amazon S3 - хранилище объектов любого формата, реплицирующее данные минимум еще в 2 дата-центра.
- Snapshot диска делается практически мгновенно, затем в фоне данные передаются в Amazon S3 определенное время (иногда десятки минут, если Amazon загружен).
Таким образом, мы можем делать snapshot'ы большой папки часто меняющего контента хоть каждые 5 минут и они будут надежно сохранены в Amazon S3. Если нам потребуется откатить, например, 1ТБ изменяемых данных на 5 минут назад, то мы с легкостью сделаем это сделаем следующим образом:
- сделаем диск из сохраненного snapshot'а;
- и подключим диск к серверу.
Разумеется, технически невозможно мгновенно передать 1ТБ данных из Amazon S3 в SAN, где живут EBS-диски. Поэтому, хотя блочное устройство и становится доступным операционной системе, данные на него будут заливаться в фоне определенное время и, возможно, скорость работы с диском поначалу будет не очень высокой. Но, тем не менее, такой подход позволяет удобно делать инкрементальный бекап большого объема данных и откатывать их на любую точку (например, на неделю назад с шагом в 5 минут).
Кроме возможности создания snapshot'ов с EBS-дисков, можно напрямую отправлять файлы в Amazon S3. В этом случае удобна в использовании утилита s3cmd, позволяющая синхронизировать деревья файловой системы с облаком в обоих направлениях (передаются только изменения на базе расчета md5 на локальном диске и хранения md5 объекта внутри Amazon S3 в ETag).
Snapshot RAID'а
Для хорошей производительности мы объединили EBS-диски в RAID'ы, но как же делать бекап RAID'а? Можно воспользоваться специальной утилитой ec2-consistent-snapshot (или в своих скриптах повторить ее логику) и выполнить следующие действия:
- Использовать файловую систему, поддерживающую freeze.
- Сбросить изменения и кратковременно запретить запись в файловую систему (команда fsfreeze или xfs_freeze в зависимости от типа файловой системы).
- Сделать snapshot'ы каждого диска RAID'а (AWS API call CreateSnapshot).
- Разрешить запись в файловую систему.
Для подключения сохраненного RAID'а лучше написать скрипт, подключающий диски к машине и запускающий из них программный RAID. Сохраненный в snapshot'ы вышеуказанным способом RAID прекрасно «поднимается», не проигрывая журнал файловой системы.
Snapshot машины целиком
Иногда удобнее сделать snapshot всей машины целиком. Выполняется это с помощью команды CreateImage, которая позволяет сделать snapshot в двух режимах: с остановкой машины или без. Но обратите внимание, что в последнем случае возможна порча данных на дисках или RAID'ах.
После создания snapshot'а машины появляется объект AMI (Amazon Machine Image), имеющий ссылки на сохраненные snapshot'ы каждого своего диска. Можно одной командой запустить из этого объекта сервер со всеми дисками/RAID'ами (AWS API call RunInstances). Рабочие сервера можно не только бекапить целиком, но и разворачивать из бекапа целиком со всеми RAID'ами одной командой. Однако есть серьезный «подводный камень»: команда CreateImage совершенно непрозрачна и неясно, сколько времени она снимает snapshot'ы со всех дисков сервера (скажем, секунду или 10 секунд?). Поэтому необходимо тщательно тестировать скрипт перед его использованием.
Инкрементальный бекап MySQL
Инкрементальный бекап MySQL с помощью сервиса Amazon делается следующим образом:
- Сбрасываются буферы MySQL/InnoDB/XtraDB на диск:
FLUSH TABLES WITH READ LOCK. - Сбрасываются изменения и кратковременно запрещается запись в файловую систему.
- Делается snapshot всех дисков машины: CreateImage. Но если есть опасения (см. выше про «подводный камень»), то делаются snapshot'ы каждого диска RAID'а с базой данных: AWS API call CreateSnapshot.
- Разрешается запись в файловую систему.
- Снимается глобальная блокировка всех таблиц во всех базах данных:
UNLOCK TABLES.
Теперь у нас имеется объект AMI с «горячим» бекапом MySQL.
Таким образом, довольно просто делать инкрементальный бекап сервера MySQL в Amazon S3 хоть каждые 5 минут с возможностью его быстрого ввода в использование. Если сервер используется в репликации, то он восстановит базу данных как правило без особых проблем при условии, что вы не забыли в настройках задать консервативные настройки репликации (либо базу можно довольно быстро вернуть в работу вручную):
sync_binlog = 1 innodb_flush_log_at_trx_commit = 1 sync_master_info = 1 sync_relay_log = 1 sync_relay_log_info = 1
Написание скриптов для работы с объектами сервиса Amazon
Для системного администратора имеются специальные утилиты, получающие REST-методы API сервиса Amazon. Поэтому, чтобы написать скрипт по основным действиям с сервисом Amazon, необходимо для каждого используемого веб-сервиса скачать утилиты и вызовы к ним прописать в bash-скрипте. В качестве примера рассмотрим скрипт, меняющий у сервера аппаратное обеспечение («железо»):
#!/bin/bash
#Change cluster node hw type
#Which node to change hardware?
NODE_INSTANCE_ID=$1
#To which hw-type to change?
#Some 64-bit hw types: t1.micro (1 core, 613M), m1.large (2 cores, 7.5G), m1.xlarge (4 cores, 15G),
#m2.xlarge (2 cores, 17G), c1.xlarge (8 cores, 7G)
NODE_TARGET_TYPE='c1.xlarge'
#To which reserved elastic ip to bind node?
NODE_ELASTIC_IP=$2
ec2-stop-instances $NODE_INSTANCE_ID
while ec2-describe-instances $NODE_INSTANCE_ID | grep -q stopping
do
sleep 5
echo 'Waiting'
done
ec2-modify-instance-attribute --instance-type $NODE_TARGET_TYPE $NODE_INSTANCE_ID
ec2-start-instances $NODE_INSTANCE_ID
ec2-associate-address $NODE_ELASTIC_IP -i $NODE_INSTANCE_ID
Для разработчиков имеются библиотеки на разных языках для работы с API сервиса Amazon (например, AWS SDK for PHP - библиотека для работы из PHP).
Резервное копирование Bigdat'ы
Введение
Многие успешные стартапы рано или поздно сталкиваются с работой с большими объемами данных и должны быть готовы - знать инструменты и алгоритмы. Благо теорию до нас проработали Google, Facebook*, Twitter и даже Amazon приготовил веб-сервисы, помогающие противостоять таким задачам.
Если, вдруг, возникла задача на резервное копирование Bigdat'ы? Можно использовать алгоритм map-reduce (от Google) или бесплатный инструмент кластерных параллельных вычислений - hadoop, используемый в Facebook*, Twitter, Yahoo и много ещё где (от единиц машин до тысяч в кластере).
* Социальная сеть признана экстремистской и запрещена на территории Российской Федерации.
Что такое Hadoop & map-reduce
Логика этих механизмов очень проста:
- Имеется входной поток данных (например: логи, почта, имена файлов).
- Имеется алгоритм: взять строку из stdin и напечатать строку в stdout, что нибудь делая полезного по пути. Алгоритм реализует скриптик mapper.
- Все что выведено в п.2, нужно агрегировать - этим занимается алгоритм в скриптике reducer.
Примечание: mapper и reducer пишутся на любых языках программирования, можно даже использовать стандартные утилиты unix. Эта простота подкупает.
Далее все это загружается в кластер, расширяется на кучу машин (настраивается), параллельно выполняется и получаем выполненную в N раз быстрее задачу. При этом проверяется состояние каждой задачи, каждой машины, если что, задачи рестартуются. Что важно, активно используется локальная кластерная файловая система для обмена данными между нодами кластера hdfs.
Пример решения задачи
Имеется 10 млн. файлов, хранящиеся в бакете s3. Необходимо измененные файлы скопировать в другой бакет s3 за разумное время. Как?
Если в проекте есть 10 млн. файлов, то нужно пробежать по 10 млн файлов и определить, изменился ли каждый файл. А если изменился, то нужно скопировать в другой бакет.
То есть нужно для каждого файла выполнить операцию условного копирования (E-tag или Update-time) из бакета А, в бакет Б - по http. Сами данные - не перемещаются, только обращения к API. (Но в перспективе может возникнуть потребность и файлы переносить в другой регион на другие сервера.) Батчей на копирование в API S3 (put copy) - нет, но даже если бы были, ненамного ускорили бы.
Дополнительно можно попробовать:
- curl-multi - перерасход памяти, все равно не снимает необходимости параллелить потоки.
- Запускать параллельно в N потоков/процессов, но на одной машине можно эффективно запустить в работу довольно ограниченное число параллельных процессов - десятки.
Но даже в этом случае максимум, что можно получить из нескольких параллельных процессов на одном сервере, создавая заметную нагрузку - неделя срока на каждое резервное копирование.
И ещё сложность в том, что нужно это настроить, администрировать, запускать и останавливать.
Что предлагает Amazon
В связи с востребованностью клиентами кейса для:
- обработки и агрегации логов для систем аналитики веб-сайтов;
- обработки больших объёмов писем;
- обработки твитов (в twitter) и т.п.;
- обработки миллионов задач параллельно;
Amazon предложил веб-сервис, оптимально заточенный под резервирование больших объёмов данных:
- hadoop уже предустановлен в виде настроенной виртуальной машины, нужно его подстроить и нагрузить заданиями.
- Наши данные (имена файлов) заливаются в S3
- В s3 можно разместить и выполнимый код алгоритма, например на php (хоть на bash).
- Запускается одну команда в консоли с параметрами.
- Создается вычислительный кластер, все данные резервируются, а результат выгружается в S3
- Кластер закрывается
При такой схеме оплата идёт только за время использования железных серверов, но несколько (~20%) выше, чем за обычные железки. Это из-за того, что автоматической настройкой, интеграцией с S3, файероволами и обновлением кластерного софта занимается сам Amazon. В принципе клиент может сам этим заниматься и не доплачивать 20%, но придется всю автоматику написать и постоянно обслуживать.

От клиента требуется разработать простейший алгоритм, положить его в виде файлика и входные данные в S3. Дальнейшая работа по бекапу - автоматическая.
Как реализован этот механизм на примере Битрикс24
Созданы необходимые элементарно простые mapper, reducer, конфигуратор.
Подготовил код создания списка файлов (во много потоков, конечно, но занимает полчасика и нагрузку особую не создает). Включил в крон:
/home/bitrix/bxc/cron_jobs/bkp_s3_folder_hadoop.php
|
Пример команды запуска кластера в Amazon
|
|---|
/opt/aws/emr/elastic-mapreduce --create --stream \ --name bx24_s3_bkp_$D \ --step-name bx24_s3_bkp_$D \ --with-termination-protection \ --step-action CANCEL_AND_WAIT \ --ami-version '2.4.2' \ --bootstrap-action 's3://***/code/bkp_s3_folder_hadoop_bootstrap.sh' \ --bootstrap-action 's3://elasticmapreduce/bootstrap-actions/configure-hadoop' \ --args "-m,mapred.map.max.attempts=20,-m,mapred.tasktracker.map.tasks.maximum=15,-m,mapred.task.timeout=600000" \ --input 's3://***/input/' \ --mapper 's3://***/code/bkp_s3_folder_hadoop_mapper.php' \ --reducer 's3://***/code/bkp_s3_folder_hadoop_reducer.php' \ --output 's3://***/output_'$D \ --log-uri 's3://***/logs/' \ --num-instances 5 \ --master-instance-type m1.small \ --slave-instance-type m1.xlarge \ --key-pair '***' |

Скрипт формирует, затем выгружает список файлов в облако и стартует кластер hadoop (6 машин):
/home/bitrix/bxc/cron_jobs/bkp_s3_folder_hadoop_launcher.sh
Необходимо также подправить настройки виртуальной машины Amazon, объем памяти и число воркеров. При старте мы в bootstrap дописываем несколько своих настроек. После всех этих действий желательно провести тестирование на большом объёме файлов, например 10 миллионов:
Этим способом можно сократить время бэкапа 10 млн. файлов до 16 часов вместо 7 дней. То есть можно делать резервное копирование чаще. А если файлов станет 20 миллионов, то надо просто изменить лишь одну циферку в скрипте запуска кластера hadoop.
Организация техподдержки крупного проекта
Введение
К организации технической поддержки проекта необходимо подойти грамотно. С одной стороны недостаточно просто завести электронный ящик, на который клиенты будут присылать свои вопросы, а вы будете на них отвечать. С другой стороны нельзя сильно углубляться в аспекты ITIL/ITSM, которые могут быть применимы для очень крупных центров технической поддержки, а в случае обычных проектов процесс организации техподдержки будет очень затяжным (в худшем случае, техподдержка так и не будет налажена). Самое главное - это понять зачем нужна служба техподдержки и в том, как она будет организована. В этом заинтересованы все стороны: клиент, заказчик и исполнитель-разработчик.
ТП с точки зрения клиента
Начнем с того, что организация техподдержки подразумевает учет того, что хочет (ожидает) обычный клиент от службы техподдержки. Клиенту важно, чтобы все его вопросы были оперативно и эффективно разрешены. Ответы на свои вопросы он ожидает увидеть в полной, точной и понятной формулировке. А если проблема требует выполнения каких-либо действий со стороны клиента, то он желает получить набор готовых инструкций для выполнения.
ТП с точки зрения исполнителя
С точки зрения разработчика необходимо:
- Определиться с перечнем решаемых вопросов, которые вы будете обрабатывать от клиента через исполнителя/заказчика.
Это могут быть консультации по функционалу или по back-end разработанного решения, по работе с административной частью. Вопросы могут быть как по технической части как самого решения, так и связанные с инфраструктурой (и относится к тому, кто эту инфраструктуру поддерживает). Также это могут быть срочные вопросы, связанные с аудитом производительности и безопасности, или обработка каких-то аварийных ситуаций. Все это стоит зафиксировать, рассмотреть вместе этот круг вопросов и по возможности стараться за него не выходить.
- Определить зоны ответственности - кто, собственно, за что отвечает (особенно, если у вас в процессе участвует больше, чем 2 стороны).
Это могут быть: зоны ответственности по инфраструктуре, по резервным копиям, по тестовой среде, по среде разработки. Если вы размещаете инфраструктуру не на своих ресурсах, то всегда определяйте кто отвечает за код сайта, за само приложение, за его контент.
- Разработать процедуру обращения: кто может обращаться в техподдержку и какими способами.
Например, в компании-заказчике работает 100 тыс. человек и, если к вам, как к разработчику, будет обращаться каждый из этих человек, то техподдержку оказывать будет очень тяжело. От компании должны быть представлены контактные лица, которые будут с вами работать. Также зафиксируйте интерфейсы для обращения (телефон, электронная почта, тикетная система) и выделите наиболее приоритетный и удобный с обеих сторон способ.
- Обозначить процедуры авторизации и уровни доступа по действиям, которые будут связаны с функционированием или кардинальными изменениями в разработанном решении. Если обращение в техподдержку письменное, то авторизация выполняется с помощью логина и пароля. Если по телефону, то у вас должен быть список авторизованных номеров, на которые вы можете сами перезвонить и убедиться, что это действительно уполномоченный человек. Если обращение по электронной почте, то также должен быть список адресов, которые вы считаете авторизованными.
Все вышеперечисленное следует зафиксировать в едином документе под названием, например, регламент работы технической поддержки. Он может быть зафиксирован в виде договора, в виде дополнительного соглашения или в виде просто странички на сайте, с который вы все согласитесь. Главное, чтобы этот регламент был фиксированный, чтобы в случае каких-либо спорных ситуаций не было ощущения, что одна сторона помнит про одни договоренности, а другая - про другие.
Примечание: ресурсоемкие и нетипичные задачи, т.е. задачи, которые не вписываются в рамки описанного регламента, обязательно фиксируйте, выносите в отдельный договор или дополнительное соглашение и выполняйте уже как отдельные работы.
Внутренняя организация техподдержки
Все входящие обращения в техподдержку обязательно должны быть зафиксированы:
- В случае использования тикетной системы все просто: каждому обращению присваивается свой номер.
- Если же обращения поступают по электронной почте, то старайтесь генерировать тикет, чтобы был номер обращения, и желательно, чтобы клиент получал автоответ о принятии его обращения.
- В случае обращения клиента по телефону в техподдержку также следует создавать тикет (многие автоматизированные системы позволяют по телефонному звонку создавать тикет).
При организации техподдержки заранее обозначьте какие данные от клиента вы хотите получить, когда он обращается к вам с вопросом. Чем полнее и корректнее он сформулирует вопрос, тем быстрее он получит на него ответ По типовым вопросам, которые обязательно у вас накопятся со временем, составьте базу знаний и FAQ, сделайте каталогизатор и удобную форму поиска. Обязательно показывайте пользователям вашу базу знаний, чтобы они имели возможность какие-то типовые вопросы решать самостоятельно.
Кроме того, необходимо уделять должное внимание и сотрудникам техподдержки. Они должны обладать грамотной речью, а также хорошей дикцией, если техподдержка оказывается в устном виде. Вам следует прорабатывать сценарии разговоров, шаблоны ответов, чтобы ускорить реакцию на обращение. Желательно, чтобы в техподдержке был руководитель или старший по смене, который проверял бы выборочно ответы сотрудников, контролируя по необходимости отдельные моменты. Также важно регулярно проводить внутренние тестирования с целью определения компетенции сотрудников.
Сотрудник техподдержки должен обладать максимумом информации, чтобы предоставлять клиенту актуальные данные, ориентировать его по срокам решения трудоемких проблем. Поэтому у вас должны быть созданы внутренние регламенты по взаимодействию сотрудников техподдержки с другими отделами: системами мониторинга, системными администраторами и разработкой.
Немаловажным аспектом работы службы техподдержки является внутренняя система мотиваций. Оценивать работу сотрудников можно по совокупности или по отдельным критериям, например:
- по количеству обработанных тикетов;
- по количеству просроченных тикетов;
- по количеству ответов, оцененных положительной оценкой;
- по времени решения тикетов;
- по заработанным бонусам за глубокое изучение проблемы и т.д.
Анализируя показатели, вы сможете определить требуются ли изменения в организации работы технической поддержки.
Что же касается технической стороны вопроса, то сейчас очень много тикетных систем, помогающих организовать службу техподдержки. В Bitrix Framework имеется собственный инструмент - модуль Техподдержка, который включает в себя публичный интерфейс для создания обращений, удобную работу с тикетами и их историей и много других возможностей (подробное описание смотрите в главе Техподдержка курса Администратор. Модули).
Примеры и кейсы
Рассмотрим примеры тестирования крупных проектов
Оптимизация работы проекта
Клиент обратился за помощью, чтобы разобраться, почему иногда начинает «тормозить» веб-проект, при этом большую часть времени все хорошо. Дополнительно ситуация усугубляется тем, что доступ к административной части и на сервера клиент дать не может.
Были проведены следующие мероприятия:
- Настроен сбор логов на серверах. При этом обработка awk показала наличие долгих очень медленных хитов.
- Настроен сбор аналитики на серверах проекта, чтобы стало видно, насколько загружены сервера и какой у веб-системы резерв. Результат показал, что система не загружена.
- Установлен XHProf и настроено сохранение трейсов в файлы с административной частью. Результат показал несколько проблемных мест: проблемы с запросами к базе данных, медленный старт сессии.
Таким образом, работа проекта стала прозрачной. Все факты неадекватного поведения фиксируются для дальнейшего анализа. После чего проводятся работы по устранению проблемных мест.
Нагрузочное тестирование веб-кластера
Было проведено нагрузочное тестирование веб-кластера, при котором были получены достаточно хорошие результаты: при нагрузке 25 сайтов одновременно (они в одной базе данных - многосайтовость на веб-кластере), с помощью Яндекс.Танк система уверенно держит ~600 запросов в секунду (52 млн. хитов в сутки) на одной базе данных и трех веб-интерфейсах за балансировщиком при требуемых в ТЗ 300 хитах в сек.
Но при этом были отмечены следующие риски и даны рекомендации:
- Нагрузка проводилась всего 15 минут, а рекомендуется не менее суток, поскольку:
- периодическая, раз в N часов (по-разному), активность пула буферов InnoDB по вытеснению измененных страниц на диск может потребовать донастройки либо серьезно замедлит скорость работы кластера;
- крон-задачи в операционных системах серверов могут выполняться ночью (и не только) и способны вызывать коллапс, если заранее не позаботиться;
- аналогично с агентами Bitrix Framework.
- Очень мало свободной памяти на БД, а при нагрузке она довольно интенсивно наполняется. Таким образом, скоро БД перестанет помещаться в ОЗУ и начнет работать очень медленно. Рекомендуется увеличить ОЗУ до такого значения, при котором БД поместится в него - до 32/64 ГБ и выше. Конечно, делать это нужно при наличии технической возможности, но для такого крупного проекта это лучше не откладывать.
- По результатам нагрузки непонятно, какие типы запросов выполнялись к базе данных – выборки, обновления, вставки или удаления. Рекомендуется протестировать, как выполняются обновления.
- Рекомендуется провести тестирование с подключенным slave-сервером БД.
Технический бриф
В процессе общения с клиентом были выявлены следующие проблемы в работе проекта: зависание сессии, периодически система работает медленно, проблемы с работой административной части, скопилось много файлов. При этом никаких систем аналитики на проекте нет.
Предприняты были следующие меры:
- Высланы рекомендации, какое программное обеспечение установить, куда и зачем.
- Выслан вопросник с заданиями - что нужно сделать с логами и т.п.
- Отдельно был запрошен лог медленных запросов к базе данных и собрана статистика.
Все это делалось для того, чтобы сделать систему клиента прозрачной для анализа, чтобы рекомендовать, как настроить все их сервера, чтобы затем обсудить список приоритетных проблем, совместно найти корень каждой и устранить причину.
Использование облачных технологий
Использование облаков особо актуально для высоконагруженных проектов. К этому предрасполагают следующие ключевые особенности "облачных систем":
- эластичность - позволяет гибко масштабироваться и менять объемы требуемых ресурсов. Возможны варианты автоматического изменения потребляемых ресурсов в зависимости от нагрузки;
- надежность - использование разнесенных независимых дата-центров, автоматическое резервное копирование данных и прочее позволяет повысить отказоустойчивость системы;
- стоимость - расчет производится только от фактически потребленных ресурсов.
Эти характеристики позволяют получить услуги с высоким уровнем доступности и низкими рисками неработоспособности, обеспечить быстрое масштабирование вычислительной системы благодаря эластичности без необходимости создания, обслуживания и модернизации собственной аппаратной инфраструктуры.
Ссылки по теме:
- Облачные вычисления, краткий обзор или статья для начальника (habrahabr.ru)
Архитектура облаков
По модели развертывания "облака" можно разделить на следующие категории:
- Публичные;
- Частные;
- Общественные;
- Гибридные.
Wikipedia
Частное облако (private cloud) – инфраструктура, предназначенная для использования одной организацией, включающей несколько потребителей (например, подразделений одной организации), возможно также клиентами и подрядчиками данной организации. Оно может находиться в собственности, управлении и эксплуатации как самой организации, так и третьей стороны (или какой-либо их комбинации), и оно может физически существовать как внутри, так и вне юрисдикции владельца.
Публичное облако (public cloud) – инфраструктура, предназначенная для свободного использования широкой публикой. Публичное облако может находиться в собственности, управлении и эксплуатации коммерческих, научных и правительственных организаций (или какой-либо их комбинации). Оно физически существует в юрисдикции владельца — поставщика услуг.
Общественное облако (community cloud) – вид инфраструктуры, предназначенный для использования конкретным сообществом потребителей из организаций, имеющих общие задачи (например, миссии, требований безопасности, политики, и соответствия различным требованиям). Оно может находиться в кооперативной (совместной) собственности, управлении и эксплуатации одной или более из организаций сообщества или третьей стороны (или какой-либо их комбинации), и оно может физически существовать как внутри, так и вне юрисдикции владельца.
Гибридное облако (hybrid cloud) – это комбинация из двух или более различных облачных инфраструктур (частных, публичных или общественных), остающихся уникальными объектами, но связанных между собой стандартизованными или частными технологиями передачи данных и приложений (например, кратковременное использование ресурсов публичных облаков для балансировки нагрузки между облаками).
Архитектура облака Битрикса
Архитектура облака Битрикса
Рассмотрим архитектуру сервиса Битрикс24 как пример реализации объемного проекта на базе Bitrix Framework.
В процессе разработки самой идеи сервиса было сформулировано несколько бизнес-задач:
- Первый тариф на Битрикс24 должен быть бесплатным, то есть себестоимость такого бесплатного аккаунта должна быть очень низкой.
- Сервис - это бизнес-приложение, и, значит, нагрузка на него будет очень неравномерной: больше днем, меньше ночью. В идеале оно должно масштабироваться (в обе стороны) и в каждый момент времени использовать ровно столько ресурсов, сколько нужно.
- При этом для любого бизнес-приложения крайне важна надежность: постоянная доступность данных и их сохранность.
- Сервис должен работать сразу на нескольких рынках: Россия, США, Германия.
Исходя из этих бизнес-требований сформировались два больших фронта работ:
- формирование масштабируемой отказоустойчивой платформы разработки,
- выбор технологической платформы для инфраструктуры проекта.
Платформа разработки Bitrix Framework
 | Традиционное устройство веб-приложений очень плохо масштабируется и резервируется. В лучшем случае возможно разнести по разным серверам само приложение, кэш и базу. Можно как-то масштабировать веб (но при этом необходимо решить вопрос синхронизации данных на веб-серверах). Кэш и база масштабируются уже хуже. А о распределенном гео-кластере (для резервирования на уровне датацентров) речь вообще не идет. |
Платформа "1С-Битрикс" включает в состав модуль Веб-кластер, который обладает следующими возможностями:
- Вертикальный шардинг (вынесение отдельных модулей на отдельные серверы MySQL),
- Репликация MySQL и балансирование нагрузки между серверами на уровне ядра платформы,
- Распределенный кеш данных (memcached),
- Непрерывность сессий между веб-серверами (хранение сессий в базе данных),
- Кластеризация веб-сервера,
- Поддержка облачных файловых хранилищ, которая решает проблему синхронизации статического контента,
- Поддержка master-master репликации в MySQL, позволяющая строить географически распределенные веб-кластеры.
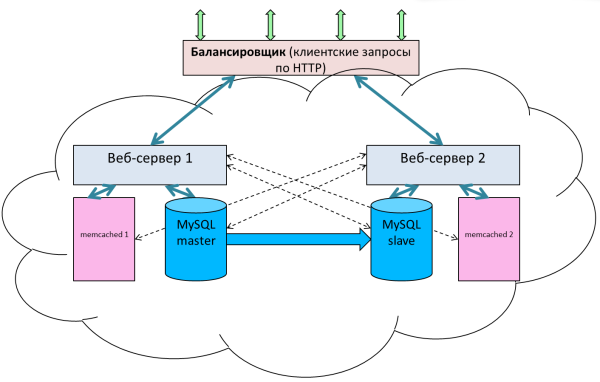
Модуль Облачные хранилища решает проблему синхронизации статического контента.
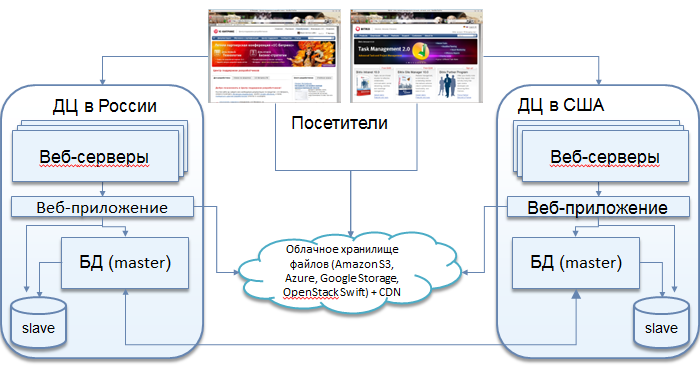
То есть штатные инструменты платформы Bitrix Framework позволяют без дополнительных усилий получить базовый функционал сервиса. То есть вопрос программной платформы был решён.
Платформа для разворачивания инфраструктуры
Собственное или арендуемое оборудование требует достаточно серьезных вложений в инфраструктуру на старте проекта. Масштабировать физические сервера достаточно сложно (долго и дорого). Администрировать (особенно в разных ДЦ) - неудобно. Кроме этого необходимо создание всех сопутствующих сервисов "с нуля".
На этапе старта невозможно максимально полно оценить те объемы регистраций, приток новых клиентов. Не хотелось покупать лишнее оборудование и переплачивать за него. Хотелось платить только за реальное потребление. Хотелось прийти к схеме, которая балансировалась не с пиками нагрузки в течение месяца, а в течение дня. Пик идёт днём: мы добавили нужное число машин, ночью отключили. В результате платим только за реальное потребление.
Поэтому было выбрано "облачное" размещение.
Сайты компании 1С-Битрикс работают в Amazon AWS достаточно давно. Это "облако" удобно тем, что есть множество уже готовых сервисов, которые можно просто брать и использовать в своем проекте, а не изобретать собственные велосипеды: облачное хранилище S3, Elastic Load Balancing, CloudWatch, AutoScaling и многое другое.
В очень упрощенном виде вся архитектура "Битрикс24" выглядит примерно так:

Каждый портал, заведённый в Битрикс24 имеет собственную базу внутри MySQL. На одном сервере может быть размещено до 30000 баз данных. Битрикс24, по сути, очень похож на shared hosting, когда на одном сервере размещено достаточно много баз данных клиентов, создающих разную нагрузку. В этих условиях очень важно обеспечить высокое качество работы для всех клиентов, которые там размещаются.
В такой архитектуре главный минус - избыточность приложения, это дорого по ресурсам.
Плюсы такой архитектуры
- Безопасное решение: каждый портал максимально изолирован друг от друга.
- Гибкое решение в плане обновления продукта: возможна выборочная установка обновлений в нужные "пакеты" порталов, можно вносить те или иные изменения в схемы данных по отдельным порталам, а не по всему проекту в целом.
Опытным путём выяснилось, что удобнее использовать 4 инстанса на одном сервере. И на каждый инстанс выделять по два отдельных диска, без Raid, один диск для данных, второй - для логирования. В итоге получается 8 дисков: 4 с данными, 4 диска под binlog'и. Такая конфигурация значительно лучше утилизирует ресурсы сервера, более эффективная нагрузка на каждый диск.
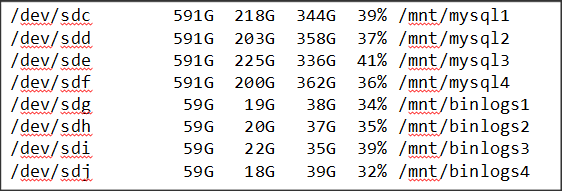
Вынос binlog'ов на отдельный диск вызван тем, что использование отдельного диска не затрагивает производительность дисков с данными. Это позволяет достаточно часто производить записи в лог, то есть логировать большее число параметров и действий.
Сам MySQL в плане производительности и эффективности работает с 30000 базами на 4-х инстансах лучше, чем на одном "большом" инстансе.
Автоматическое масштабирование
Приложение (веб) масштабируется в проекте не вертикально (увеличение мощности сервера), а горизонтально (добавление новых машин).
Для этого используется связка Elastic Load Balancing + CloudWatch + Auto Scaling. Все клиентские запросы (HTTP и HTTPS) поступают на один или несколько балансировщиков Amazon (Elastic Load Balancing). Рост и снижение нагрузки отслеживается через CloudWatch. AutoScaling добавляет и удаляет машины.
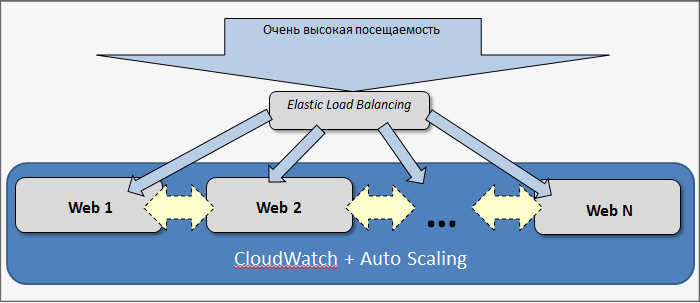
Есть две интересные метрики:
- состояние нод EC2 (% CPU Utilization). (Средняя нагрузка на сервера, которые участвуют в балансировке.)
- состояние балансировщика (время ответа от сервера latency в секундах).
В качестве основной характеристики используются данные о загрузке машин (EC2), так как latency может варьироваться не только из-за реальной нагрузки, но и по каким-то иным причинам: сетевые задержки, ошибки в приложении и другим. В таком случае возможны «ложные» срабатывания, и тогда крайне неэффективно будут добавляться новые машины.
В процессе разработки сервиса проводились долгие эксперименты с разными пороговыми значениями. В результате выбраны следующие: автоматически стартуют новые машины, если EC2 превышает 60% в течение 5 минут, и автоматически останавливаются и выводятся из эксплуатации, если средняя нагрузка менее 30%. Если верхний порог ставить больше (например, 70-80%), то начинается общая деградация системы - пользователям работать некомфортно (долго загружаются страницы). Нижний порог меньше — система балансировки становится не очень эффективной, машины долго могут работать вхолостую.

Специфика веб-нод
При проектировании возникло несколько задач, которые необходимо было решить:
- На веб-нодах не должно быть пользовательского контента, все ноды должны быть абсолютно идентичны.
- Read only. Никакие пользовательские данные не пишутся и не сохраняются на веб-нодах, так как в любой момент времени любая машина может быть выключена или стартует новая из «чистого» образа.
- При этом необходимо обеспечить изоляцию пользователей друг от друга.
Решилось это следующим образом: выбрана конфигурация без Apache. Есть только PHP-FPM + NGINX. У каждого клиента создаётся свой домен.И создан новый модуль для PHP который:
- проверяет корректность домена, завершает хит с ошибкой, если имя некорректно
- устанавливает соединение с нужной базой в зависимости от домена
- обеспечивает безопасность и изоляцию пользователей друг от друга
- служит для шардинга данных разных пользователей по разным базам
Статический контент пользователей
В описанной выше схеме веб-ноды по сути становятся «расходным материалом». Они могут в любой момент стартовать и в любой момент гаситься. А это значит, что никакого пользовательского контента на них быть не должно, он должен храниться либо в базе данных, либо в облачном хранилище. А на серверах должны в лучшем случае использоваться только временные файлы и директории.
Именно поэтому при создании каждого нового портала в Битрикс24 для него создается персональный аккаунт в Амазоне для хранения данных в S3. Тем самым данные каждого портала полностью изолированы друг от друга.
При этом само хранилище S3 очень надежно:
- Данные в S3 реплицируются в несколько точек. При этом – в территориально распределенные точки (разные датацентры).
- Каждое из устройств хранилища мониторится и быстро заменяется в случае тех или иных сбоев.
- Обычно данные реплицируются в три и более устройств – для обеспечения отказоустойчивости даже в случае выхода из строя двух из них.
- Когда вы загружаете новые файлы в хранилище, ответ об успешной загрузке вы получите только тогда, когда файл будет полностью сохранен в нескольких разных точках.
Амазон, например, говорит о том, что их архитектура S3 устроена таким образом, что они готовы обеспечить доступность на уровне двух девяток после запятой. А вероятность потери данных – одна миллиардная процента. Информации о потерянных данных в облаке Амазона пока ещё никто не обнародовал.
Два дата-центра и master-master репликация
Сервис Битрикс24 сейчас размещается в шести дата-центрах: по два в России, в Европе и в Америке. Этим решаются сразу три задачи: во-первых, распределяется нагрузка, во-вторых, резервируются все сервисы - в случае выхода из строя одного из ДЦ, траффик просто переключается на другой, в-третьих выполняются требования европейского и российского законодательства.
База в каждом ДЦ является мастером относительно слейва во втором ДЦ и одновременно слейвом - относительно мастера.
Важные настройки в MySQL для реализации этого механизма: auto_increment_increment и auto_increment_offset. Они задают смещения значений для полей auto_increment для того, чтобы избежать дублирования записей. Грубо говоря, в одном мастере - только четные ID, в другом - только нечетные.
Каждый портал (все зарегистрированные в нем сотрудники), заведенный в Битрикс24 в каждый конкретный момент времени работает только с одним ДЦ и одной базой. Переключение на другой ДЦ осуществляется только в случае какого-либо сбоя.
Базы в разных дата-центрах синхронны, но при этом независимы друг от друга: потеря связности между ДЦ может составлять часы, данные синхронизируются после восстановления.
Надежность
Одним из важнейших приоритетов при проектировании сервиса "Битрикс24" была постоянная доступность сервиса и его отказоустойчивость.
В случае аварии на одной или нескольких веб-нодах Load Balancing определяет вышедшие из строя машины и, исходя из заданных параметров группы балансировки (минимально необходимое количество запущенных машин), автоматически восстанавливается нужное количество инстансов.
Если теряется связность между дата-центрами, то каждый дата-центр продолжает обслуживать свой сегмент клиентов. После восстановления связи, данные в базах автоматически синхронизируются.
Если же выходит из строя полностью дата-центр, или же, например, происходит сбой на базе, то весь трафик автоматически переключается на работающий дата-центр.
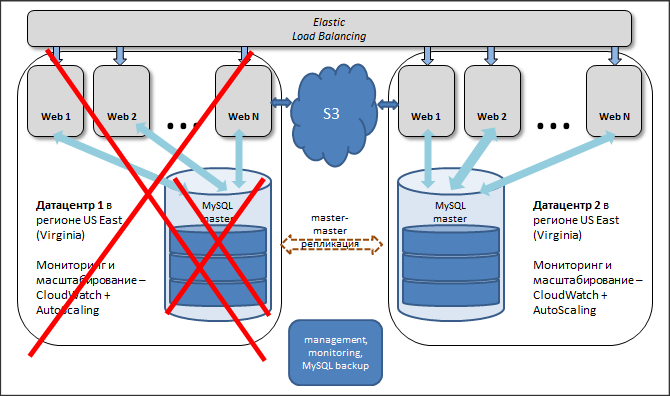
Если это вызывает повышенную нагрузку на машины, то CloudWatch определяет возросшую утилизацию CPU и добавляет нужное количество машин уже в одном дата-центре в соответствие с правилами для AutoScaling.
При этом приостанавливается мастер-мастер репликация. После проведения нужных работ (восстановительных - в случае аварии, или плановых - например, точно по такой же схеме был осуществлен переход со стандартного MySQL на Percona Server (см. далее) - при этом без какого-либо downtime'а для пользователей сервиса) база включается в работу и восстанавливается репликация.
Если все прошло штатно, трафик снова распределяется на оба дата-центра. Если при этом средняя нагрузка стала ниже порогового значения, то лишние машины, которые поднимались для обслуживания возросшей нагрузки, автоматически отключаются.
Базы данных
Для хранения данных в базе рассматривалось несколько разных вариантов.
Первым кандидатом на использование в проекте был Amazon Relational Database Service (Amazon RDS) - облачная база данных. Есть поддержка MS SQL, Oracle и, главное, MySQL.
Сервис хороший, но оказался неподходящим для конкретного проекта.
| Причины: |
|---|
|
Рассмотрев еще несколько вариантов, было решено начать со стандартного MySQL. На этапе проектирования и закрытого бета-тестирования сервиса попутно рассматривались различные форки. Самими интересными, на наш взгляд, оказались Percona Server и MariaDB.
В итоге, в качестве основного сервера баз данных, для проекта была выбрана Percona Server.
Ключевые особенности, которые оказались важны для проекта:
- Percona Server оптимизирован для работы с медленными дисками. И это очень актуально для "облака" - диски там почти всегда традиционно медленнее (к сожалению), чем обычные диски в "железном" сервере. Проблему неплохо решает организация софтверного рейда (мы используем RAID-10), но и оптимизация со стороны серверного ПО - только в плюс.
- Рестарт базы (при большом объеме данных) - дорогая долгая операция. В Percona Server есть ряд особенностей, которые позволяют делать рестарт гораздо быстрее - Fast Shut-Down, Buffer Pool Pre-Load. Последняя позволяет сохранять состояние буфер-пула при рестарте и за счет этого получать "прогретую" базу сразу после старта (а не тратить на это долгие часы).
- Множество счетчиков и расширенных отчетов (по пользователям, по таблицам, расширенный вывод SHOW ENGINE INNODB STATUS и т.п.), что очень помогает находить, например, самых "грузящих" систему клиентов.
- XtraDB Storage Engine - обратно совместим со стандартным InnoDB, при этом гораздо лучше оптимизирован для высоконагруженных проектов.
Примечание: Полный список можно посмотреть на сайте в разделе Percona Server Feature Comparison.
Еще одним важным моментом было то, переход со стандартного MySQL на Percona Server вообще не потребовал изменения какого-либо кода или логики приложения.
В качестве системы хранения данных в MySQL была выбрана "улучшенная версия" InnoDB - XtraDB:
- На долгих запросах в MyISAM лочится вся таблица. В InnoDB - только те строки, с которыми работаем. Соответственно, в InnoDB долгие запросы в меньшей степени влияют на другие запросы и не отражаются на работе пользователей.
- На больших объемах данных и при высокой нагрузке таблицы MyISAM "ломаются". Это - известный факт. В нашем сервисе это недопустимо.
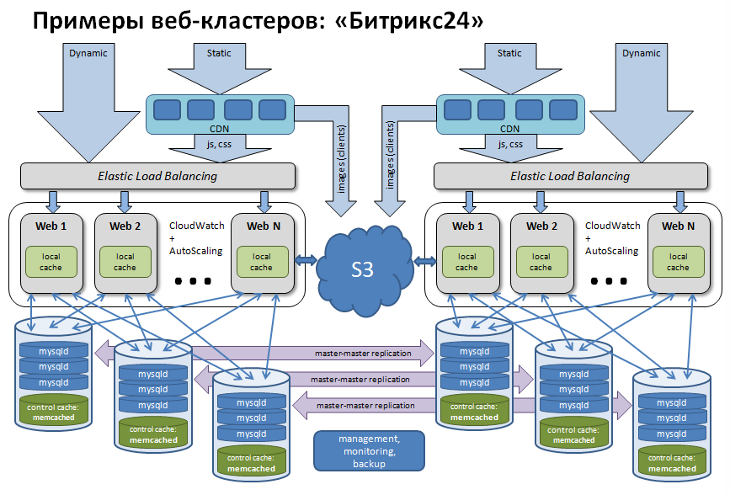
Материалы по теме
Архитектура частного облака в Амазоне
Архитектура частного облака в Амазоне
Amazon Virtual Private Cloud (Amazon VPC) позволяет организовать приватные изолированные сети в публичном облаке Amazon. Amazon VPC предоставляет полный контроль над сетевой средой, включая выбор собственного диапазона адресов, создание подсетей, и конфигурации таблиц маршрутизации и сетевых шлюзов.
Также Amazon VPC позволяет легко настроить сетевую конфигурацию. Например, можно создать публичную подсеть для фронтэнд веб-серверов, которая будет иметь доступ к Интернету, и разместить бэкэнд (базы данных или серверы приложений) в частной подсети без доступа в Интернет.
Система позволяет использовать несколько уровней безопасности, включая группы безопасности и списки контроля доступа к сети, для упрощения управления доступом к Amazon EC2 для каждой подсети.
Кроме того, можно создать VPN подключение (Hardware Virtual Private Network) между корпоративной сетью и вашей Amazon VPC и использовать "свое облако" как расширение корпоративной сети.
Примечание: Подробнее про сервис можно посмотреть на официальном сайте.
Пример
Рассмотрим небольшой схематичный пример использования Amazon VPC для организации работы веб-приложения в нем с доступом клиента из его локальной сети через VPN.
С точки зрения Amazon, выделение частного облака начинается с создания VPC (CIDR /16) и его разбиения на более мелкие подсети. Затем с подсетями работают остальные технологии частного облака: файерволы, шлюзы, балансировщики, роутеры, соединения VPN и т.д.
Сущности
Для создания и работы "частного облака" с доступом по VPN могут потребоваться следующие сущности:- Внутренний балансировщик - балансировщик, который закрыт из интернета и доступен из локальной сети клиента, соединенной с подсетью через VPN.
- ACL (списки контроля доступа) для подсетей - используются и настраиваются дополнительно к группам безопасности (Security Groups) для изоляции подсетей друг от друга.
- Таблицы маршрутизации - используются для направления трафика из/в подсети. В частности для VPN, NAT или доступа к Интернет-шлюзу.
- Интернет-шлюз - потребуется для организации доступа из подсети в интернет. Например, для обновления виртуальных машин и софта на них.
- VPN-шлюз - чтобы "облако" было доступно в "локалке". Другими словами позволяет соединить локальную подсеть с выделенной подсетью в Amazon.
Организация облака клиента в Амазоне
-
Создаем VPC - одну на всех
Облако клиента начинается с его изолированной подсети в Amazon с машинами и другими объектами инфраструктуры. Облако соединяется с локальной сетью компании клиента через VPN-шлюз. Создаем сначала один раз VPC для всех клиентов - 10.0.0.0/16.
Важно при создании VPC активировать использование DNS-сервера Amazon для внутренних и внешних IP-адресов.
-
Создаем подсети для каждого клиента
Затем делим VPC на подсети /26 для каждого клиента - меньше подсеть создать нельзя, т.к. внутренний балансировщик работает только с подсетями больше /27 и в подсети должно быть не меньше свободных 20 адресов (а также резервируется 4 начальных адреса и один последний).
Подсеть создается только внутри одной AZ (датацентра), поэтому нужно для каждого клиента создать 2 подсети - по одной в каждом ДЦ. Изолировать подсети клиентов можно через ACL, которые работают на уровне подсетей.
-
Доступ для администрирования облака (обновление софта в подсетях, доступ на машины)
Для того чтобы иметь возможность обновлять софт на машинах клиентов в каждой из двух подсетей, нужно организовать доступ из подсетей в интернет.
Есть 2 пути:- Установка интернет-шлюз и назначение машинам EIP-адреса
- Установка NAT-сервер (стандартная возможность) и машины ходят в интернет через него
С точки зрения повышения безопасности правильнее вариант 2 - чтобы на машины не было прямого доступа через интернет, даже с определенных адресов. Также придется поднять еще один VPN-шлюз Amazon и ходить в "облака" клиентов через него.
-
Доступ для клиента
Чтобы клиент мог получать доступ к веб-приложению, которое находится в "частном облаке", по привычному URL без установки на свои ПК клиентской части VPN - необходимо настроить тоннель через маршрутизатор на стороне клиента и на стороне Amazon.
Для Amazon это стандартная возможность. Для клиента же придется произвести соответствующие настройки в его среде.
-
Балансировщик для клиента
Для отказоустойчивости, масштабируемости при нагрузке и переключении автоматическом при аварии ДЦ - можно настроить внутренний балансировщик, обслуживающий 2 подсети "облака клиента" в двух датацентрах.
Естественно, в "облаке" уже должна быть собрана и настроена инфраструктура автоматического масштабирования и управления нагрузкой.
Материалы по теме
- Amazon VPC (Amazon.com, описание сервиса, ENG)
- Amazon Virtual Private Cloud (Wikipedia, ENG)
- What is Amazon VPC?
- How Amazon VPC works
- AWS Insight: Virtual Private Cloud (habrahabr.ru)
Облако Амазон
Облако Амазон
Amazon Web Services (AWS) — инфраструктура сервисов в облаке, представленная компанией Amazon (Амазон) в начале 2006 года. В данной инфраструктуре представлено много сервисов для предоставления различных услуг, таких как: хранение данных (файловый хостинг, распределённые хранилища данных), аренда виртуальных серверов, предоставление вычислительных мощностей и прочее.
В состав Amazon Web Services входят наиболее востребованные сервисы для организации различных бизнес-решений в одном месте (облаке).
Список некоторых интересных сервисов AWS:
- Amazon Elastic Compute Cloud (Amazon EC2) – веб-сервис, который предоставляет вычислительные мощности;
- CloudWatch – сервис мониторинга состояния всех сервисов AWS;
- Elastic Load Balancing – балансировщик нагрузки для Amazon EC2 c автомасштабированием;
- Amazon Simple Storage Service (Amazon S3) – облачное хранилище (файловый хостинг);
- CloudFront – сервис доставки и дистрибуции контента (CDN);
- Auto Scaling – сервис, позволяющий динамически повышать/понижать вычислительные мощности (количество «машин» Amazon EC2), например, в зависимости от нагрузки;
- Amazon Relational Database Service (RDS) – распределённая реляционная база данных. Есть поддержка MS SQL, Oracle и MySQL.
За всей технологичностью сервисов скрывается простота и легкость управления. Амазон сделали действительно, по сравнению с «не облачным» набором сервисов и услуг, платформу для быстрого и удобного разворачивания бизнес-решений.
Доступность и надежность
В плане глобальной инфраструктуры, дата-центры Амазон расположены в различных географических точках мира.

Дата-центры, расположенные в какой-либо одной точке мира, у Амазон называются «регионом» (Region). На данный момент имеются 9 регионов:
- США – северная Вирджиния, US-East (Northern Virginia);
- США – северная Калифорния, US-West (Northern California);
- США – Орегон, US-West (Oregon);
- Европа – Ирландия, EU (Ireland);
- Азия – Сингапур, Asia Pacific (Singapore);
- Австралия – Сидней, Asia Pacific (Sidney);
- Азия – Токио, Asia Pacific (Tokyo);
- Южная Америка – Сан-Паулу, South America (Sao Paulo);
- Европа – Франкфурт, EU (Frankfurt).
В свою очередь, каждый регион делится на «зоны доступности» (Availability Zone). Зона доступности – это конкретное физическое местоположение внутри региона, спроектированное таким образом, чтобы оно было изолировано от проблем в других зонах в том же регионе (т.е. выход из строя оборудования в одной зоне никак не повлияет на работоспособность оборудования в других зонах), и в то же время между зонами одного региона существует быстрое высокоскоростное сетевое соединение.

Такое построение инфраструктуры позволяет, например, сделать свой сервис ближе для целевой аудитории, расположив его в том же регионе. Для обеспечения максимального уровня отказоустойчивости сервиса, его можно расположить в разных зонах доступности (на случай проблем в одной конкретной зоне доступности).
Еще одна отличительная особенность сервисов от Амазон – это надежность. Большинство высокоуровневых сервисов Амазон имеют встроенные механизмы для обеспечения отказоустойчивости и высокой доступности. Также Амазон позволяет делать логический и физический бэкап данных на случай аварии.
Например, для сервиса Amazon S3 гарантируется 99.99999999% сохранности данных и их 99,99% доступности в течение года.
Материалы по теме
- Резервное копирование в Amazon Web Services
- Популярно об Amazon Web Services
- Документация Amazon Web Services (ENG)
- Варианты построения высокодоступных систем в AWS. Преодоление перебоев в работе. Часть 1.
- Варианты построения высокодоступных систем в AWS. Преодоление перебоев в работе. Часть 2.
- Регионы и Зоны доступности
MySQL и облако
MySQL и облако
Облачные базы данных — это базы данных, которые запускаются на платформах облачных вычислений, таких как Amazon EC2, GoGrid и Rackspace. Существуют две распространенные модели развертывания: пользователи могут приобрести непосредственно услугу доступа к базам данным, обслуживаемым поставщиком облачного сервиса, или же запустить базы данных в облаке независимо, используя образ виртуальной машины. Среди облачных баз данных присутствуют как SQL-ориентированные, так использующие модель данных NoSQL.
В общем, MySQL в "облаке", по своей сути мало отличается от "не облачной" версии.
Поэтому при настройке базы, отладке производительности и ее мониторинге нужно руководствоваться общими принципами, за исключением некоторых нюансов облака, про которые будет описано ниже.
Например, при использовании образов виртуальных машин в "облаках", в качестве основного сервера баз данных вместо обычного MySQL можно использовать его форк Percona Server:
- Percona Server оптимизирован для работы с медленными дисками. И это очень актуально для "облака" - диски там почти всегда традиционно медленнее (к сожалению), чем обычные диски в "железном" сервере. Проблему неплохо решает организация софтверного рейда, но и оптимизация со стороны серверного ПО - только в плюс.
- Рестарт базы (при большом объеме данных) - дорогая долгая операция. В Percona Server есть ряд особенностей, которые позволяют делать рестарт гораздо быстрее - Fast Shut-Down, Buffer Pool Pre-Load. Последняя позволяет сохранять состояние буфер-пула при рестарте и за счет этого получать "прогретую" базу сразу после старта (а не тратить на это долгие часы).
- Множество счетчиков и расширенных отчетов (по пользователям, по таблицам, расширенный вывод SHOW ENGINE INNODB STATUS и т.п.), что очень помогает находить, например, самых "грузящих" систему клиентов.
- XtraDB Storage Engine - обратно совместим со стандартным InnoDB, при этом гораздо лучше оптимизирован для высоконагруженных проектов.
Примечание: Полный список можно посмотреть на сайте в разделе Percona Server Feature Comparison.
В качестве же системы хранения данных в MySQL также можно использовать "улучшенную версию" InnoDB - XtraDB:
- На долгих запросах в MyISAM блокируется вся таблица. В InnoDB - только те строки, с которыми работаем. Соответственно, в InnoDB долгие запросы в меньшей степени влияют на другие запросы и не отражаются на работе пользователей.
- На больших объемах данных и при высокой нагрузке таблицы MyISAM "ломаются". Это - известный факт.
В облаке, так же, как и для обычного MySQL, для серьезных проектов, можно и нужно использовать репликацию.
В качестве мониторинга и аналитики, в дополнение к тому, что предлагает сам облачный провайдер, можно использовать все те же привычные сервисы, которые используются в случае "не облака": nagios, munin и прочие.
При использовании "облаков" все-таки существуют некоторые нюансы. Например, стоит упомянуть проблему скорости.
Самое простое в этом случае - организовать RAID. Например, Amazon позволяет организовать "софтварный" рейд довольно просто, который работает долго и практически не ломается.
Также стоит отметить, что если "облако" позволяет, то можно использовать специальные быстрые диски. У Amazon, например, есть диски с Provisioned IOPS.
Примечание: Подробнее про использование облачных "дисков" и бэкап на них, включая Инкрементальный бэкап MySQL, можно посмотреть в следующей статье.
Немного теории про облачные базы данных
Модель развертывания
Существует два основных метода запуска базы данных в "облаке":
- Непосредственно через образ виртуальной машины. Облачные платформы позволяют приобретать виртуальные машины, где возможно запускать базы данных. Пользователи могут загружать свои образы с уже установленной базой или же воспользоваться готовыми, где установлен уже оптимизированный экземпляр.
- База данных, как сервис - некоторые облачные платформы предлагают уже готовый сервис баз данных, при помощи которого можно обойтись без виртуальной машины. Пользователю не нужно устанавливать и поддерживать базу данных самостоятельно. Заместо этого, поставщик сервиса берет на себя ответственность в установке и обслуживании базы данных.
Например, Amazon Web Services предоставляет три базы данных, входящие в их облачный сервис: Amazon Relational Database Service (SQL-ориентированная база данных с MySQL интерфейсом), DynamoDB.
Так же можно приобрести хостинг базы данных, в случае если база данных не предоставляется как сервис. Например, облачный провайдер Rackspace предлагает такую услугу для баз данных MySQL.
Архитектура и общие характеристики
-
Многие провайдеры к базам данных предоставляют веб-интерфейс, при помощи которого пользователи могут устанавливать и настраивать экземпляры баз данных.
Например, веб-консоль Amazon Web Services позволяет запускать экземпляры баз данных, создавать снепшот и следить за статистикой. - Так же предлагается компонент управления базами данных, который контролирует основную базу данных, используя специальное API сервиса. API открыто для пользователя и позволяет ему выполнять обслуживание и масштабирование своих экземпляров баз данных.
- Сервис делает прозрачным для пользователя весь стек программного обеспечения, который используется для поддержания работоспособности базы. Обычно он включает в себя операционную систему, саму систему управления базами данных и стороннее программное обеспечение, используемое в работы. Поставщик услуг берет на себя ответственность за установку, исправление и управление данным программным обеспечением.
- Сервис берет на себя масштабируемость и доступность базы данных. Причем особенности масштабируемости различаются у разных поставщиков — кто-то это делает автоматически, а другие позволяют пользователю производить расширение при помощи API. Также провайдеры обычно гарантируют высокую доступность сервиса (около 99,9 % или 99,99 %).
Источник: Wikipedia
Материалы по теме
Облачные сервисы: резервное копирование, ускорение сайта и другие
Использование "облака" является не только модным трендом, но может приносить реальную пользу для проектов. В продуктах Bitrix Framework имеется целый ряд таких "облачных" сервисов которые на практике приносят пользу:
Ускорение сайта CDN
CDN "1С-Битрикс":
Внимание! С версии 22.100.0 модуля Облачные хранилища (bitrixcloud) отключён функционал продукта «Ускорение сайта CDN».
Облачные хранилища
Облачные хранилища позволяют перенести хранение файлов вместо локального сервера веб-сайта в "облака".
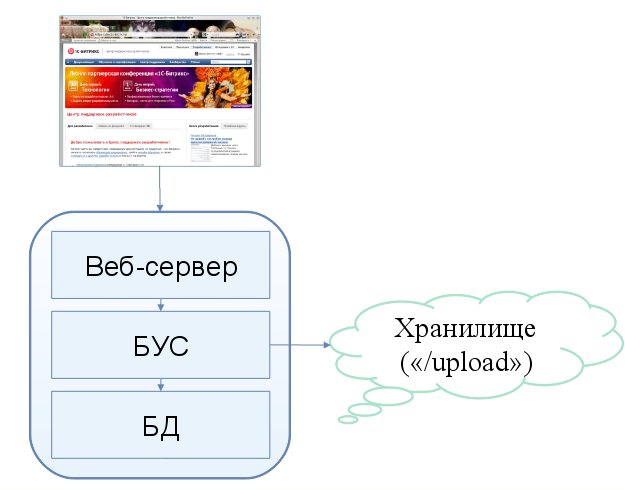
Выгоды от использования облачных хранилищ:
- Экономическая целесообразность. Размещение данных "в облаках" намного дешевле стандартного хранения.
- Доступность данных. Ваши данные всегда доступны для клиентов независимо от их местонахождения.
- Скорость доставки контента. Почти все провайдеры облачных хранилищ предлагают клиентам CDN (Content Delivery Network).
- Снижение нагрузки на сервера. Процессы веб-сервера не заняты отдачей статики, снижается нагрузка на диск.
- Защита от потери данных. Файлы никогда не потеряются, если выбрать тарифный план с соответствующей гарантией.
Примечание: Подробнее про облачные хранилища можно прочитать в соответствующей главе учебного курса.
Резервное копирование в облачное хранилище
Основные особенности резервного копирования в облачное хранилище от "1С-Битрикс":
- Независимость от провайдера - сайт легко перенести;
- Надежность - данные многократно резервируются в облаке;
- Доступность - резервную копию можно развернуть в любом месте;
- Простота - не нужен договор с провайдером, не требуется настройке;
- Безопасность - данные шифруются, даже сотрудники "1С-Битрикс" не имеют к ним доступа.
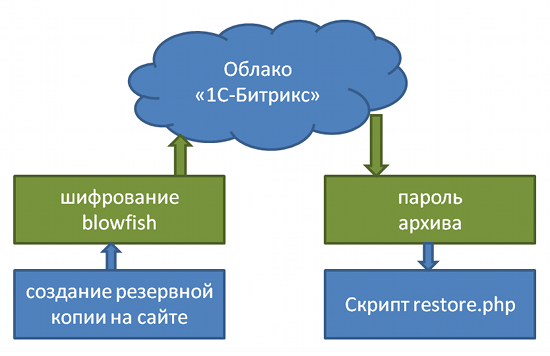
Возможно хранение резервной копии в облачном хранилище, предоставляемое компанией "1С-Битрикс" или же в собственном облачном хранилище.
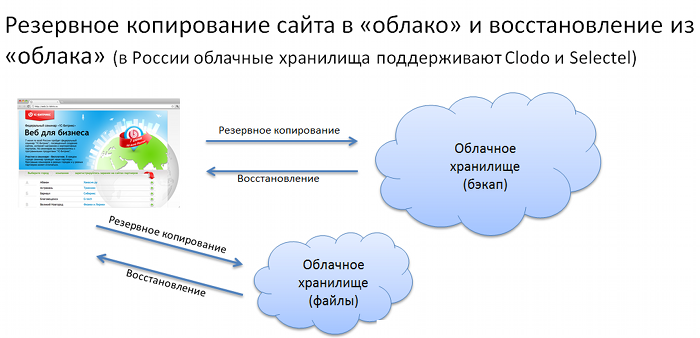
Примечание: Подробнее про создание резервных копий в облако можно прочитать в соответствующем уроке учебного курса.
Инспектор сайтов
Инспектор сайтов периодически проверяет доступность и работоспособность сайта и сообщает обо всех неполадках через E-mail или push-уведомления для мобильных устройств.
Инспектор сайта отслеживает 4 параметра, очень важных для работы любого веб-проекта, и особенно интернет-магазина:
- раз в 5 минут проверяет доступность сайта из двух географических точек;
- раз в день проверяет срок действия домена;
Инспектор сайта напомнит за 30 дней о необходимости продлить домен. Повторяться напоминания будут раз в неделю, пока домен не будет продлен. - раз в день проверяет срок SSL-сертификата;
- раз в день проверяет срок действия лицензионного ключа.
Инспектор сайта напомнит за 30 дней об окончании срока активности обновлений и технической поддержки для вашей лицензии.
Примечание: Подробнее про Инспектор сайтов можно прочитать в соответствующем уроке учебного курса.
Материалы по теме
- Регулярное резервное копирование (Учебный курс "Администратор. Базовый")
Мониторинг облака
Мониторинг сайта
Можно выделить следующие типы мониторинга самого сайта:
Мониторинг доступности - отслеживание того, работает ли он или нет. Наиболее оптимальным для простого мониторинга является десятиминутный интервал: большинство пользователей попытаются вернуться на сайт в течение 1-2 часов, а за это время можно как обнаружить проблемы, так и эффективно их устранить без особого вреда для бизнеса компании.
Мониторинг проблем - отслеживание нескольких параметров сайта с частотой не менее раза в минуту и из нескольких географических точек (чтобы максимально покрыть минутный интервал проверками и установить возможные проблемы, связанные с географией пользователей).
Среди возможных критериев проверки можно выделить проблемы с:
- DNS-сервером (когда в определенные интервалы времени адрес сайта не может быть определен, хотя сам сайт физически доступен);
- большим временем ответа (при обновлении кэша, например, или при выполнении «тяжелых» задач на стороне сервера);
- плановым выполнением задач (в результате которых сайт будет не доступен только в определенные моменты времени);
- большим времени ожидания статических файлов (например, из-за сетевой инфраструктуры или проблем с физическим носителем);
- подключением к базе данных;
- и т.д.
Этот метод особенно хорош, когда требуется отловить какую-то «плавающую» ошибку, а несколько независимых сервисов либо точек проверки позволяют добиться частоты проверки вплоть до раза в 10 секунд - а это более чем достаточно, чтобы обнаружить все, что необходимо.
Мониторинг может быть не долговременным (до обнаружения и исправления проблем) либо периодическим (в целях профилактики проблем).
Мониторинг работоспособности - сюда может относиться любой сложный функционал, который может быть затронут какими-либо изменениями на сайте, например, кабинет интернет-банка. В этом случае необходимо настраивать цепочки проверок либо задавать сложные условия для проведения проверок того или иного функционала сайта.
Мониторинг распределенных систем
При построении отказоустойчивой распределенной инфраструктуры кроме обеспечения нескольких уровней надежности обычно закладывают и несколько уровней мониторинга системы. Среди них можно выделить:
-
Встроенный мониторинг, выдающий данные о физических параметрах серверов (операции с диском, с памятью, загруженность процессора, сети, системы и т.д.).
В качестве решения часто используется Munin с большим набором плагинов, которые позволяют контролировать каждую проблемную точку. Плагины, по сути, — это консольные скрипты, которые проверяют определенный параметр системы с заданной периодичностью. Теоретически, уже на этом уровне можно использовать триггерный механизм, чтобы проводить "разгружающие" действия с сервером. Но на практике для принятия решений используется следующий уровень мониторинга, встроенный мониторинг используется только для сбора статистики и анализа параметров системы "изнутри". -
Внутренний мониторинг подразумевает профилактику состояния всей инфраструктуры или ее части на уровне самой инфраструктуры. Это означает, что наряду с рабочими серверами (приложений, базы данных) в системе должны быть сервера, отслеживающие ее состояние и передающие эту информации (в критических случаях) по адресу (например, рассылающие уведомления по смс, или производящие запуск новых серверов приложений, или записывающие информации о рабочих серверах приложений на балансировщик).
Наиболее часто используемое решение здесь — это Nagios с большим количеством проверок (несколько сотен или тысяч обычно). Дополнительно к нему подключают еще Pinba в случае PHP-приложений для более точного анализа проблем. -
Обычно двух предыдущих уровней мониторинга бывает достаточно для обнаружения и решения всех проблем с инфраструктурой, но часто (в случае использования "облаков") присутствует еще промежуточный мониторинг, когда идет как мониторинг состояния всех серверов инфраструктуры, так анализ всех запросов, проходящих через выделенные в "облаке" мощности.
Промежуточный мониторинг используют как дополнительный уровень контроля качества работы сервиса (например, легко отслеживать количество 500 ошибок, даже если сервера приложений работают в штатном режиме) и принимать решение о переключении мощностей между гео-кластерам (например, такое возможно у Amazon). -
Внешний мониторинг используется для анализа ситуации со стороны пользователей. Даже если система работает исправно, связность между серверами не нарушена, сервера отвечают быстро и стабильно, пользователи могут ощущать проблемы с использованием сервиса, и это будет зависеть от общего состояния Сети.
На этом уровне возможны дополнительные триггеры для принятия решения о переключения пользователей на другие гео-кластеры (например, европейских пользователей вести на европейский датацентр, а американских — на американский) для улучшения качества сервиса. Также этот уровень мониторинга может использоваться для дополнительной проверки результатов внутреннего и промежуточного мониторинга.
Встроенный мониторинг
Munin выдает большое количество информации о состоянии требуемого сервера. К наиболее часто проверяемым моментам относят:
- Проверка PHP (время выполнения, использование памяти, число хитов на 1 процесс и т.д.);
- Проверка NGINX (коды ответов, использование памяти, число процессов);
- Проверка MySQL (число запросов, использование памяти, время выполнение запросов);
- Проверка диска;
- Проверка почтового демона;
- Проверка сети;
- Проверка системы.
Примеры реальной системы (загрузка и база данных) |
|---|
 
 |
Внутренний мониторинг
Nagios как решение для мониторинга безусловно хорош. Но нужно быть готовым к тому, что кроме него придется использовать еще собственные скрипты и (или) Pinba (или аналогичное решения дл вашего языка программирования). Pinba оперирует UDP-пакетами и собирает информацию о времени выполнения скриптов, объеме памяти и кодах ошибок. В принципе, этого достаточно для создания полной картины происходящего и обеспечения требуемого уровня надежности сервиса в автоматическом режиме.
На уровне внутреннего мониторинга уже можно принимать решения о выделении дополнительных мощностей (если это возможно автоматически — то достаточно просто отслеживать средний уровень загрузки процессора на серверах приложений или базы данных, если это производится в ручном режиме — то можно высылать письма или jabber-сообщения) или их отключении. Также в случае возникновения аномального количества ошибок (обычно это происходит при отказе оборудования либо ошибки в новой версии веб-сервиса, и что является причиной, всегда можно установить за счет дополнительных проверок) можно слать уже экстренные уведомления по смс или звонить по телефону.
Также очень удобно настроить автоматическое добавление (или удаление) тестов при увеличении точек проверки (например, серверов ли пользовательских сайтов) с заданными шаблонами: например, проверка главной страницы, распределение времени выполнения PHP, распределение использования памяти для PHP, число nginx и PHP ошибок.
Промежуточный мониторинг
Мониторинг на уровне облачной инфраструктуры предлагает не такое большое количество провайдеров, и он является, скорее, информационным: реальные решения принимаются либо на основе внутренних данных, либо внешнего состояния системы. На промежуточном уровне можно только собирать статистику или подтверждать внутреннее состояние инфраструктуры.
Для Amazon CloudWatch здесь доступны следующие возможности проверки:
- Полный трафик (по инстансам и совокупный);
- Число ответов с балансировщика;
- Состояние инстансов (в том числе и инфраструктурных, которые производят внутренний мониторинг);
- И ряд других, которые можно комбинировать со внутренними, но лучше максимум логики оставить все же на уровне внутреннего мониторинга.
Также можно добавлять свои собственные метрики.
Уже по результатам мониторинга промежуточного (на уровне балансировщиков) можно принимать обоснованное решение о выделении или закрытии машин (инстансов) в кластере.
Внешний мониторинг
Здесь выбор решений очень большой. Если требуется отслеживать состояние серверов по всему миру, то лучшее решение — это Pingdom. Для российских реалий подойдет PingAdmin, Monitorus или WEBO Pulsar. Особенно удобно настроить проверку из нескольких географических точек и дергать удаленный скрипт уведомления, если сервис не доступен в течение 1-2 минут. Если при этом есть какие-либо проблемы внутри, то можно сразу переключаться на план "Б" (выключать неработающие сервера, отсылать уведомления и т.д.).
К дополнительным плюсам внешнего мониторинга можно отнести проверку реального времени ответа на стороне сервера (или реальных сетевых задержек). По этому параметру также можно настроить уведомления. Как дополнительная возможность в случае использования CDN: можно отслеживать полное время загрузки страниц сервиса и отключать или включать CDN для разных регионов.
Мониторинг нетипичных параметров и характеристик
Не стоит забывать и принимать во внимание некоторые нетипичные, но важные параметры, которые тоже необходимо отслеживать:
- Наличие бэкапов;
- Срок делегирования доменов;
- Срок действия SSL сертификатов;
- Баланс у провайдера СМС-уведомлений.
Материалы по теме
Дополнительно
Некоторые дополнительные материалы, которые могут помочь вам при создании и эксплуатации высоконагруженных проектов.
Производительный сетевой сервер на PHP
Производительный сетевой сервер на PHP
В ряде случаев при создании своих проектов имеет смысл не использовать какие-либо фреймворки, сервера и так далее, а написать свой код, например, тот же веб-сервер. Такое решение будет самым оптимальным, так как вы сможете учесть все нюансы именно вашей задачи. Это не сложно, но и не просто. Это требует глубокого понимания как устроена операционная система, какие бывают сетевые протоколы, как правильно взаимодействовать с ядром операционной системы через интерфейс системных вызовов.
Обработкой сетевых сокетов должно заниматься ядро операционной системы и уведомлять вас о наступлении события:
- Пришел новый сокет в слушающем соединении (listen) - и его можно взять в обработку (accept)
- Можно прочитать из сокета, не блокируя процесс (read).
- Можно записать в сокет, не блокируя процесс (write).
На данный момент доминируют другие методы обработки соединений: создаётся куча потоков или процессов (работают медленнее и потребляют значительно больше памяти). Это работает в случаях когда дешевле купить еще одну "железку" чем учить программиста асинхронной обработке демультиплексированных сокетов. Однако когда нужно решить задачу эффективно на текущем оборудовании, сократив издержки на 1-2 порядка, иного способа как научиться понимать суть сетевых процессов и программировать в соответствии с их законами - нет.
Считается, что асинхронная обработка демультипрексированных сокетов - это гораздо сложнее с точки зрения программирования, чем 50 строк в отдельном процессе. Но это не так. Даже на заточенном немного на другие задачи PHP написать быстрый сервер совсем просто.
Рассмотрим пример написания сервера на PHP.
В PHP есть поддержка BSD-сокетов. Но это расширение не поддерживает ssl/tls. Поэтому нужно использовать интерфейс потоков streams. За этим интерфейсом можно увидеть сетевые сокеты и довольно эффективно с ними работать.
Полный исходный код сетевого сервера приводить не будем, отобразим его ключевые части. Сервер устойчиво держит без перекомпиляции PHP до 1024 открытых сокета в одном процессе, занимая около 18-20 МБ и работая в одном процессе операционной системы, загружая "одно" ядро процессора. Если пересобрать PHP, то select может работать с гораздо большим числом сокетов.
Ядро сервера
Задачи ядра сервера:
- Проверить массив заданий
- Для каждого задания создать соединение
- Проверить, что сокет в задании можно прочитать или записать без блокировки процесса
- Освободить ресурсы (сокет и т.п) задания
- Принять соединение от управляющего сокета на добавление задания — без блокировки процесса
То есть в ядро сервера отправляются задания на работу сокетами (например, ходить по сайтам и собирать данные и тому подобное) и ядро в одном процессе начинает выполнять сотни заданий одновременно.
Задание
Задание это объект в терминологии ООП типа FSM. Внутри объекта имеется стратегия. Например: "зайди по этому адресу, создай запрос, загрузи ответ, распарси и т.п. возвраты в начало и в конце запиши результат в NoSQL". То есть можно создать задание от простой загрузки содержимого, до сложной цепочки нагрузочного тестирования с многочисленными ветвлениями - и это все будет жить в объекте задания.
Задания в данной реализации ставятся через отдельный управляющий сокет на 8000 порту - пишутся json-объекты в tcp-сокет и затем начинают свое движение в сервером ядре.
Принцип обработки заданий и сокетов
Главное: не позволить серверному процессу заблокироваться в ожидании ответа в функции при чтении или записи информации в сетевой сокет, при ожидании нового соединения на управляющий сокет или где-нибудь в сложных вычислениях/циклах. Поэтому все сокеты заданий проверяются в системном вызове select и ядро ОС уведомляет нас лишь тогда, когда событие случается (либо по таймауту).
while (true) {
$ar_read = null;
$ar_write = null;
$ar_ex = null;
//Собираемся читать также управляющий сокет, вместе с сокетами заданий
$ar_read[] = $this->controlSocket;
foreach ($this->jobs as $job) {
//job cleanup
if ( $job->isFinished() ) {
$key = array_search($job, $this->jobs);
if (is_resource($job->getSocket())) {
//"надежно" закрываем сокет
stream_socket_shutdown($job->getSocket(),STREAM_SHUT_RDWR);
fclose($job->getSocket());
}
unset($this->jobs[$key]);
$this->jobsFinished++;
continue;
}
//Задания могут "засыпать" на определенное время, например при ошибке удаленного сервера
if ($job->isSleeping()) continue;
//Заданию нужно инициировать соединение
if ($job->getStatus()=='DO_REQUEST') {
$socket = $this->createJobSocket($job);
if ($socket) {
$ar_write[] = $socket;
}
//Задание хочет прочитать ответ из сокета
} else if ($job->getStatus()=='READ_ANSWER') {
$socket = $job->getSocket();
if ($socket) {
$ar_read[] = $socket;
}
//Заданию нужно записать запрос в сокет
} else if ( $job->getStatus()=='WRITE_REQUEST' ) {
$socket = $job->getSocket();
if ($socket) {
$ar_write[] = $socket;
}
}
}
//Ждем когда ядро ОС нас уведомит о событии или делаем дежурную итерацию раз в 30 сек
$num = stream_select($ar_read, $ar_write, $ar_ex, 30);
Далее, когда событие произошло и ОС уведомила нас, начинаем в неблокирующем режиме обработку сокетов. В коде ниже можно еще немного оптимизировать обход массива заданий, индексировать задания по номеру сокета и выиграть примерно 10мс.
if (is_array($ar_write)) {
foreach ($ar_write as $write_ready_socket) {
foreach ($this->getJobs() as $job) {
if ($write_ready_socket == $job->getSocket()) {
$dataToWrite = $job->readyDataWriteEvent();
$count = fwrite($write_ready_socket , $dataToWrite, 1024);
//Сообщаем объекту сколько байт удалось записать в сокет
$job->dataWrittenEvent($count);
}
}
}
}
if (is_array($ar_read)) {
foreach ($ar_read as $read_ready_socket) {
///// command processing
///
//Пришло соединение на управляющий сокет, обрабатываем команду
if ($read_ready_socket == $this->controlSocket) {
$csocket = stream_socket_accept($this->controlSocket);
//Тут упрощение - верим локальному клиенту, что он закроет соединение. Иначе ставьте таймаут.
if ($csocket) {
$req = '';
while ( ($data = fread($csocket,10000)) !== '' ) {
$req .= $data;
}
//Обрабатываем команду также в неблокирующем режиме
$this->processCommand(trim($req), $csocket);
stream_socket_shutdown($csocket, STREAM_SHUT_RDWR);
fclose($csocket);
}
continue;
///
/////
} else {
//Читаем из готового к чтению сокета без блокировки
$data = fread($read_ready_socket , 10000);
foreach ($this->getJobs() as $job) {
if ($read_ready_socket == $job->getSocket()) {
//Передаем заданию считанные данные. Если сокет закроется, считаем пустую строку.
$job->readyDataReadEvent($data);
}
}
}
}
}
}
Сам сокет инициируется также в неблокирующем режиме, важно установить флаги, причем оба! STREAM_CLIENT_ASYNC_CONNECT|STREAM_CLIENT_CONNECT:
private function createJobSocket(BxRequestJob $job) {
//Check job protocol
if ($job->getSsl()) {
//https
$ctx = stream_context_create(
array('ssl' =>
array(
'verify_peer' => false,
'allow_self_signed' => true
)
)
);
$errno = 0;
$errorString = '';
//Вот тут происходит временами блокировочка в 30-60мс, видимо из-за установки TCP-соединения с удаленным хостом, надо глянуть в исходники, но снова ... лень
$socket = stream_socket_client('ssl://'.$job->getConnectServer().':443',$errno,$errorString,30,STREAM_CLIENT_ASYNC_CONNECT|STREAM_CLIENT_CONNECT,$ctx);
if ($socket === false) {
$this->log(__METHOD__." connect error: ". $job->getConnectServer()." ". $job->getSsl() ."$errno $errorString");
$job->connectedSocketEvent(false);
$this->connectsFailed++;
return false;
} else {
$job->connectedSocketEvent($socket);
$this->connectsCreated++;
return $socket;
}
} else {
//http
...
Код самого задания: оно должно уметь работать с частичными ответами/запросами. Для начала сообщим ядру сервера что мы хотим записать в сокет.
//Формируем тело следующего запроса
function readyDataWriteEvent() {
if (!$this->dataToWrite) {
if ($this->getParams()) {
$str = http_build_query($this->getParams());
$headers = $this->getRequestMethod()." ".$this->getUri()." HTTP/1.0\r\nHost: ".$this->getConnectServer()."\r\n".
"Content-type: application/x-www-form-urlencoded\r\n".
"Content-Length:".strlen($str)."\r\n\r\n";
$this->dataToWrite = $headers;
$this->dataToWrite .= $str;
} else {
$headers = $this->getRequestMethod()." ".$this->getUri()." HTTP/1.0\r\nHost: ".$this->getConnectServer()."\r\n\r\n";
$this->dataToWrite = $headers;
}
return $this->dataToWrite;
} else {
return $this->dataToWrite;
}
}
Теперь пишем запрос, определяя сколько еще осталось.
//Пишем запрос в сокет до того момента, когда полностью запишем его тело
function dataWrittenEvent($count) {
if ($count === false ) {
//socket was reset
$this->jobFinished = true;
} else {
$dataTotalSize = strlen($this->dataToWrite);
if ($count<$dataTotalSize) {
$this->dataToWrite = substr($this->dataToWrite,$count);
$this->setStatus('WRITE_REQUEST');
} else {
//Когда успешно записали запрос в сокет, переходим в режим чтения ответа
$this->setStatus('READ_ANSWER');
}
}
}
После получения запроса, читаем ответ. Важно понять, когда ответ прочитан полностью. Возможно понадобиться установить таймаут на чтение.
//Читаем из сокета до момента, когда полностью прочитаем ответ и совершаем переход в другой статус
function readyDataReadEvent($data)
{
////////// Successfull data read
/////
if ($data) {
$this->body .= $data;
$this->setStatus('READ_ANSWER');
$this->bytesRead += strlen($data);
/////
//////////
} else {
////////// А тут мы уже считали ответ и начинаем его парсить
/////
////////// redirect
if ( preg_match("|\r\nlocation:(.*)\r\n|i",$this->body, $ar_matches) ) {
$url = parse_url(trim($ar_matches[1]));
$this->setStatus('DO_REQUEST');
} else if (...) {
//Так мы сигнализируем ядру сервера, что задание нужно завершить
$this->jobFinished = true;
...
} else if (...) {
$this->setSleepTo(time()+$this->sleepInterval);
$this->sleepInterval *=2;
$this->retryCount--;
$this->setStatus('DO_REQUEST');
}
$this->body = '';
...
В последнем фрагменте кода можно иерархически направлять FSM по заложенной стратегии, реализуя различные варианты работы задания.
Итоги
Решить задачу одновременной работы с сотнями и тысячами заданий и сокетов всего в одном процессе PHP можно просто и лаконично. Если поднять для данного сервера сколько процессов PHP, сколько ядер на сервере, то можно вести речь о тысячах обслуживаемых клиентов. Серверный процесс PHP при этом потребляет всего около 20МБ памяти.
Frontend на nginx+Lua
Frontend на nginx+Lua
Решение технических задач достаточно часто требует нового, незашоренного взгляда на проблему и способы её решения. Рассмотрим пример того, как типичную бэкендовую задачу можно решить с помощью инструментов фронтенда.
Скорость работы сайта - постоянная забота разработчика. И если раньше основное внимание уделялось бэкенду, то в последнее время всё больше приходится смотреть на фронтенд, с точки зрения клиента, для которого есть единственный критерий: как быстро сайт открывается.
В процессе работы над проблемой скорости сайта возникла задача создания сервиса, который будет показывать пользователю работу его сайта, что с его сайтом происходит. Это в конечном счёте было реализовано в виде сервиса Скорость сайта.
В качестве инструмента учёта при решении задачи используется Navigation Timing API, который позволяет на клиентской стороне очень подробно разобрать каждый запрос: на какой этап сколько времени ушло. Инструмент поддерживается всеми современными браузерами, очень удобен и информативен. Его можно в виде простого счётчика встроить на сайт и получить все необходимые данные, обработать их и показать пользователю в виде диаграмм, графиков.
Постановка задачи
Все данные получаемые через Navigation Timing можно собрать, обработать, но куда это сохранить? Сохранить можно клиенту на его сайт, в его локальную базу. Но таким образом решая задачу производительности мы добавляем нагрузку на клиентскую Базу данных. Это неправильно, надо создавать свой собственный сервис, где мы за клиента агрегировали бы эти данные, делали выборки и отдавали клиенту только готовые графики.
Оценивая ориентировочную нагрузку, которая могла лечь на такой сервис, подсчитали:
- сколько примерно клиентов обновиться до последней версии (потенциально - десятки тысяч сайтов),
- среднюю посещаемость проектов,
- максимальную нагрузку (примерно до 1500 хитов в секунду, десятки миллионов хитов день).
Все эти данные нужно сохранить, агрегировать и выдать пользователю.
Сервис требовал решения многих проблем, но сейчас рассмотрим только решение задачи, когда нужно хит от JS скрипта быстро получить, быстро сохранить и сообщить клиенту о том, что данные получены.
Сделать это можно с помощью сервиса Kinesis от Amazon'а. Это - некий большой буфер, задача которого как раз: очень быстро принять некий набор данных, так же быстро сказать пользователю: всё принято. А потом из этого буфера можно любыми воркерами, на любом удобном языке программирования достать, обработать данные и построить на этом какую-то аналитику.
Установка перед Kinesis NGINX и использование его как некий буфер для складирования данных в Kinesis не позволяла решить задачу:
- Обработка большого числа запросов - да, NGINX с этим справится хорошо.
- Сложная логика для идентификации разных клиентов - тоже получается.
- Можно делать всё на GET и POST запросах, чтобы не терять данные со старых браузеров - получается.
- Авторизация на Amazon Web Services, v. 4 - не получается. Чтобы отправить любой запрос в сервис Амазона нужно отправить авторизационный запрос, который выглядит как вложенный 4 или 5 раз, подписанный с помощью SHA 256 набор параметров. Ни один из известных модулей к NGINX не мог решить этой задачи.
Варианты решения:
- NGINX + бэкенд (PHP) - классический бекенд с его недостатками: низкая производительность, расход ресурсов. В этом случае проект будет очень "дорогой", так как производительность такого решения будет не очень большой, следовательно нужно много машин для горизонтального масштабирования.
- NGINX + свой модуль (С/C++) - сложно, долго разрабатывать и тестировать. Плюс - отсутствия аналогичного опыта.
- NGINX + ngx_http_perl_module - блокирующий, так как "модуль экспериментальный, поэтому возможно всё" (из документации к модулю).
- NGINX + ngx_lua - фронтенд?
Решение на бэкенде
Решение на бэкенде: добавить PHP-FPM, написать простой скрипт в несколько строк, который делает нужные запросы и отвечает ровно так как нужно. Это в целом очень неудачное решение, когда для решения простой задачи использовался сложный и тяжёлый инструмент, который расходует много памяти, запросы с него получаются блокирующими (сколько воркеров PHP есть, столько запросов и можно отправить, остальные выстраиваются в очередь.)
Это приемлемый компромисс для невысоконагруженного сервиса, где не идут хиты пачками. Администратор своего проекта может раз в день, раз в неделю эту проверку выполнить. Компромисс на первое время устраивает, но в будущем могут возникнуть ситуации, когда такое решение работать уже не будет, либо потребует дополнительных мощностей, что сделает его достаточно "дорогим".
Решение на фронтенде
Но наше внимание привлёк новый, неизвестный нам модуль Lua. Реально это оказался очень простой инструмент. Кусок кода можно написать прямо в конфиге NGINX'а, либо вынести в отдельный файл и подключить в конфиге NGINX'а. По сути - это некий скриптовый язык, который может реализовать самую сложную кастомную логику. Плюсы Lua:
|  |
Ниже приведён не полный код (базовые функции), который был реализован для проксирования и складывания запросов в Kinesis:
http {
lua_package_cpath "/usr/lib64/crypto.so;;";
server {
location /bx_stat {
lua_need_request_body on;
rewrite_by_lua ‘
local data = ""
if ngx.var.request_method == "POST" then
data = ngx.req.get_body_data()
else
data = ngx.var.query_string;
ngx.req.set_uri_args("");
end
...
local crypto = require "crypto"
local kDate = crypto.hmac.digest("sha256", date_short, "AWS4" .. secret_key, true)
...
ngx.req.set_header("x-amz-date", date_long)
ngx.req.set_header("Authorization", "AWS4-HMAC-SHA256 Credential= ...
‘;
proxy_set_header Host kinesis.eu-west-1.amazonaws.com;
proxy_pass https://kinesis.eu-west-1.amazonaws.com/;
В коде подключается внешняя библиотека для реализации функции шифрования, отбираются параметры, которыми подписывается запрос, генерируется собственно авторизационный запрос в Kinesis, указывается куда дальше проксируется запрос (на амазоновский хост). Так можно избавится от бэкенда и всю логику реализовать на фронтенде.
Требуется при этом произвести дополнительные настройки на стороне NGINX'а:
worker_processes 4;
events {
worker_connections 10240;
}
worker_rlimit_nofile 100000;
proxy_hide_header Access-Control-Expose-Headers;
proxy_hide_header x-amz-id-2;
proxy_hide_header x-amzn-RequestId;
proxy_hide_header Content-Type;
proxy_method POST;
Так как запросов много, то изменено число коннектов, обрабатываемых одним воркером, оцениваем сколько нам нужно будет открытых файлов и открытых соединений. Убраны заголовки из ответа, чтобы не было видно, что данные отправляются в Амазон. И установлено, что данные отправляются в Kinesis через POST, так как он принимает данные только так.
Так как реально тестирование началось с 1000 хитов в секунду, то пришлось настраивать параметры сети в операционной системе. Эти параметры по умолчанию в Linux стоят очень скромные, не ориентированные под высокую нагрузку, и почти всегда приходится их перенастраивать.
В описываемом случае очень быстро закончился диапазон портов исходящих соединений. С помощью файла /var/log/messages можно легко отследить что происходит с сетью и изменить параметры под потребности. Вот результат настроек, после которых всё заработало как это требовалось:
/etc/sysctl.conf (man sysctl) # диапазон портов исходящих коннектов net.ipv4.ip_local_port_range=1024 65535 # повторное использование TIME_WAIT сокетов net.ipv4.tcp_tw_reuse=1 # время пребывания сокета в FIN_WAIT_2 net.ipv4.tcp_fin_timeout=15 # размер таблиц файрволла net.netfilter.nf_conntrack_max=1048576 # длина очереди входящих пакетов на интерфейсе net.core.netdev_max_backlog=50000 # количество возможных подключений к сокету net.core.somaxconn=81920 # не посылать syncookies на SYN запросы net.ipv4.tcp_syncookies=0
По результатам начальной работы потребовались дополнительные настройки: по логу Kinesis'а стало заметно, что всё ломается на 1000 хитов. Оказалось, что фронтенд со всем справлялся, но, несмотря на то, что увеличен диапазон исходящих портов, их всё равно не хватает. Помогло то, что Kinesis поддерживает keepalive соединения, и то, что NGINX тоже поддерживает эти соединения на бэкенде. Мы в proxy_pass прописали не один конкретный хост, а прописали upstream, в котором указали нужный хост, а через keepalive прописали сколько соединений держать открытыми и не закрывать.
upstream kinesis {
server kinesis.eu-west-1.amazonaws.com:443 max_fails=0 fail_timeout=10s;
keepalive 1024;
}
proxy_pass https://kinesis/;
proxy_http_version 1.1;
proxy_set_header Connection "";
На изучение и разработку всего этого ушло не более недели в режиме не полной занятости.
На чём работает
Всё реально заработало на виртуальной машине с 2-я ядрами и 4-мя Гб оперативной памяти, совершенно спокойно обрабатывая нагрузку. Для локализации failover надо просто добавить вторую машину, что сделать очень просто, так как там нечему падать: там нет базы данных, нет нагрузки на диски. Можно также быстро, при необходимости отмасштабировать, поставив сколько нужно машин с балансировщиком.
Использование Lua в других решениях
Решение этой проблемы позволило решить и другие задачи, позволяющие отвязаться от структуры Амазона и увеличить одновременно, скорость доступа для клиентов Битрикс24. В сервисе всё работает хорошо, но RTT не ускорить, если сервера в Ирландии или в США, а клиент в России.
Решение было таким: поставить балансировщик в России, который по максимуму запросы клиентов обрабатывает сам, то есть отдаёт всю статику. Кроме того Композитный кеш тоже отдаётся с этого же балансировщика. Там же настроен SPDY и так далее. Часть из этого списка решалось стандартными средствами NGINX. Но вот сброс кеша по разным условиям не решался штатным функционалом в NGINX'е.
К этой задаче был применён всё тот же подход с использованием Lua. Можно удалять кеш прямо из файловой системы без всяких подзапросов или чего ещё либо. Задача решалась через header_filter_by_lua - удаление кэша высчитыванием пути к файлам и удалением через Lua os.remove В документации к модулю расписано как хранится кеш (задаётся глубина хранения, высчитывается MD5 от ключа, берётся последний символ, если это вложения 1, 2, 3 уровня). Все пути высчитываются, затем файлики удаляются. Всё сделано на нескольких строчках кода. Мы получил то что хотели:
Дополнительно
Есть библиотека Lua-resty, которая предоставляет интерфейсы для работы с:
- memcached,
- MySQL,
- WebSocket,
- Redis,
- и другим.
То есть можно написать код, который непосредственно из NGINX'а будет соединяться с базой, выполнять запросы и получать ответы. Это можно применять в конфигурациях, в которых есть очень много условий.
